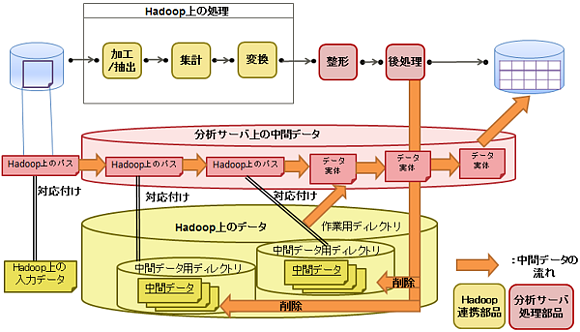
Hadoopと連携した分析フローの設計には、下記の3点に留意してください。
Hadoop上に管理している大規模なデータは、分析サーバにコピーされないようにしてください。Hadoop上で管理しているデータを、分析フロー上で扱うには、Hadoop上のデータのパスを部品の入力/出力データに記述するようにしてください。
Hadoop上に出力する中間データは、分析フロー終了時に削除してください。Hadoop上の作業用ディレクトリを決めて、その中に各分析フローインスタンス/各部品で別名となる、Hadoop上の中間データ用ディレクトリを作成し、中間データを管理してください。また、分析フローの最後に実行される部品で、中間データの削除処理を行ってください。
分析フローの実行中断や、エラー終了に備えて、Hadoop上の中間データ用ディレクトリのパスを、各部品で標準エラー出力に出力してください。Hadoop上の中間データ用ディレクトリのパスを標準エラー出力に出力しておくと、分析フローの実行がエラーとなった場合や分析フローの実行を中断した場合も参照可能なログに格納されます。
想定するユースケース
Hadoop上に管理されているデータを入力データとします。
設計方針
分析サーバ上にファイルを作成して、Hadoop上に存在する入力データのパスを、改行を含まずに1行で記述します。分析フローの入力データとして、このファイルを参照する入力データストアを用意します。このとき、入力データストアのデータ形式には"バイナリデータ"を指定します。
入力データストアの後続には、バイナリ抽出部品と汎用コマンド部品を繋げます。バイナリ抽出部品では、入力データストアで指定されたファイルを読込みます。汎用コマンド部品では、バイナリ抽出部品で読込んだファイルに記述されている、Hadoop上の入力データのパスを読込みます。
この汎用コマンド部品に指定するコマンドの例を以下に示します。
汎用コマンド部品による入力データの参照
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataの場合、Hadoop上に存在する入力データのパス配下にあるファイル一覧を取得するコマンドの例です。
/usr/bin/hadoop fs -ls `cat $input_data$` > $output_data$
想定するユースケース
分析フローの処理途中で発生する中間データを、Hadoop上に格納します。
Hadoop上のデータを入力として、Hadoopアプリケーションで処理した中間データや、分析サーバに存在するデータをHadoop上に転送し、Hadoop上のデータと組み合わせて処理した中間データをHadoop上に格納します。
設計方針
分析サーバが使用する作業用ディレクトリをHadoop上の任意の場所に用意します。
そのHadoop上の作業用ディレクトリ配下に、中間データを書き出すための中間データ用ディレクトリを作成します。中間データ用ディレクトリのパスは、他の分析フローや、同一の分析フローの別実行インスタンスで使用する中間データ用ディレクトリのパスと重複しないようにするため、分析フロー実行時に動的に作成する必要があります。作成方法の詳細については後述します。
Hadoop上に書き出された中間データは、自動的に削除されません。そのため、分析フローの実行が正常終了した場合には、中間データを削除するように、分析フローを設計する必要があります。このとき、中間データが処理されている途中で削除されないよう留意してください。
Hadoop上の中間データは上記に記載した対応を行っても、分析フローの実行がエラー終了した場合や、分析フローの実行を中断した場合に、削除されない可能性があります。そのため、中間データの出力場所を標準エラー出力に出力しておくことをお勧めします。
中間データの出力場所を標準エラー出力に出力しておくと、分析フローの実行がエラーとなった場合や分析フローの実行を中断した場合でも、分析サーバのログから中間データの場所を確認することができます。
汎用コマンド部品による中間データの出力
汎用コマンド部品の入力コネクターから、Hadoop上の入力データのパスが記述されたファイルが渡された時に、HadoopのサンプルであるWordCountを呼び出してHadoop上の入力データを処理し、その出力結果をHadoop上の中間データ用ディレクトリに出力する例について説明します。
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリのパス、hadoop_examples_jarにhadoop-examplesのjarファイルのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/exec_hadoop_wc.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $hadoop_examples_jar$ `cat $input_data$` $output_data$
上記のコマンドでは、シェルスクリプト(exec_hadoop_wc.sh)の引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス(この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. hadoop-exampleのjarファイルのパス、5. 入力データのパス、6. 出力データのパスを指定しています。
