If an error occurs on the primary master server, operations will switch to the secondary master server as shown below in accordance with the environment where the master server is installed.
Error details | Installation environment | ||||
|---|---|---|---|---|---|
Physical environment | Virtual environment | Virtual environment | |||
KVM | VMware | KVM | VMware | ||
System error (physical machine) | Y1 | N | N | N (*1) | Y1 |
System error (virtual machine) | N | Y1 | Y1 | Y1 | Y1 |
Public LAN network error | Y1 | Y1 | Y1 | Y1 | Y1 |
Cluster interconnect (CIP) error | Y2 | Y2 | Y2 (*1) | Y2 | Y2 (*1) |
iSCSI network error | Y1 | Y1 | Y1 | Y1 | Y1 |
JobTracker error | Y1 | Y1 | Y1 | Y1 | Y1 |
Y1: Switches to the secondary master server.
Y2: Continues tasks on the primary master server (switch not required).
N: Does not switch to the secondary master server.
*1: The secondary master server must also be forcibly stopped separately.
Note
If an error occurs on the secondary master server, there will be no switch to the primary master server. Tasks can continue without the need to re-execute tasks on the primary master server.
In this situation, investigate and remove the cause of the error on the secondary master server by referring to the system log. After the secondary master server has fully recovered, restart the secondary master server.
If the primary master server and the secondary master server are both installed on each virtual machine on the same host machine, tasks will stop if an error occurs on the host machine.
In this situation, refer to the system log of the host machine and remove the cause of the error. After the host machine has fully recovered, refer to "8.1 Starting" and restart the system that this product is installed in.
Information
If a system error occurs on the host machine in a virtual environment, there will be no switch to the secondary master server (some exceptions apply). Refer to "2.2.1 Virtual Machine Function" in "PRIMECLUSTER Installation and Administration Guide 4.3" for information on these operations, and refer to the articles on the configurations listed below:
If a cluster system is built between the guest operating systems on a single host operating system
If a cluster system is built between the guest operating systems on multiple host operating systems, without using the feature for switching when an error occurs on a host operating system
The following sections describe the corrective actions to take after an error occurs on the primary master server.
Figure 15.1 Procedure to resume tasks after an error occurs in a replicated configuration
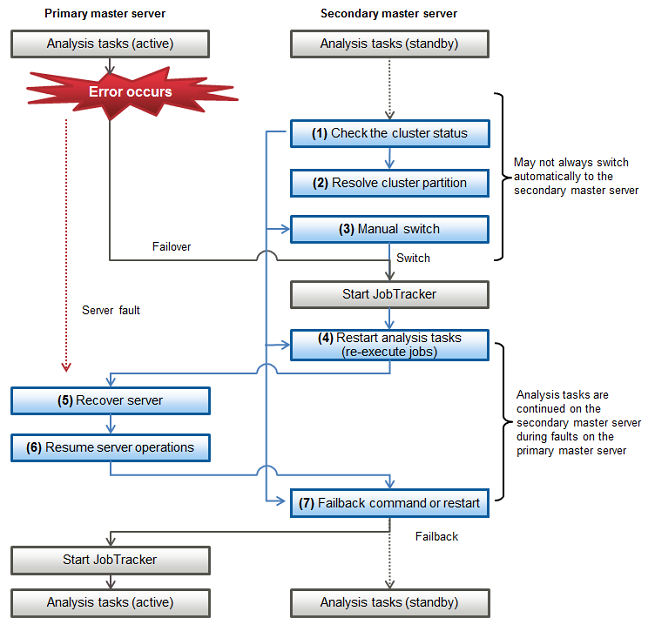
If an error occurs on the primary master server, check that operations have switched to the secondary master server.
Note that switching will cause the status to transition, so wait 5 minutes after the error occurs before checking the status.
Refer to "Checking the status of the master server HA cluster", and check if operations have switched to the secondary master server.
If operations have switched, check the status of the primary master server.
If the status of the primary master server is "Faulted" (or if the system is not running)
Continue operations on the secondary master server until the primary master server has recovered. Proceed to Step (4) "Restart analysis tasks (re-execute jobs)".
If the status of the primary master server is "Offline"
Failback to the primary master server is possible in this state. Proceed to Step (7) "Failback command or restart".
If switching has not occurred, refer to "Checking the status of communication between master servers" for information on how to check the communication status between the primary and secondary master servers.
If the status of the remote side of both master servers is "LEFTCLUSTER"
A cluster partition has occurred. Proceed to Step (2) "Resolve cluster partition".
If the status of the remote side of the secondary master server is "LEFTCLUSTER"
A switch to the secondary master server must be performed manually. Proceed to Step (3) "Manual switch".
Tasks can be continued on the primary master server, but the cluster partition must be resolved.
Remove the fault on the cluster interconnect (CIP).
Restart the secondary master server.
If a master server has been installed in a physical environment or a virtual environment (KVM):
# shutdown -r now <Enter>
If a master server has been installed in a virtual environment (VMware) (requires the system to be forcibly stopped):
# reboot -f <Enter>
Refer to "Checking the status of communication between master servers", and check the communication status between the primary and secondary master servers. Confirm that the communication status has recovered (the status of both master servers is "UP (starting)").
This action will return the servers to their normal operating status (no subsequent steps required).
Operations must be switched to the secondary master server, because a system error has occurred on the primary master server.
Unmount the DFS on all slave servers, development servers, and collaboration servers.
