A rule definition consists of two types of rules: the filter rules to be used in high-speed filter processing and the complex event processing rules to be used in complex event processing.
This section explains the following items, including considerations when designing rules and the creation procedures to use:
Define the filter rules to be used by the high-speed filter.
Considerations when creating filter rules
The items to consider when creating filter rules are as follows:
Unit of rule creation
Create a filter rule for each event type. Multiple filter rules cannot be defined simultaneously for a certain event type.
Processing pattern of filter rules
Select a suitable processing pattern from the ones described below, and then create a rule similar to the selected pattern.
Refer to Chapter 2, "Filter Rule Language Reference" in the Developer's Reference for information on filter rules.
Master data
Master data is referenced from within filter rules. Some individual events may contain only limited information such as an ID or code in order to cut down on the volume of event communication. Writing rules to process events is difficult in that situation, so it is possible to use master data that can be referenced using the ID or code as a key. Using master data in this way allows rules to be created more easily.
The master data must be created as files in CSV format by the user beforehand.
Refer to "5.4.5 Designing a Master Definition" for information on designing master data.
Memory usage for filter rules
Using filter rules requires a large amount of memory. Refer to "3.3.1.1 Amount of Memory when Using High-speed Filter Rules" and "3.3.1.2 Amount of Memory when Master Data is used by the High-speed Filter" for information on the memory required.
Processing pattern of filter rules
By defining filter rules in the high-speed filter, the user can describe event extraction as well as extraction and join processing in combination with master data. The output of the high-speed filter is used directly as the input of complex event processing.
The processes performed by the high-speed filter are generally represented by the following four patterns and their combinations:
This processing pattern extracts from the input events those events that meet the conditions described in IF-THEN statements in the filter rules.
Consider using this processing pattern if only the events required are to be extracted from massive volumes of events.
Example
Example of an extraction process
This is an example of extracting events using the content of the events (value).
"value > 10" is defined as the extraction condition.
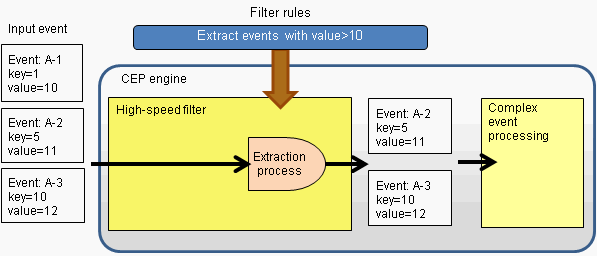
Rule to be created
The rule to be created in the example above is as follows:
on inputEventTypeID {
if ($value > 10) then output() as inputEventTypeID;
}
inputEventTypeID is the development asset ID of the target event type definition.
Information
Filtering the items in the events to be output
Items in the events to be output can also be filtered. Below is an example of outputting only "key" in the example shown above.
To output using a different format from that of the input events, a corresponding event type definition (filtered) will also be required.
Refer to Section 2.7, "Output Expression Format" in the Developer's Reference for details.
on inputEventTypeID {
if ($value > 10) then output($key) as outputEventTypeID;
}
inputEventTypeID is the development asset ID of the target event type definition.
outputEventTypeID is the development asset ID of the event type definition (filtered) that represents the results of filtering the item.
This processing pattern matches the relevant entries of master data (CSV files) on the basis of values such as those of the ID or code contained in the input events, and then extracts the events based on the values of the relevant entries.
Consider using this processing pattern if only the events required are to be extracted from massive volumes of events but the events themselves do not contain the information required for extraction.
To perform the processing of this pattern, a master definition must also be designed.
Example
Example of the extraction process using master data matching
This is an example of referencing the relevant entries of master data based on the "key" contained in the events, and then extracting the events based on the values of "address" in the entries. "address==Fukuoka" is defined as the extraction condition.
