This filter can perform table operations on the results of an operation component or in filter output, such as sorting columns, and selecting columns, rows and blocks.
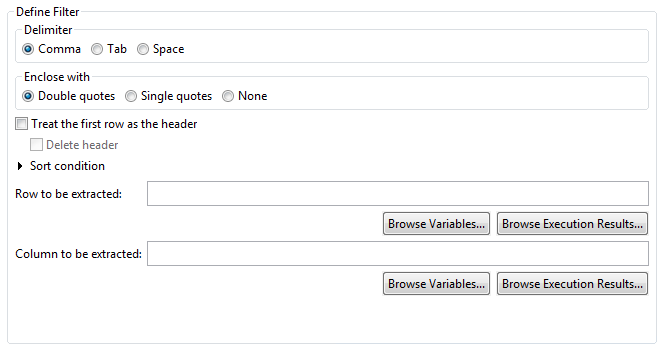
Select the character to split the input data into values (columns).
Comma (Default)
Tab
Spaces
Select characters to enclose values:
Double quotes (Default)
Single quote
Select to treat the first row as the header. Select Treat the first row as the header to exclude the first row from sorting. The default is off.
Select to delete the header row. The default is off.
This is available only when Treat the first row as the header has been selected.
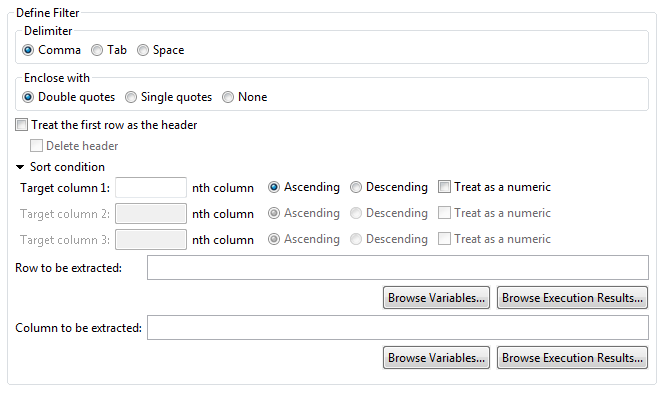
Click Sort condition to expand (display) the settings items for the sort conditions.
To sort by column, enter up to three column numbers (starting from 1) in the desired priority order in the Target column field. Leave the field empty is no sort should occur.
All fields are empty by default. Only the left field can be entered initially. The center and right fields are unavailable (grayed out). Once a value is entered in Target column 1, Target column 2 can be entered. Then, once a value is entered in Target column 2, Target column 3 can be entered.
Select to sort columns in ascending order. (Default)
Select to sort columns in descending order.
Select to sort as if the values were numbers. An error will occur if the value has not been provided (is empty) or contains non-numeric characters. The default is off.
The start and the end rows to be extracted can be entered using the formats listed in the table below. The default is empty. To embed the variable (UDA) value and execution results of the previous operation component in the Row to be extracted field when the filter is applied, follow the steps below:
To embed the value: specify "@{uda: variable name}" or click the Browse variables button and select a variable from the Browse variables dialog box.
The only variables that may be specified are of the STRING or INTEGER type.
To embed the execution results of the previous operation component, specify "@{:node name:execution results}"or click the Browse execution results button and select an execution result from the Browse execution results dialog box.
Format (start row - end row) | Selected row |
|---|---|
None | All rows |
1-10 | From row 1 to row 10 |
-10 | From row 1 to row 10 |
1- | From row 1 to the last row |
The filter will end in an error if there is only a hyphen (-) or if there are 2 or more hyphens.
An error will occur if a character other than hyphen (-) or a number (0-9) is entered.
An error occurs on executing the filter if multiple "@{uda:variable name}" or "@{:node name:execution results}" are specified.
Enter the column to be extracted in the following format. The default is empty. To embed the variable (UDA) value and execution results of the previous operation component in the Column to be extracted field when the filter is applied, follow the steps below:
To embed the value, specify "@{uda: variable name}" or click the Browse variables button and select a variable from the Browse variables dialog box.
The only variables that may be specified are of the STRING or INTEGER type.
To embed the execution results of the previous operation component, specify "@{:node name:execution results}" or click the Browse execution results button and select an execution result from the Browse execution results dialog box.
Format | Selected column |
|---|---|
None | All columns |
1,3 | 1st column (far left) and 3rd column |
1-3 | 1st column (far left) to 3rd column |
2- | 2nd column to last column (far right) |
-10 | 1st column (far left) to 10th column |
1-3,6-8 | 1st column (far left) to 3rd column and 6th column to 8th column |
The filter will end in an error if there is only a hyphen (-) or if there are consecutive hyphens.
The filter will end in an error if characters other than hyphens (-), commas (,), or numerals (0-9) are included.
The filter will end in an error if there is only a comma (,) or if there are consecutive commas.
If the same column is specified more than once, only the first time is valid. Therefore "1-5,2" is the same as specifying "1,2,3,4,5".
An error occurs on executing the filter if the specified column number does not exist.
An error occurs on executing the filter if multiple "@{uda:variable name}" or "@{:node name:execution results}" are specified.
Note
Precautions when Testing Filters
If "@{uda: variable name}"is specified in the Column to be extracted field :
The test will use the value assigned in theSet test variablesdialog box (*1) or an empty string if no value is assigned (and as a result all rows will be extracted).
If "@{Node name Execution results}"is specified in the Column to be extracted field:
The test will use the value assigned in the Set test variablesdialog box (*1) or an empty string if no value is assigned (and as a result all rows will be extracted).
If "@{uda: variable name}"is specified in the Column to be extracted field :
The test will use the value assigned in the Set test variables dialog box (*1) or an empty string if no value is assigned (and as a result all rows will be extracted).
If "@{Node name Execution results}"is specified in the Column to be extracted field:
The test will use the value assigned in the Set test variables dialog box (*1) or an empty string if no value is assigned (and as a result all rows will be extracted).
When the filter is applied on the Management Server, these variables (UDA) or execution results are replaced with the stored values.
*1: Refer to "6.3.2 Testing Filters" for information on theSet test variables dialog box.
Input: | "Server name","Administrator","Contact"[linefeed] "Server-C","User2","1111-2222"[linefeed] "Server-A","User1","1111-1111"[linefeed] "Server-B","User3","2222-1111"[linefeed] "Server-A","User2","1111-2222"[linefeed] |
Delimiter: | Comma |
Enclosing character: | Double quotes |
Treat first row as header: | On |
Delete header: | On |
Sorting conditions (target column 1): | First column, ascending |
Sorting conditions (target column 2): | Second column, descending |
Row to be extracted: | Not input |
Column to be extracted: | Not input |
Output: | Server-A,User2,1111-2222[linefeed] Server-A,User1,1111-1111[linefeed] Server-B,User3,2222-1111[linefeed] Server-C,User2,1111-2222[linefeed] |