シェルスクリプト(exec_hadoop_wc.sh)の内容は、以下のようになります。
引数で渡された分析サーバ上の作業用ディレクトリのパスから、分析フローのインスタンスIDと部品のインスタンスIDを取得して、それを"_"(アンダースコア)で連結することで、Hadoop上の中間データ用ディレクトリのパスを動的に作成しています。
分析フローの実行中断や、コマンドの実行エラーが起きた際には、Hadoop上の中間データ用ディレクトリを削除する必要があるため、Hadoop上の中間データ用ディレクトリのパスを標準エラーに出力しています。標準エラーに出力した内容は、分析フローエディタから、ログのダウンロードを行うことにより、参照できます。
その後、Hadoop上でWordCountの処理を行い、出力結果をHadoop上の中間データ用ディレクトリに出力しています。
最後にHadoop上の中間データ用ディレクトリのパスが記述されたファイルを、分析サーバ上の中間データとして出力しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. hadoop-exampleのjarファイルへのパス
HADOOP_EXAMPLES_JAR=${4}
# 5. 入力データのパス
input_data=${5}
# 6. 出力データのパス
output_data=${6}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の中間データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_WORK_DIR=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の中間データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_WORK_DIR=${HADOOP_WORK_DIR}" >&2
## Hadoop上で処理を行う
${HADOOP_PATH} jar ${HADOOP_EXAMPLES_JAR} wordcount ${input_data} ${HADOOP_WORK_DIR}
HADOOP_RESULT=$?
## Hadoop上の中間データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_WORK_DIR} > ${output_data}
exit ${HADOOP_RESULT}汎用コマンド部品による中間データの削除
中間データを削除するコマンドの例について説明します。「汎用コマンド部品による中間データの出力」では、分析フローのインスタンスIDと部品のインスタンスIDを活用して、重複しないパスを生成する方法を説明しました。この方法を前提とした場合、分析フローのインスタンスIDから始まるディレクトリを、分析フローの終了時に一括削除することで、中間データを漏れなく削除できます。
分析フローの例として、単純なフローの場合、分岐があるフローの場合を例示します。どちらの場合も、すべての処理が終了した後に、中間データを削除しています。
単純なフローの場合
分析フロー実行の最後に削除コマンドを実行します。フロー上の配置は下記の図のとおりです。
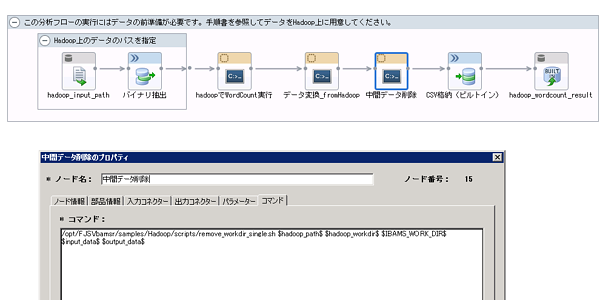
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/remove_workdir_single.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $input_data$ $output_data$
上記のコマンドでは、シェルスクリプト(remove_workdir_single.sh)に引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス (この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. 入力データのパス、5. 出力データのパスを指定しています。
シェルスクリプト(remove_workdir_single.sh)の内容は、以下のようになります。
引数で渡された分析サーバ上の作業用ディレクトリのパスから分析フローのインスタンスIDを取得し、分析フローのインスタンスIDに"_"(アンダースコア)と"*"を連結することで、分析フローのインスタンスIDに合致するすべての中間データを削除しています。
その後、入力データをそのまま分析サーバ上の中間データとして出力しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 入力データのパス
input_data=${4}
# 5. 出力データのパス
output_data=${5}
## Hadoop上の中間データ用ディレクトリ(分析フローインスタンス単位)を取得
HADOOP_WORK_DIR_FLOW=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2) }'`_*
## Hadoop上の中間データ用ディレクトリ(分析フローインスタンス単位)を削除し、結果をログに出力
${HADOOP_PATH} fs -rmr ${HADOOP_WORK_DIR_FLOW} >&2
HADOOP_RESULT=$?