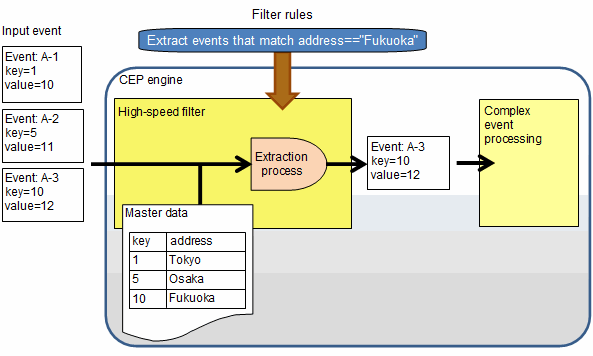
Rule to be created
The rule to be created in the example above is as follows:
on inputEventTypeID {
if (lookup("masterDefinitionID", $key == $key, string($address)) == "Fukuoka") then output() as inputEventTypeID;
}
inputEventTypeID is the development asset ID of the target event type definition.
masterDefinitionID is the development asset ID of the master definition that corresponds to the master data to be referenced.
To compare "$address" as a string, use "string($address)" to fetch the values.
The left side of "$key == $key" is "key" of the input events and the right side is "key" of the master data.
Note
The master data information will not be assigned to the input events if they are only matched using "lookup". If join processing with master data is required, a join expression must be described. Refer to "5.4.4.1.3 Join processing with master data" below for information on join processing.
This processing pattern joins input events with master data. Consider using this processing pattern to assign the required data for the next complex event processing. It enables faster join processing than RDB referencing using complex event processing rules.
To pass the results of joining to complex event processing, an event type definition (filtered) corresponding to the join results will also be required.
Example
Example of join processing with master data
This is an example of joining the corresponding master data on the basis of "key" contained in the events, and then assigning "address" to the events.
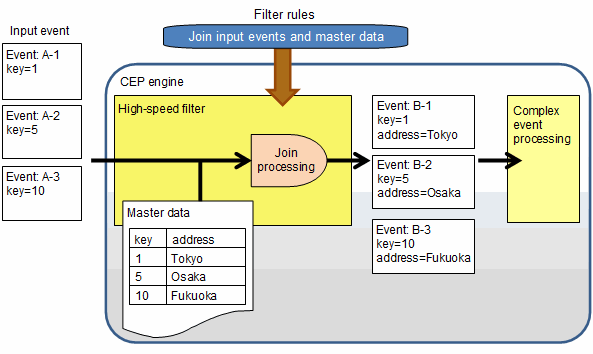
Rule to be created
The rule to be created in the example above is as follows:
on inputEventTypeID {
join("masterDefinitionID", $key == $key) output($key, "masterDefinitionID".$address) as outputEventTypeID;
}
inputEventTypeID is the development asset ID of the event type definition that is the rule target.
masterDefinitionID is the development asset ID of the master definition that corresponds to the master data to be referenced.
outputEventTypeID is the development asset ID of the event type definition (filtered) that represents the results of joining.
This processing pattern can weight the text in input events by registering the weight of the keywords in the master data. This in turn allows applications including those that extract only those events with a total weighting that is above a threshold, and those that detect consecutively issued events that are above a threshold.
Example
Example of weighting processing of text
If the text contained in events contains search words that have been defined in the master data, assign the number of search words it contains as well as the total weighting value set for each search word, and then output them.
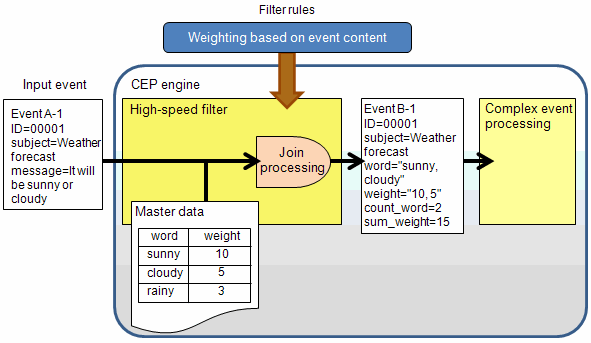
Rule to be created
The rule to be created in the example above is as follows:
on inputEventTypeID {
join("masterDefinitionID", $message = $word)
output($ID,
$subject,
"masterDefinitionID".$word,
"masterDefinitionID".$weight,
lookup_count("masterDefinitionID".$word),
lookup_sum("masterDefinitionID".$weight)) as outputEventTypeID;
}
inputEventTypeID is the development asset ID of the event type definition that is the rule target.
masterDefinitionID is the development asset ID of the master definition that corresponds to the master data to be referenced.
outputEventTypeID is the development asset ID of the event type definition (filtered) that represents the results of joining.