Example
If the logical file system name of the DFS is pdfs1:
# umount pdfs1 <Enter>
Forcibly stop the system on the secondary master server, and restart.
# reboot -f <Enter>
Forcibly start the pdfsfrmd daemon on the secondary master server.
# pdfsfrmstart -f <Enter>
Confirm that the status of the DFS on the secondary master server is "run".
Example
If the DFS management server (MDS) has been switched to the secondary master server:
# pdfsrscinfo -m <Enter> /dev/disk/by-id/scsi-1FUJITSU_300000370106: FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname 1 MDS(P) stop - 0 0 0 master1 1 AC stop - 0 0 0 master1 1 MDS(S) run - 0 0 0 master2 <- (*1) 1 AC run - 0 0 0 master2
*1: Status of the secondary master server is "run"
Note
If the master server is configured so that the DFS is not mounted automatically when the master server is started, mount the DFS manually.
Mount the DFS on all slave servers, development servers, and collaboration servers.
Example
If the logical file system name of the DFS is pdfs1:
# mount pdfs1 <Enter>
Forcibly start Hadoop by executing the bdpp_start command on the secondary master server.
# /opt/FJSVbdpp/bin/bdpp_start -f <Enter>
Refer to "Checking the status of the master server HA cluster", and check if operations have switched to the secondary master server.
See
Refer to the relevant command in "Appendix A Command Reference" in the "Primesoft Distributed File System for Hadoop V1 User's Guide" for information on the pdfsfrmstart and pdfsrscinfo commands.
Refer to "A.14 bdpp_start" for information on this command.
If an error occurs on the primary master server during execution of jobs and operations switch to the secondary master server, these jobs may be interrupted. Check the job execution status and if required, re-execute the jobs on the secondary master server that was switched to.
Note
Starting and stopping Hadoop
Hadoop can be started or stopped solely on the secondary master server only if an error has occurred on the primary master server, or if it is not running. After the primary master server has recovered, promptly perform failback to the primary master server.
Do not run Hadoop on the secondary master server when the primary master server is in a normal state.
See
Refer to "Checking the status of the master server HA cluster" for information on the status of the master server.
Refer to "A.14 bdpp_start" and "A.16 bdpp_stop" for information on starting and stopping Hadoop.
Refer to the system log of the primary master server. Investigate and remove the cause of the error.
If a serious error has occurred on the master server, requiring a server to be rebuilt, use the restore feature of this product to recover. The restore feature can be used to recover the system configuration and the master server definition information.
Refer to "14.2.1.1 Restoring a Master Server, Development Server, or Collaboration Server" for information on the procedure to restore the master server.
Point
Prior to performing a restore, a backup of the master server must be created when it is running normally.
Refer to "14.1.2.1 Backing Up a Master Server, Development Server, or Collaboration Server" for information on the procedure to back up the master server.
After the primary master server has fully recovered, restart it.
After the primary master server has fully recovered and operations have resumed, perform failback from the secondary master server to the primary master server. Failback can be performed either by executing the failover command on the secondary master server or by restarting the system.
Note that if analysis tasks were being performed on the secondary master server, operations must be stopped temporarily (after stopping jobs) prior to performing failback.
The procedure to perform failback using commands is given below.
Unmount the DFS on the secondary master server.
This operation will cause the DFS management server (MDS) to failback.
Example
If the DFS mount point is /mnt/pdfs:
# pdfsumount /mnt/pdfs <Enter>
Mount the DFS on the secondary master server.
Example
If the DFS mount point is /mnt/pdfs:
# pdfsmount /mnt/pdfs <Enter>
Confirm that the status of the DFS on the primary master server is "run".
Example
If the DFS management server (MDS) has faild back to the primary master server:
# pdfsrscinfo -m <Enter> /dev/disk/by-id/scsi-1FUJITSU_300000370106: FSID MDS/AC STATE S-STATE RID-1 RID-2 RID-N hostname 1 MDS(P) run - 0 0 0 master1 <- (*1) 1 AC run - 0 0 0 master1 1 MDS(S) wait - 0 0 0 master2 1 AC run - 0 0 0 master2
*1: Status of the primary master server is "run"
Execute the hvswitch command on the secondary master server, and failback from the secondary master server to the primary master server.
# hvswitch app1 <Enter>
app1 is a fixed string.
Refer to "Checking the status of the master server HA cluster", and confirm that failback to the primary master server was successful.
See
Refer to the relevant commands in "Appendix A Command Reference" in the "Primesoft Distributed File System for Hadoop V1 User's Guide" for information on the pdfsumount, pdfsmount, and pdfsrscinfo commands.
Refer to the online Help of hvswitch for details of the hvswitch(1M) command.
Note
The master server functionality that is used for the execution of "12.1 Adding Slave Servers" is not a target for switching. If an error occurs on the primary master server and it switches to the secondary master server, remove the cause of the error from the primary master server and failback to the primary master server. Then, perform the steps in "12.1 Adding Slave Servers" again.
Information
If the master servers use replicated configuration and either the primary or secondary master server is not running, start operations as shown below.
Starting the system when the primary master server is not running
Hadoop can be started by using the bdpp_start command if the system has been running solely on the secondary master server, because an error rendered the primary master server inoperable.
Refer to "A.14 bdpp_start" for information on starting Hadoop.
Starting the system when the secondary master server is not running
Hadoop can be started by using the bdpp_start command if the system has been running solely on the primary master server, because an error rendered the secondary master server inoperable.
Refer to "A.14 bdpp_start" for information on starting Hadoop.