## 入力データを分析サーバ上の中間データに出力
cp ${input_data} ${output_data}
exit ${HADOOP_RESULT}分岐を含むフローの場合
Hadoop上から分析サーバ上にデータを転送後、削除コマンドを実行するよう、フロー上に配置しています。フロー上の配置は以下のとおりです。
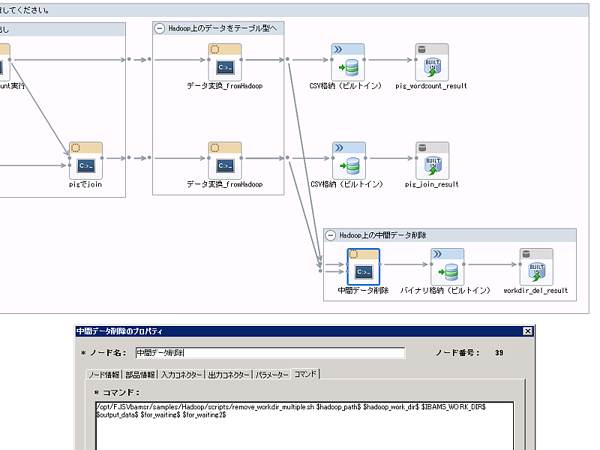
入力コネクターが2つ、出力コネクターが1つ存在し、入力コネクターの変数名がfor_waitingとfor_waiting2、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/remove_workdir_multiple.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $output_data$ $for_waiting$ $for_waiting2$
上記のコマンドでは、シェルスクリプト(remove_workdir_multiple.sh)の引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス(この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. 出力データのパス、5. 1つ目の入力データのパス、6. 2つ目の入力データのパスを指定しています。
シェルスクリプト(remove_workdir_multiple.sh)の内容は以下のようになります。
引数で渡された分析サーバ上の作業用ディレクトリのパスから分析フローのインスタンスIDを取得し、分析フローのインスタンスIDに"_"(アンダースコア)と"*"を連結することで、分析フローのインスタンスIDに合致するすべての中間データを削除しています。
その後、削除結果を分析サーバ上の中間データとして出力しています。
なお、部品実行の待ち合わせ用に使用している入力コネクターを、コマンド中に記載する必要があるため、5番目以降の引数として入力コネクター名を記載していますが、シェルスクリプトの中では使用していません。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 出力データのパス
output_data=${4}
## Hadoop上の中間データ用ディレクトリ(分析フローインスタンス単位)を取得
HADOOP_WORK_DIR_FLOW=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2) }'`_*
## Hadoop上の中間データ用ディレクトリ(分析フローインスタンス単位)を削除し、結果を分析サーバ上の中間データに出力
${HADOOP_PATH} fs -rmr ${HADOOP_WORK_DIR_FLOW} > ${output_data}
HADOOP_RESULT=$?