Define the rules to be used by complex event processing.
Considerations when creating complex event processing rules
The items to consider when creating complex event processing rules are as follows:
Unit of rule creation
Create a complex event processing rule for each use application or for each purpose of performing event pattern detection. Decide on a unit of creation in which an event pattern detection described in a certain rule will not affect other rules.
It is also possible to describe multiple processes in one rule definition, but this will create large rule definitions and may lead to reduced maintainability.
For example, if events relating to home electronic equipment are to be processed and the content to be detected varies significantly between domestic appliances and information devices, create the following two rule definitions:
Rule definition to detect patterns in events relating to domestic appliances
Rule definition to detect patterns in events relating to information devices
Referencing external data
Consider whether referencing external data is necessary in event processing. A Terracotta cache and a relational database (RDB) can be used as external data.
Refer to "5.4.4.3 Terracotta Collaboration" for information on referencing a Terracotta cache.
Refer to "5.4.4.4 RDB Collaboration" for information on referencing a relational database.
Whether processing results are to be sent or logged
The processing results of complex event processing rules can be sent to an external Web service using SOAP but they can also be processed using a Java class deployed to a CEP engine, or logged in an event log using logging. Apply the SOAP listener, custom listener, and logging listener, respectively, to the complex event processing rules in these cases.
Refer to "5.4.4.5 SOAP Listener" for information on how to use the SOAP listener.
Refer to "5.4.4.6 Custom Listener" for information on how to use the custom listener.
Refer to "5.4.4.7 Logging Listener" for information on how to use the logging listener.
Rule creation procedure
Design complex event processing rules in stages, without describing statements from the outset, and develop them so that the intended events will be reliably detected. The creation procedure for complex event processing rules is shown below.
Creation procedure for complex event processing rules
This section uses examples to explain the following creation procedure for complex event processing rules:
Consider what is to be achieved by using complex event processing.
Decide on what is to be achieved by using complex event processing. If this is unclear at this point, analyzing the collected events can sometimes clarify this.
Example
Example of a rule
"When someone is home, if rain is likely, recommend using the drying feature of the washing machine."
Consider the events, external data to be referenced, and output content.
Consider the events, the external data for referencing, and the output content required to create the rule. Also consider using a named window for retaining events in memory.
Example
Examples of events, external data, output, and named window
The rule example above uses the following events, external data, output content, and named window:
Events
TV control event
For the household appliance event data sent from the home gateway of each household, the value of the device category property is to be "Television".
Weather forecast event
The forecast is to be represented by the time and weather.
External data
Washing machine model information (whether it has a drying feature)
Whether the washing machine in that household has a drying feature is to be apparent from the home gateway ID.
Output content
Home gateway ID of the household to be given the recommendation
Recommendation details
Named window
Named window for weather forecast events
The weather forecast events for each time are to be retained for one day.
Refine the processing content.
Refine the content of the events and of the complex event processing for detecting them.
Here, "refine" is the task of using events and specific information such as complex event processing conditions and external data to make what was previously expressed in everyday language as "what is to be achieved" into a representation closer to the rule to be created.
Example
Example of refining the content of complex event processing
The table below shows the results of refining the "When someone is home, if rain is likely, recommend using the drying feature of the washing machine" rule.
