Overview
If heartbeat monitoring fails because of a node failure, PRIMECLUSTER shutdown facility removes the failed node. If this occurs during crash dump collection, you might not be able to acquire information for troubleshooting.
The cluster high-speed failover function prevents node elimination during crash dump collection, and at the same time, enables the ongoing operations on the failed node to be quickly moved to another node.
The crash dump collection facility varies depending on the version of RHEL being used.
Version of Red Hat Enterprise Linux | Crash dump collection facility |
|---|---|
RHEL-AS4.6, RHEL-AS4.7, and RHEL-AS4.8 | Diskdump |
RHEL5.1, RHEL5.2, RHEL5.3, RHEL5.4, and RHEL5.5 | kdump |
Diskdump/kdump
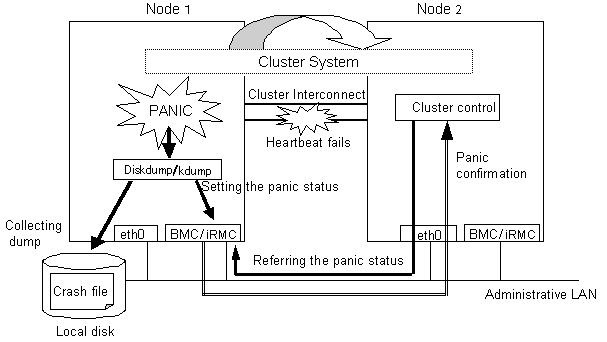
As shown in the above figure, the cluster fast switching function allows for panic status setting and reference through BMC (Baseboard Management Controller) or iRMC when a heartbeat monitoring failure occurs. The node that detects the failure can consider that the other node is stopped and takes over ongoing operation without eliminating the node that is collecting crash dump.
Note
If you reboot the node that is collecting crash dump, collection of the crash dump will fail.
When the node completes collecting the crash dump after it gets panicked, the behavior of the node follows the setting of Diskdump or kdump.
Configure Diskdump
When using Diskdump, it is necessary to configure the Diskdump.
Check Diskdump
Check if the Diskdump is available. If not, enable the Diskdump using the "runlevel(8)" and "chkconfig(8)" commands.
Check the current run level using the "runlevel(8)" command.
Example)
# /sbin/runlevelN 3
The above example shows that the run level is 3.
Check if the Diskdump is available using the "chkconfig(8)" command.
Example)
# /sbin/chkconfig --list diskdumpdiskdump 0:off 1: off 2: off 3: off 4: off 5: off 6: off
The above example shows that the Diskdump of the runlevel 3 is currently off.
If the Diskdump is off, enable it by executing the "chkconfig(8)" command.
# /sbin/chkconfig diskdump onThen, start it by executing the service command.
# /sbin/service diskdump startConfigure kdump
When using kdump, it is necessary to configure the kdump.
Check kdump
Check if the kdump is available. If not, enable the kdump using the "runlevel(8)" and "chkconfig(8)" commands.
Check the current run level using the "runlevel(8)" command.
Example)
# /sbin/runlevelN 3
The above example shows that the run level is 3.
Check if the kdump is available using the "chkconfig(8)" command.
Example)
# /sbin/chkconfig --list kdumpkdump 0:off 1: off 2: off 3: off 4: off 5: off 6: off
The above example shows that the kdump of the runlevel 3 is currently off.
If the kdump is off, enable it by executing the "chkconfig(8)" command.
# /sbin/chkconfig kdump onThen, start it by executing the service command.
# /sbin/service kdump startPrerequisites for the other shutdown agent settings
After you completed configuring the Diskdump shutdown agent or the kdump shutdown agent, set the IPMI (Inteligent Platform Management Interface) or BLADE server.
Information
The IPMI shutdown agent is used with the hardware device in which BMC or iRMC is installed.
Set the following for the IPMI user.
User ID
Password
IP address
For details, see the "User Guide" provided with the hardware and the "ServerView User Guide."
Set the following for the BLADE server:
Install ServerView
Set SNMP community
Set an IP address of the management blade
For details, see the operation manual provided with the hardware and the "ServerView User Guide."
When PRIMEQUEST is used, if an error occurs in one of the nodes of the cluster system, the PRIMECLUSTER shutdown facility uses the two methods described below to detect that error. For details, see "3.3.1.8 PRIMECLUSTER SF" in the "PRIMECLUSTER Concepts Guide".
(1) Node status change detection through MMB units (asynchronous monitoring)
(2) Heartbeat failure between cluster nodes (NSM: node status monitoring) (fixed-cycle monitoring)
Asynchronous monitoring of (1) allows node errors to be detected immediately, and failover occurs at a higher speed than when detected by fixed-cycle monitoring.
