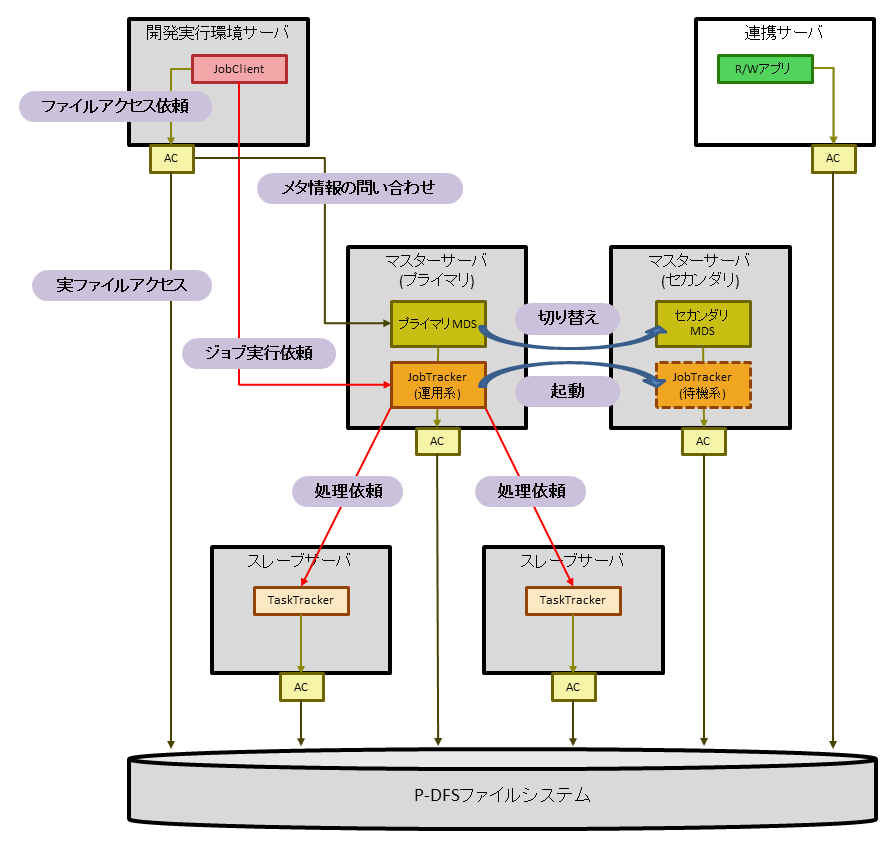
本製品は、複数のサーバ上で動作する複数のサービス・モジュールが協調することで動作します。各サーバが提供するサービスや、必要なモジュールは以下のとおりです。
サービス
サーバ | サービス | 役割 | |
|---|---|---|---|
マスタサーバ (プライマリ) | P-DFS(*1) | プライマリMDS(*2) | DFSのメタデータやAC(*3)を管理します。 |
Hadoop | JobTracker(運用系) | Hadoopジョブの実行依頼を受け付け、各スレーブサーバのTaskTrackerに処理を分散して依頼します。 | |
マスタサーバ (セカンダリ) | P-DFS(*1) | セカンダリMDS(*2) | プライマリMDSのダウンを検知し、新たなプライマリMDSとして処理を引き継ぎます。 |
Hadoop | JobTracker(待機系) | マスタサーバ(プライマリ)のJobTrackerがダウンした場合にPRIMECLUSTERから起動され、処理を引き継ぎます。 | |
スレーブサーバ | Hadoop | TaskTracker | JobTrackerから依頼された処理を実行するために、利用者が指定したMapReduceアプリケーションを子プロセスとして起動します。 |
モジュール
サーバ | モジュール | 役割 | |
|---|---|---|---|
マスタサーバ (プライマリ/セカンダリ) | P-DFS(*1) | AC(*3) | DFSの管理に必要な機能と、DFSにアクセスする機能を提供します。 |
スレーブサーバ | P-DFS(*1) | AC(*3) | DFSにアクセスする機能を提供します。 |
連携サーバ | |||
開発実行環境サーバ | P-DFS(*1) | AC(*3) | DFSにアクセスする機能を提供します。 |
Hadoop | JobClient | Hadoopジョブの実行をJobTrackerに依頼します。 | |
(*1) Primesoft Distributed File System
(*2) P-DFSメタデータサーバ
(*3) P-DFSアクセスクライアント
参考
ACは、各サーバのOSに組み込まれたカーネルモジュールです。/etc/fstabにファイルタイプとして"pdfs"が指定されているファイルシステムにアクセスする際に内部的に動作するもので、利用者が意識する必要はありません。ファイルの入出力を行う場合、ACはメタデータをMDSから取得した後、実データにアクセスします。取得したメタデータはACがキャッシュします。