Element of the rule | Refined processing content |
|---|---|
"When someone is home" | Determine that someone is home in the household where the TV was controlled (detect a TV control notifying event). |
"If rain is likely" | Reference the weather forecast information stored in the named window and, from the time of the weather forecast and the time of the TV control, check whether or not there is a forecast of rain after this time. |
"Drying feature of the washing machine" | Obtain product information on the washing machine connected to the home gateway from the Terracotta cache. |
"Recommend" | If there is a forecast of rain and if the washing machine has no drying feature, recommend hanging the clothes inside the house. If there is a forecast of rain and if the washing machine has a drying feature, recommend using it. |
Create an event flowchart.
After refining the processing content is completed, summarize the event processing flow to create an event flowchart. An event flowchart associates events and their processing content in chart form. Create an event flowchart before describing the processes using complex event processing rule language, as it is useful for checking the processing content to be achieved.
Information
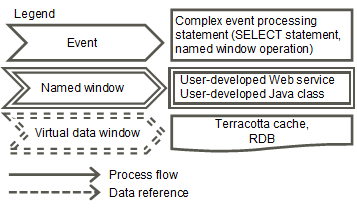
Legend of event flowchart
This is the legend for the event flowcharts to be used in this manual.
Example
Example of an event flowchart
This is an event flowchart for "When someone is home, if rain is likely, recommend using the drying feature of the washing machine".
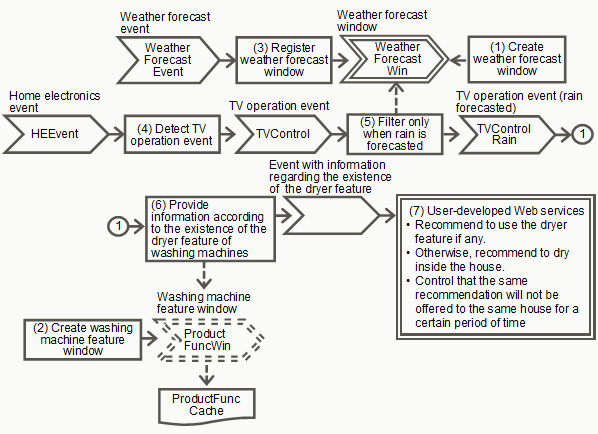
Create a named window for retaining weather forecast events.
Create a Virtual Data Window (Terracotta cache) to see whether the washing machine has a drying feature.
Store weather forecast events in the weather forecast window.
Detect any TV control events from among the household appliance events.
Check the weather forecast from after the time that the TV control events occurred and leave only those events with a forecast of rain.
Search the washing machine feature window for the households for which a TV control was performed and for which there is a weather forecast of rain, and then add recommendation information according to whether the washing machine has a drying feature and send it to the user-developed Web service.
Based on the information received by the user-developed Web service, send a recommendation to the household. Control the user-developed Web service so that the same recommendation is not made to the same household twice within a fixed time period.
Create complex event processing rules.
Describe complex event processing rules that correspond to the respective elements in the event flowchart.
Example
Example of complex event processing rules that correspond to the event flowchart
Refer to Chapter 1, "Complex Event Processing Language Reference" in the Developer's Reference for information on the meanings of rules.
1 | // 1. Create a named window for retaining weather forecast events. |
This section explains considerations when performing Terracotta collaboration, and explains how to use Terracotta collaboration, as follows:
This section explains the items to consider when using Terracotta collaboration for referencing external data in complex event processing, as follows:
Checking the necessity of Terracotta collaboration
Unlike when master data is used by the high-speed filter, Terracotta collaboration allows data that is being continually updated to be referenced. (When the high-speed filter is used, master data can be updated using dynamic change, but it cannot be updated continually from a program).
Data in an external cache can also be added, updated, and deleted when an event occurs.
Structure of the Terracotta cache
Data in the Terracotta cache to be referenced by complex event processing rules is managed as entries where each entry is made up of a key and a value. Refer to "5.5.3 Terracotta Cache" for information on the key-value format used for storing in the cache to be used by complex event processing rules.
Using Terracotta cache
Use the Virtual Data Window feature to use Terracotta cache with complex event processing. Refer to "5.4.4.3.3 Using Terracotta cache" for information on how to create a Virtual Data Window and how to use a cache via the created Virtual Data Window.