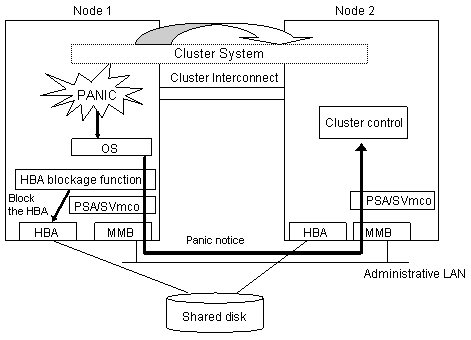
As shown in the above figure, if a panic occurs, the cluster control facility uses the MMB units to receive the panic notice. This allows the system to detect the node panic status faster than it would be a heartbeat failure.
See
PRIMEQUEST allows you to set the panic environment so that a crash dump is collected if a panic occurs.
For details about the PRIMEQUEST dump function, setup method, and confirmation method, refer to the following manuals:
PRIMEQUEST 500/400 Series Installation Manual
PRIMEQUEST 500/400 Series Operation Manual
PRIMEQUEST 500/400 Series Reference Manual: Messages/Logs
PRIMEQUEST 1000 Series Installation Manual
PRIMEQUEST 1000 Series ServerView Mission Critical Option User Manual
To use asynchronous monitoring (1), you must install software that controls the MMB and specify appropriate settings for the driver. This section describes procedures for installing the MMB control software and setting up the driver, which are required for realizing high-speed failover.
Installing the HBA blockage function and the PSA/SVmco
The HBA blockage function and the PSA/SVmco report node status changes through the MMB units to the shutdown facility. Install the HBA blockage function and the PSA/SVmco before setting up the shutdown facility. For installation instructions, refer to the following manuals:
"Attached Driver Guide" that comes with the computer
PRIMEQUEST 500/400 Series Installation Manual
PRIMEQUEST 1000 Series Installation Manual
PRIMEQUEST 1000 Series ServerView Mission Critical Option User Manual
Setting up the PSA/SVmco and the MMB units
The PSA/SVmco and MMB must be set up so that node status changes are reported properly to the shutdown facility through the MMB units. Set up the PSA/SVmco units before setting up the shutdown facility. For setup instructions, refer to the following manuals:
PRIMEQUEST 500/400 Series Installation Manual
PRIMEQUEST 1000 Series Installation Manual
PRIMEQUEST 1000 Series ServerView Mission Critical Option User Manual
You must create an RMCP user so that PRIMECLUSTER can link with the MMB units.
In all PRIMEQUEST instances that make up the PRIMECLUSTER system, be sure to create a user who uses RMCP to control the MMB. To create a user who uses RMCP to control the MMB, log in to MMB Web-UI, and create the user from the "Remote Server Management" window of the "Network Configuration" menu. Create the user as shown below.
Set [Privilege] to "Admin".
Set [Status] to "Enabled".
For details about creating a user who uses RMCP to control the MMB, Refer to "PRIMEQUEST 500/400 Series Reference Manual: Basic Operation /GUI/Commands" and "PRIMEQUEST 1000 Series Tool Reference" provided with the computer.
The user name created here and the specified password are used when the shutdown facility is set up. Record the user name and the password.
Note
The MMB units have two types of users:
User who controls all MMB units
User who uses RMCP to control the MMB
The user created here is the user who uses RMCP to control the MMB. Be sure to create the correct type of user.
Setting up the HBA blockage function
Note
Be sure to carry out this setup when using shared disks.
If a panic occurs, the HBA units that are connected to the shared disks are closed, and I/O processing to the shared disk is terminated. This operation maintains data consistency in the shared disk and enables high-speed failover.
On all nodes, specify the device paths of the shared disks (GDS device paths if GDS is being used) in the HBA blockage function command, and add the shared disks as targets for which the HBA function is to be stopped. If GDS is being used, perform this setup after completing the GDS setup. For setup instructions, see the "Attached Driver Guide" that comes with the computer.
Setting the I/O completion wait time
To maintain consistent I/O processing to the shared disk if a node failure (panic, etc.) occurs and failover takes place, some shared disk units require a fixed I/O completion wait time, which is the duration after a node failure occurs until the new operation node starts operating.
The initial value of the I/O completion wait time is set to 0 second. However, change the value to an appropriate value if you are using shared disk units that require an I/O completion wait time.
Information
ETERNUS Disk storage systems do not require an I/O completion wait time. Therefore, this setting is not required.
Specify this setting after completing the CF setup. For setting instructions, see "Setting the I/O Completion Wait Time".
Note
If an I/O completion wait time is set, the failover time when a node failure (panic, etc.) occurs increases by that amount of time.