exit ${HADOOP_RESULT}想定するユースケース
分析フローの処理結果を、Hadoop上に出力します。出力結果を、Hadoopと連携した別のアプリケーションやシステムの入力として活用する場合に利用します。
設計方針
Hadoop上の任意の場所に出力データを格納するための親ディレクトリを用意します。その親ディレクトリ配下に、分析フローの処理結果を書きだすための出力データ用ディレクトリを作成します。出力データ用ディレクトリのパスは、他の分析フローや、同一の分析フローの別実行インスタンスで使用する出力データ用ディレクトリのパスと重複しないようにするため、分析フロー実行時に動的に作成する必要があります。作成方法の詳細については後述します。
汎用コマンド部品による出力データの格納
汎用コマンド部品の入力コネクターから、Hadoop上の入力データのパスが記述されたファイルが渡された時に、そのデータをHadoop上の任意のディレクトリ配下に出力する例について説明します。
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の出力データを格納するための親ディレクトリのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/output_hadoop.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ `cat $input_data$` $output_data$
上記のコマンドでは、シェルスクリプト(output_hadoop.sh)の引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の出力データを格納するための親ディレクトリのパス(この例では、/user/ibamsservice/ibams_outputを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. 入力データのパス、5. 出力データのパスを指定します。
シェルスクリプト(output_hadoop.sh)の内容は、以下のようになります。
引数で渡された分析サーバ上の作業用ディレクトリのパスから、分析フローのインスタンスIDと部品のインスタンスIDを取得し、それを"_"(アンダースコア)で連結して、Hadoop上の出力データを格納するための親ディレクトリのパスに繋げることで、出力データ用ディレクトリのパスを動的に作成しています。
分析フローの実行中断や、コマンドの実行エラーが起きた際には、Hadoop上の出力データ用ディレクトリを削除する必要があるため、Hadoop上の出力データ用ディレクトリのパスを、標準エラーに出力しています。標準エラーに出力した内容は、分析フローエディタから、ログのダウンロードを行うことにより、参照できます。
その後、Hadoop上の入力データを出力データ用ディレクトリに格納しています。
最後に、Hadoop上の出力データ用ディレクトリのパスが記述されたファイルを、分析サーバ上の中間データとして出力しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の出力データを格納するための親ディレクトリのパス
HADOOP_OUT_DIR_ROOT=${1}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 入力データのパス
input_data=${4}
# 5. 出力データのパス
output_data=${5}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の出力データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_OUT_DIR=${HADOOP_OUT_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の出力データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_OUT_DIR=${HADOOP_OUT_DIR}" >&2
## Hadoop上で処理を行う
${HADOOP_PATH} fs -cp ${input_data} ${HADOOP_OUT_DIR}
HADOOP_RESULT=$?
## Hadoop上の出力データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_OUT_DIR} > ${output_data}
exit ${HADOOP_RESULT}Hadoop連携を行う分析フローで、分析サーバ上のデータをHadoop上に転送、および、Hadoop上のデータを分析サーバ上に転送する方法について記載します。
想定するユースケース
データベースやCSVの形式でマスターデータが存在し、ビッグデータのトランザクションデータがあるような場合に、pigスクリプトで、JOINステートメントなどを活用する使い方を想定します。
設計方針
分析サーバが使用する作業用ディレクトリをHadoop上の任意の場所に用意します。
そのHadoop上の作業用ディレクトリ配下に、分析サーバ上のテーブル型のデータからヘッダー行を取り除いたデータを格納します。
汎用コマンド部品によるデータ転送および変換
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/copy_to_hadoop.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $input_data$ $output_data$
上記のコマンドでは、シェルスクリプト(copy_to_hadoop.sh)の引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス(この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. 入力データのパス、5. 出力データのパスを指定しています。
シェルスクリプト(copy_to_hadoop.sh)の内容は以下のようになります。
Hadoop上の中間データ用ディレクトリを作成しています。
Hadoop上では、ヘッダー行が含まれているテーブル型のデータを処理することができないため、ヘッダー行を削除しています。下記では、分析サーバ上の中間データに一時的に書き込んでいますが、衝突しないファイル名であれば別のファイルに書き込んでもでも構いません。
その後、ヘッダー行を削除したファイルを、Hadoop上の中間データ用ディレクトリにコピーしています。
最後に、その中間データ用ディレクトリのパスが記述されたファイルを、分析サーバ上の中間データとして出力しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 入力データのパス
input_data=${4}
# 5. 出力データのパス
output_data=${5}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の中間データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_WORK_DIR=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の中間データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_WORK_DIR=${HADOOP_WORK_DIR}" >&2
## ヘッダー行の削除
sed -e "1d" ${input_data} > ${output_data}
## Hadoop上にコピー
${HADOOP_PATH} fs -copyFromLocal ${output_data} ${HADOOP_WORK_DIR}
HADOOP_RESULT=$?