To use Virtual Data Window in order to use a Terracotta cache (known as Ehcache), you must place an Ehcache configuration file (ehcache.xml) on the CEP Server. Place the Ehcache configuration file in the following location:
/etc/opt/FJSVcep/config/ehcache.xmlRefer to the Terracotta manual for information on the Ehcache configuration file. The table below explains the settings required for Terracotta Collaboration.
Element or attribute | Description | |||||
|---|---|---|---|---|---|---|
ehcache | Root element of the configuration file. | |||||
name | Specify the name of the cache manager specified when creating the cache. | |||||
maxBytesLocalHeap | Size of the data pool to be used. | |||||
terracottaConfig | Element for defining a Terracotta server. | |||||
url | List of Terracotta servers in the format "hostNameOrIpAddress:portNumber", delimited with a comma (,). | |||||
cache | Element for defining cache. Multiple <cache> elements can be specified in a single <ehcache> element. | |||||
name | Name of the cache. This is the cache name specified using vdw:ehcache. | |||||
terracotta | Defined for using a Terracotta server. | |||||
nonstop | Defined for use as nonstop cache. | |||||
immediateTimeout | Specify whether to respond with a timeout when a network disconnection is detected. Specify "true" as the value. | |||||
timeoutMillis | Specify the standby time until timeout. | |||||
timeoutBehavior | Specify operation to be performed if a timeout occurs. | |||||
type | Specify "exception" as the value. | |||||
searchable | Defined for searching the cache. | |||||
Example
The following example uses the cache "Cache001" configured on two Terracotta servers (192.168.1.1 and 192.168.1.2) using Terracotta collaboration.
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
name="SearchConfig">
maxBytesLocalHeap="64M">
<terracottaConfig url="192.168.1.1:9510,192.168.1.2:9510"/>
<cache name="Cache001">
<terracotta>
<nonstop immediateTimeout="true" timeoutMillis="3000">
<timeoutBehavior type="exception"/>
</nonstop>
</terracotta>
<searchable />
</cache>
</ehcache>
This section explains how to create a Virtual Data Window and how to use the created Virtual Data Window.
Creating a Virtual Data Window
Create a Virtual Data Window (hereafter referred to as a "VDW") within complex event processing rules in order to use a Terracotta cache from the rules.
Specifically, describe this as follows:
Syntax: If an event type ID is used
create window windowName.vdw:ehcache("cacheName","keyPropertyName") as eventTypeID;
Syntax: If type information is specified directly
create window windowName.vdw:ehcache("cacheName","keyPropertyName") as (propertyName type, propertyName type, ...);
Create a VDW using vdw:ehcache() in a CREATE WINDOW statement.
To reference the cache entity, the cacheName and the keyPropertyName for referencing the data must be set. Set them as arguments of vdw:ehcache().
In cacheName, specify the name of the cache to be used.
In keyPropertyName, specify the property name for identifying the entry. If an event type ID is to be used, specify the property name of the specified event type. If type information is to be specified directly, any name can be specified. The type of the specified property must be a type that corresponds to the "Key" class in the cache.
In windowName, specify any name. The name specified here will be used to access the cache from the SELECT statement (INSERT INTO clause, FROM clause), ON SELECT statement, ON UPDATE statement, ON DELETE statement, ON MERGE statement, or subquery in complex event processing rules.
In eventTypeID, specify the event specified in the CSV format event type definition. (An XML format event type definition cannot be specified.)
In propertyName type, the property name and type that corresponds to the "java.util.HashMap" key to be set in "Value" in the cache must be specified. The property name and its type specified in keyPropertyName must also be specified.
If the specified propertyName has not been set in "java.util.HashMap" to be set in "Value" in the cache, it will be treated as a null by the complex event processing rules.
Example
Definition example for creating a Virtual Data Window (VDW)
This is an example of creating a VDW (MarketWindow) to reference a Terracotta cache (MARKET).
create window MarketWindow.vdw:ehcache("MARKET", "code") as (code string, high int, low int);
"code" is specified as a key property.
