This section explains how to add slave servers after operations have started.
Remounting (Only if replicated configuration is used for the master server)
The procedure for adding a slave server is shown below.
Use root permissions for all tasks in this procedure.
Note that the location for implementing the procedure outlined in "12.1.3 Adding by Cloning" will vary depending on the environment in which the additional slave server will be installed.
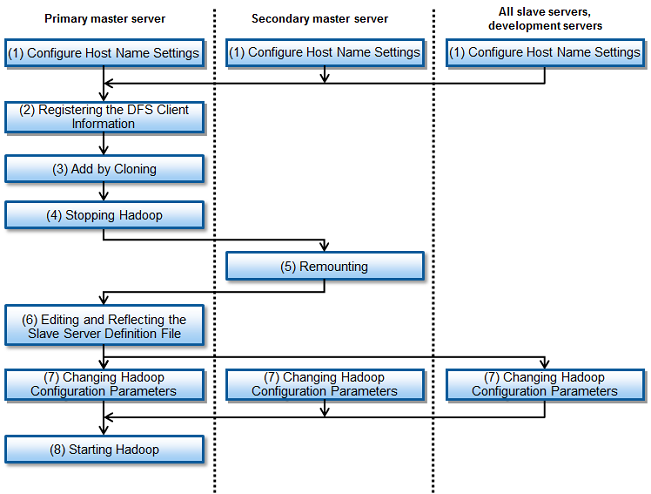
This section describes the procedure to install even more slave servers, in addition to those comprising the configuration built in "6.3 Adding Second and Subsequent Slave Servers" during initial installation, using the following environment as an example.
| : /dev/disk/by-id/scsi-1FUJITSU_300000370106 |
| : 1 |
| : /mnt/pdfs |
| : master1 (primary), master2 (secondary) |
| : slave1, slave2, slave3, slave4, slave5 |
| : slave6 |
| : slave7, slave8, slave9, slave10 |