## Hadoop上の中間データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_WORK_DIR} > ${output_data}
exit ${HADOOP_RESULT}想定するユースケース
Hadoop上でビッグデータを加工/分析し、必要なデータに絞り込んだ構造化データを、汎用Rスクリプト部品や汎用SQL部品の処理と組み合わせる使い方を想定しています。
設計方針
Hadoop上のデータを取得し、ヘッダー行を付与して分析サーバ上の中間データとして出力します。
汎用コマンド部品によるデータ転送および変換
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、header_namesにヘッダー行に指定するカンマ区切りの項目名の文字列が指定されます。ヘッダー行に指定するカンマ区切りの項目名の文字列のデータ形式については、“部品リファレンス”の(テーブル型で扱えるデータの形式)を参照してください。
/opt/FJSVbamsr/samples/Hadoop/scripts/copy_from_hadoop.sh $hadoop_path$ $$header_names$$ $input_data$ $output_data$
上記のコマンドでは、シェルスクリプト(copy_from_hadoop.sh)の引数として、1. hadoopコマンドの絶対パス、2. 項目名の文字列が記述されたファイル、3. 入力データのパス、4. 出力データのパスを指定しています。
シェルスクリプト(copy_from_hadoop.sh)の内容は以下のようになります。
ヘッダー行を分析サーバ上の中間データに出力します。区切り文字をタブからカンマに置換したHadoop上のデータを、分析サーバ上の中間データに続けて出力します。ただし、Hadoop上で区切り文字がカンマとしたデータの場合は、置換の必要はありません。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. 項目名が格納されたファイル
HEADER_NAMES_FILE=${2}
# 3. 入力データのパス
input_data=${3}
# 4. 出力データのパス
output_data=${4}
## ヘッダー行の出力
echo `cat ${HEADER_NAMES_FILE}` > ${output_data}
## データの出力
${HADOOP_PATH} fs -cat `cat ${input_data}`/part* | /bin/sed -e "s/\t/,/" >> ${output_data}
HADOOP_RESULT=$?
exit ${HADOOP_RESULT}想定するユースケース
Interstage Big Data Parallel Processing Serverの独自分散ファイルシステム(DFS)により、分析サーバ上とHadoop上で、大量データをコピーせずに共有します。
設計方針
HadoopインターフェースとPOSIXインターフェースのファイル共有機能を用いて、分析サーバ上とHadoop上のパスを対応付けることで、大量データをコピーせずに共有します。
汎用コマンド部品によるデータ共有
分析サーバ上のテーブル型のデータをHadoop上に転送する場合
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはpdfs_mappingに独自分散ファイルシステム(DFS)のマウントポイントとHadoopトップディレクトリを連結したパス、hadoop_work_dirにHadoop上の作業用ディレクトリが指定されます。
/opt/FJSVbamsr/samples/Hadoop/script/pdfs_to_hadoop.sh $pdfs_mapping$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $input_data$ $output_data$
上記のコマンドでは、シェルスクリプト(pdfs_to_hadoop.sh)の引数として、1. 独自分散ファイルシステム(DFS)のマウントポイントとHadoopトップディレクトリを連結したパス、2. Hadoop上の作業用ディレクトリのパス(この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバ上の作業用ディレクトリのパス、4. 入力データのパス、5. 出力データのパスを指定します。
シェルスクリプト(pdfs_to_hadoop.sh)の内容は以下のようになります。
Hadoop上の中間データ用ディレクトリを作成しています。独自分散ファイルシステム(DFS)のファイル共有機能を活用しているため、POSIXインターフェースのパスを用いて、通常のコマンドで作成しています。
Hadoop上では、ヘッダー行が含まれているテーブル型のデータを処理することができないため、ヘッダー行を削除しています。下記では、分析サーバ上の中間データに一時的に書き込んでいますが、衝突しないファイル名であれば別のファイルに書き込んでもでも構いません。
その後、ヘッダー行を削除したファイルを、Hadoop上の中間データ用ディレクトリにコピーしています。
最後に、その中間データ用ディレクトリのパスが記述されたファイルを、分析サーバ上の中間データとして出力しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. PDFSマウントポイントとHadoopトップディレクトリを連結したパス
PDFS_MAPPING=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 入力データのパス
input_data=${4}
# 5. 出力データのパス
output_data=${5}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の中間データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_WORK_DIR=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の中間データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_WORK_DIR=${HADOOP_WORK_DIR}" >&2
## 出力データのパス(Hadoopインターフェース)と対応したPOSIXインターフェースのパスを算出
POSIX_WORK_DIR=${PDFS_MAPPING}${HADOOP_WORK_DIR}
mkdir -p ${POSIX_WORK_DIR}
## ヘッダー行の削除
sed -e "1d" ${input_data} > ${POSIX_WORK_DIR}/`echo ${output_data} | awk -F"/" '{ printf $NF }'`
RESULT=$?