"code (string type)", "high (int type)", and "low (int type)" are defined as the properties.
Using a Virtual Data Window
Use a created Virtual Data Window in the same way as an ordinary window. However, to access cache data, use an INSERT INTO clause, join that specifies UNIDIRECTIONAL, ON SELECT statement, ON UPDATE statement, ON DELETE statement, ON MERGE statement, or subquery.
Example
Example of using a created Virtual Data Window (VDW)
This example inserts a MarketEvent event into a VDW.
insert into MarketWindow select code, high, low from MarketEvent;
This example references a VDW MarketWindow when a TicketEvent event occurs to obtain the data of the VDW events (cache entries) that meet the condition. This example uses TicketEvent as a trigger, so UNIDIRECTIONAL is specified in TicketEvent for joining the events.
select W.high, W.low from TicketEvent as Input unidirectional, MarketWindow as W
where W.code = Input.code;
This example references a VDW (MarketWindow) when a TicketEvent event occurs to obtain the data of the VDW events (cache entries) that meet the condition. This example uses an ON SELECT statement.
on TicketEvent as Input
select W.high, W.low from MarketWindow as W
where W.code = Input.code;
This example references a VDW (MarketWindow) when a TicketEvent event occurs to obtain the data of the VDW events (cache entries) that meet the condition. This example uses a subquery.
select (select W.high from MarketWindow as W where W.code = Input.code) as high from TicketEvent as Input;
This example updates an event that has the same code in a VDW when a MarketEvent event occurs.
on MarketEvent as New
update MarketWindow as W
set high = New.high, set low = New.low
where W.code = New.code;
Note
Notes on using a Virtual Data Window
Do not specify another view.
Do not specify another view such as win:length(1) at the same time as the vdw:ehcache() specification in a CREATE WINDOW statement that defines a Virtual Data Window. Specifying another view does not cause a syntax error, but the view specification cannot be used to operate Terracotta cache data (even if you specify win:length(1), the number of events in the cache will not be "1").
An INSERT INTO clause is not merely an insertion.
A Terracotta cache holds only one event (cache entry) for the value of a key property. Therefore, if a new event is inserted into a Virtual Data Window using an INSERT INTO clause and the cache already contains an event that has the same key property value, the event is updated using the new event.
Cache entries added outside the CEP engine do not propagate.
For a simple SELECT statement that specifies Virtual Data Window in a FROM clause or a join that does not specify UNIDIRECTIONAL, an event inserted into the Virtual Data Window by the INSERT INTO clause using the complex event processing rules on the same CEP engine propagates. However, an event (cache entry) added from a Terracotta application or a different CEP engine does not propagate. To access cache data, use an ON SELECT statement, a subquery, or a join that specifies UNIDIRECTIONAL.
The following example shows a simple SELECT statement:
select W.high, W.low from MarketWindow;
The following example shows a join that does not specify UNIDIRECTIONAL:
select W.high, W.low from TicketEvent.std:lastevent() as Input, MarketWindow as W
where W.code = Input.code;
If the INSERT INTO clause inserts an event into MarketWindow, the inserted event propagates to the SELECT statements. However, events added outside the CEP engine does not propagate.
A WHERE clause must uniquely identify cache entries.
The WHERE clause, which can be used for accessing information stored in a Virtual Data Window, must contain a condition for uniquely identifying cache entries. This condition uses "=" to perform a comparison with the key property specified using vdw:ehcache(). An example is shown below.
In the following example, W.code = T.code is valid, because it uniquely identifies a cache entry.
create window MarketWindow.vdw:ehcache("MARKET", "code") as (code string, high int, low int);
on TicketEvent as T
select W.high, W.low from MarketWindow as W
where W.code = T.code and ( T.price > W.high or T.price < W.low);
The table below shows valid and invalid definition examples of using the above rule to change the WHERE clause only.
