本製品を使用したサーバ構成およびサーバ種別について説明します。
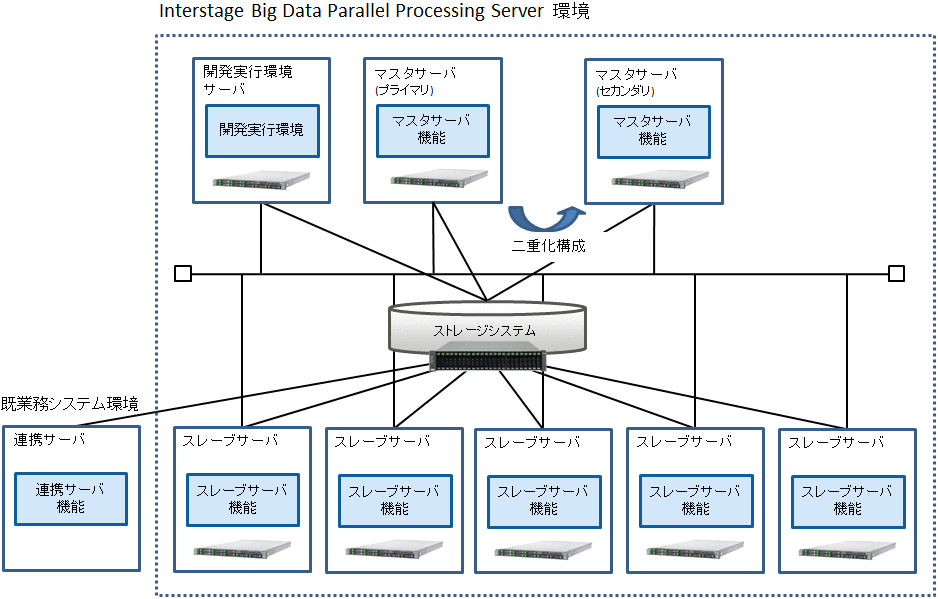
大量のデータファイルをブロックに分けた上でファイル化(分散ファイルシステム)し、そのファイル名や保管場所を一元管理するサーバです。
また、分析処理アプリケーションのジョブの実行要求を受け付け、スレーブサーバに対して並列分散処理を実行させることができます。
本製品では、マスタサーバを二重化構成にすることができます。
マスタサーバには、本製品のマスタサーバ機能を導入します。
マスタサーバによってブロック化されたデータファイルを、複数のスレーブサーバが並列分散処理することによって、短時間に分析処理を行うことができます。
また本製品では、高信頼なストレージシステム上にブロック化したデータを保管します。
スレーブサーバには、本製品のスレーブサーバ機能を導入します。
並列分散を行うアプリケーション(MapReduce)の開発を容易にする Pig や Hive を導入し実行するサーバです。
開発実行環境サーバには、本製品の開発実行環境サーバ機能を導入します。
Apache Hadoop の場合は、分析のために Hadoop の分散ファイルシステムである HDFS にデータを登録する必要がありました。本製品の特長である高信頼なストレージシステム上に構築する DFS(Distributed File System)に対して、Linux 標準のファイルインターフェースを使用して、連携サーバから業務システム上の大量データを直接転送し、分析を行うことができます。
また、連携サーバ上に既存のデータバックアップシステムを導入することで、データのバックアップを容易に利用することができます。
連携サーバには、本製品の連携サーバ機能を導入します。
注意
データ転送によりDFSに格納するデータは、Hadoopを使用して分析を行う分析対象のデータのみとしてください。意図しないI/O競合などの発生によりHadoopの処理に影響を与える可能性があるため、他の用途で使用するデータは格納しないようにしてください。