## Hadoop上の中間データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_WORK_DIR} > ${output_data}
exit ${RESULT}Hadoop上の中間データを分析サーバ上に転送する場合
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはpdfs_mappingに独自分散ファイルシステム(DFS)のマウントポイントとHadoopトップディレクトリを連結したパス、header_namesにヘッダー行に指定する1行分のカンマ区切りの項目名の文字列が指定されます。ヘッダー行に指定するカンマ区切りの項目名の文字列のデータ形式については、“部品リファレンス”の(テーブル型で扱えるデータの形式)を参照してください。
/opt/FJSVbamsr/samples/Hadoop/scripts/pdfs_from_hadoop.sh $pdfs_mapping$ $$header_names$$ $input_data$ $output_data$
上記のコマンドでは、シェルスクリプト(pdfs_from_hadoop.sh)の引数として、1. PDFSマウントポイントとHadoopトップディレクトリを連結したパス、2. 項目名が格納されたファイル、3. 入力データのパス、4. 出力データのパスを指定しています。
シェルスクリプト(pdfs_from_hadoop.sh)の内容は以下のようになります。
ヘッダー行を分析サーバ上の中間データに出力します。区切り文字をタブからカンマに置換したHadoop上のデータを、分析サーバ上の中間データに続けて出力します。ただし、Hadoop上で区切り文字がカンマとしたデータの場合は、置換の必要はありません。独自分散ファイルシステム(DFS)のファイル共有機能を活用しているため、POSIXインターフェースのパスを用いて、通常のコマンドで作成しています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. PDFSマウントポイントとHadoopトップディレクトリを連結したパス
PDFS_MAPPING=${1}
# 2. 項目名が格納されたファイル
HEADER_NAMES_FILE=${2}
# 3. 入力データのパス
input_data=${3}
# 4. 出力データのパス
output_data=${4}
## 入力データのパス(Hadoopインターフェース)と対応したPOSIXインターフェースのパスを算出
POSIX_WORK_DIR=${PDFS_MAPPING}`cat ${input_data}`
## ヘッダー行の出力
echo `cat ${HEADER_NAMES_FILE}` > ${output_data}
## データの出力
cat ${POSIX_WORK_DIR}/part* | sed -e "s/\t/,/" >> ${output_data}
RESULT=$?
exit ${RESULT}想定するユースケース
HadoopのMapReduceアプリケーションを呼び出し、ビッグデータの加工や分析を行います。
汎用コマンド部品によるMapReduceアプリケーションの実行
入力コネクターと出力コネクターが1つずつ存在し、入力コネクターの変数名がinput_data、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはhadoop_pathにhadoopコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリのパス、hadoop_examples_jarにhadoop-examplesのjarファイルのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/exec_hadoop_wc.sh $hadoop_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ $hadoop_examples_jar$ `cat $input_data$` $output_data$
上記のコマンドでは、シェルスクリプト(exec_hadoop_wc.sh)の引数として、1. hadoopコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス(この例では、/user/ibamsservice/ibams_workを用意しています)、3. 分析サーバの作業用ディレクトリのパス、4. hadoop-exampleのjarファイルのパス、5. 入力データのパス、6. 出力データのパスを指定しています。
シェルスクリプト(exec_hadoop_wc.sh)の内容は、以下のようになります。
Hadoop上の中間データ用ディレクトリを作成後、hadoop jar [jarファイル名]のコマンドを呼び出し、処理を行っています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. hadoopコマンドの絶対パス
HADOOP_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. hadoop-exampleのjarファイルのパス
HADOOP_EXAMPLES_JAR=${4}
# 5. 入力データのパス
input_data=${5}
# 6. 出力データのパス
output_data=${6}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の中間データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_WORK_DIR=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の中間データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_WORK_DIR=${HADOOP_WORK_DIR}" >&2
## Hadoop上で処理を行う
${HADOOP_PATH} jar ${HADOOP_EXAMPLES_JAR} wordcount ${input_data} ${HADOOP_WORK_DIR}
HADOOP_RESULT=$?