No. | Definition example | Valid/ | Explanation |
|---|---|---|---|
1 | where W.code = '1111' | Valid | Valid because the condition can uniquely identify a cache entry by using "=" to perform a comparison with the key property |
2 | where ( T.price > W.high or T.price < W.low) and W.code = T.code | Valid | Preceded by a different condition but valid because it includes "=" for performing a comparison with the key property and can uniquely identify a cache entry |
3 | where W.high = 1000 | Invalid | Invalid because a comparison using "=" is not performed for the key property. |
4 | where W.code > '1111' | Invalid | Invalid because an operation other than "=" is performed for the key property. |
5 | where W.code = '1111' or W.high = 1000 | Invalid | Includes "=" for performing a comparison with the key property but is invalid because there is an OR condition and a cache entry cannot be uniquely identified |
This section explains the items to consider when implementing RDB collaboration and how to use it.
To reference a relational database as external data, create an RDB reference definition that contains information about connection to the relational database.
This section explains the following items:
The items to consider when using RDB collaboration are as follows:
Creating an RDB collaboration definition
Using RDB collaboration requires an RDB reference definition in addition to a rule definition. Refer to "5.4.7 Designing an RDB Reference Definition" for information on the RDB reference definition.
Contents of the relational database
You must consider the contents of the relational database from the viewpoint of which data, out of the data that cannot be obtained from an input event and the static data that relates to the properties of an event, is also required for checking rules. You can reference RDB data by issuing a complex event processing rule (SELECT statement).
Example
Example of information to be prepared for a relational database
Information that is likely to be required is localities (addresses).
Even if an ID for identifying a customer can be obtained from the contents of an event, the locality (address) of the customer is not always contained in the contents of the event.
In this case, preparing a relational database that registers the relationship between the customer ID and the locality (address) makes it possible to use a customer ID from an event to reference the locality (address) of the customer. The relational database can also be used for processing based on locality (address).
Notes on using multibyte characters
Multibyte characters cannot be used for definition names in a relational database such as table names and table item names to be referenced from the complex event processing language. The same applies to other names such as database names, schema names, and user names specified in an RDB reference definition.
Multibyte characters can be used for item values. In this case, set unicode as the character encoding (or character set) of the relational database. Refer to the manual for the collaboration destination RDB for details.
Use of a time-limited cache
When a relational database is referenced for the first time, a query key and the results are stored in a time-limited cache of the CEP engine. Subsequent RDB referencing using the same key entails obtaining the data from the cache. To use a time-limited cache, you must set a cache retention period and a cache purge interval in the RDB reference definition. Refer to "5.4.7 Designing an RDB Reference Definition" for information on the RDB reference definition.
You can use the results of a query to a relational database by specifying them using the following syntax in a FROM clause of complex event processing rules.
Syntax:
sql:databaseName [" sqlQuery "] or
sql:databaseName [' SqlQuery ']
In databaseName, specify the "development asset ID" specified in the RDB reference definition.
Enclose sqlQuery in double quotation marks (") or single quotation marks ('), and enclose this specification in square brackets "[" and "]".
Alternate parameters can be included in sqlQuery. Specify alternate parameters in the ${expression} format. The expression is evaluated when the statement is executed.
Note
Minimize RDB referencing, because it may cause a decline in the performance of Complex Event Processing.
Multibyte characters cannot be used for definition names in a relational database, such as table names and table item names to be referenced from the complex event processing language. Multibyte characters can be used for item values.
To specify a nonnumeric literal enclosed in single quotation marks (') in an SQL query that is further enclosed in single quotation marks ('), use the escape notation (\') or the Unicode notation (\u0027).
Example
Example of using RDB referencing
This example uses RDB referencing in a complex event processing rule (SELECT statement).
@Name("PutRecommend")
@SoapListener("soap-001")
select tvevnt.gatewayId as gatewayId,
case when db.DRY_FUNC = '1' then 'USE_DRY_FUNC' else 'HANG_LAUNDRY_INSIDE' end as recommendId
from TVControlRain as tvevnt,
sql:app_db[ 'SELECT DRY_FUNC FROM PRODUCTFUNC_TBL WHERE HGW_ID=${tvevnt.gatewayId}' ] as db;
The development asset ID of the RDB reference definition to be used is set to "app_db".
The relational database table being referenced is "PRODUCTFUNC_TBL".
The alternate parameter "${tvevnt.gatewayId}" is specified in the condition for referencing the relational database table.
The alias "db" is assigned to the reference results and is used in a SELECT statement.
Use the SOAP listener to send the processing results of complex event processing statements to a user-developed Web service using SOAP.
To use the SOAP listener, assign the @SoapListener annotation in front of the complex event processing statement (SELECT statement) for which the processing results are to be sent.
Refer to "5.4.8 Designing a SOAP Listener Definition" for information on the send destination of processing results and the contents of SOAP messages.
Syntax
@SoapListener("soapListenerDefinitionId")
complexEventProcessingStatement(selectStatement)
Specify the development asset ID in the SOAP listener definition that defines information such as the URL that is the send destination of the Web service to which the processing results are to be sent.
Specify the complex event processing statement (SELECT statement) for which the processing results are to be sent.
Use the custom listener to pass the results of complex event processing statements to a Java program (hereafter referred to as a user-developed Java class) for processing.
To use the custom listener, assign the @CustomListener annotation in front of the complex event processing statement (SELECT statement) to which you want to pass the processing result.
Refer to "5.6.3 Designing a User-developed Java Class" for information on user-developed Java classes.
Syntax
@CustomListener(mainClass="nameOfUserDevelopedJavaClass" [, args={"argument1", "argument2", ...}])
complexEventProcessingStatement(selectStatement)
Alternatively, the format may use single quotation marks (') instead of double quotation marks (").
Specify the name of the Java class that receives the results of complex event processing statements. Use FQCN format (format that includes the package name) for specifying this name. The CustomListener interface must have been implemented for this Java class.
Specify these arguments for the user-developed Java class. If there is no need to pass arguments, omit the "args" parameter.
Use the logging listener to log the processing results of complex event processing statements in the event log using Logging.
To use the logging listener, assign the @LoggingListener annotation in front of the complex event processing statement (SELECT statement) for which the processing results are to be logged.
Syntax
@LoggingListener(table="logStorageArea", properties="propertyNameToBeOutput")
complexEventProcessingStatement(selectStatement)
Use an absolute path to specify the path in the Hadoop system in which the event log is logged.
Even if events are to be logged in the engine log of the CEP Server (if "file" is specified in the "type" element of the engine configuration file), specify a virtual path name that begins with a slash (/) (for example, /eventName) to identify the events.
Note
The "table" specification is mandatory. Even if a null value is specified, such as 'table=""', the CEP engine will start normally but logging will not be performed.
Out of the processing results of the SELECT statement, specify the property name to be logged. Multiple properties can also be specified if delimited using commas (,).
For a property with nested processing results, use periods (.) between the nested properties to join them.
Example
If a "child" property is nested in a "parent" property
If a "child" property is nested in a "parent" property, as shown below, specify the "child" property by describing "parent.child".
<root>
<parent>
<child>aaa</child>
</parent>
</root>
Note
The "properties" specification is mandatory. Even if a null value is specified, such as 'properties=""', the CEP engine will start normally but logging will not be performed.
Specify the complex event processing statement (SELECT statement) for which the processing results are to be logged using logging.
Note
The logging to be defined in an event type definition and the logging to be defined in a rule definition (logging listener) can have separate log storage areas as output destinations. However, note that logging to a different Hadoop system is not possible.
If the value of the output property is "null", this is converted to a blank space before being output to the event log.
If the output property is a numeric item, this undergoes string conversion before being output to the event log.
If an output property name that does not exist is specified, a blank space is output to the event log.
If there are double quotation marks (") in data, these will be output in duplicate within double quotation marks in the data.
Output example of 'aa"bb"aa':
"aa""bb""aa"