## Hadoop上の中間データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_WORK_DIR} > ${output_data}
exit ${HADOOP_RESULT}想定するユースケース
pigスクリプトを実行し、ビッグデータの加工や分析を行います。
汎用コマンド部品によるpigスクリプトの実行
入力コネクターが2つ、出力コネクターが1つ存在し、入力コネクターの変数名がinput_dataおよびinput_data2、出力コネクターの変数名がoutput_dataとします。また、パラメーターにはpig_pathにpigコマンドの絶対パス、hadoop_work_dirにHadoop上の作業用ディレクトリのパスが指定されます。
/opt/FJSVbamsr/samples/Hadoop/scripts/exec_pig_join.sh $pig_path$ $hadoop_work_dir$ $IBAMS_WORK_DIR$ `cat $input_data$` `cat $input_data2$` $output_data$
上記のコマンドでは、シェルスクリプト(exec_pig_join.sh)の引数として、1. pigコマンドの絶対パス、2. Hadoop上の作業用ディレクトリのパス (この例では、/user/ibamsservice/ibams_workを用意します)、3. 分析サーバ上の作業用ディレクトリのパス、4. 入力データ1のパス、5. 入力データ2のパス、6. 出力データのパスを指定しています。
シェルスクリプト(exec_pig_join.sh)の内容は、以下のようになります。
Hadoop上の中間データ用ディレクトリを作成後、スクリプトファイルとパラメーターを指定してpigコマンドを呼び出し、処理を行っています。
#!/bin/bash
## 実行に必要なパラメーターの取得
# 1. pigコマンドの絶対パス
PIG_PATH=${1}
# 2. Hadoop上の作業用ディレクトリのパス
HADOOP_WORK_DIR_ROOT=${2}
# 3. 分析サーバ上の作業用ディレクトリのパス
IBAMS_WORK_DIR=${3}
# 4. 入力データのパス
input_data=${4}
# 5. 入力データのパス
input_data2=${5}
# 6. 出力データのパス
output_data=${6}
## Hadoop上で処理を行うための準備
# 1. Hadoop上の中間データ用ディレクトリを決定(分析フローのインスタンスIDと部品のインスタンスIDを取得)
HADOOP_WORK_DIR=${HADOOP_WORK_DIR_ROOT}/`echo ${IBAMS_WORK_DIR} | awk -F"/" '{ printf $(NF-2); printf "_"; printf $(NF-1) }'`
# 2. Hadoop上の中間データ用ディレクトリをログに残すために、標準エラーに出力
echo "HADOOP_WORK_DIR=${HADOOP_WORK_DIR}" >&2
## Hadoop上で処理を行う
${PIG_PATH} -param INPUT_FILE1=${input_data} -param INPUT_FILE2=${input_data2} -param OUTPUT_FILE1=${HADOOP_WORK_DIR} /opt/FJSVbamsr/samples/Hadoop/scripts/pig/join.pig
PIG_RESULT=$?
## Hadoop上の中間データ用ディレクトリのパスを分析サーバ上の中間データに出力
echo ${HADOOP_WORK_DIR} > ${output_data}
exit ${PIG_RESULT}シェルスクリプト(exec_pig_join.sh)から呼び出されるpigスクリプトの内容は以下のようになります。
パラメーターとしてINPUT_FILE1、INPUT_FILE2、OUTPUT_FILE1の2つを受け取り、INPUT_FILE1を単語カウント結果として読み込み、INPUT_FILE2の単語リストに合致した結果のみを、OUTPUT_FILE1にカンマ区切りで出力します。
word_counts = load '$INPUT_FILE1' as (word:chararray, count:int);
word_list = load '$INPUT_FILE2' as (word:chararray);
joined = join word_counts by word, word_list by word;
store joined into '$OUTPUT_FILE1' using PigStorage(',');