運用操作部品の出力情報(実行結果/標準出力/標準エラー出力)をフィルタリングし、次の運用操作部品への入力として渡すことができます。
出力情報のフィルタリングは個々の出力情報に対して、JavaScript でフィルター処理を記述することにより利用することができます。
運用操作部品の出力情報(XML形式)からXPathで指定されたノードの値を抽出し、以降の運用操作部品の入力情報として渡すことができます。
運用操作部品の出力情報(XML形式)については、“Systemwalker Runbook Automationリファレンスガイド”の“運用操作部品リファレンス”-“構成要素を取得する”を参照してください。
プロセス定義エディタで、運用操作部品ノードを選択します。
※ここで選択する運用操作部品ノードは、標準出力としてXML形式の情報を出力します。
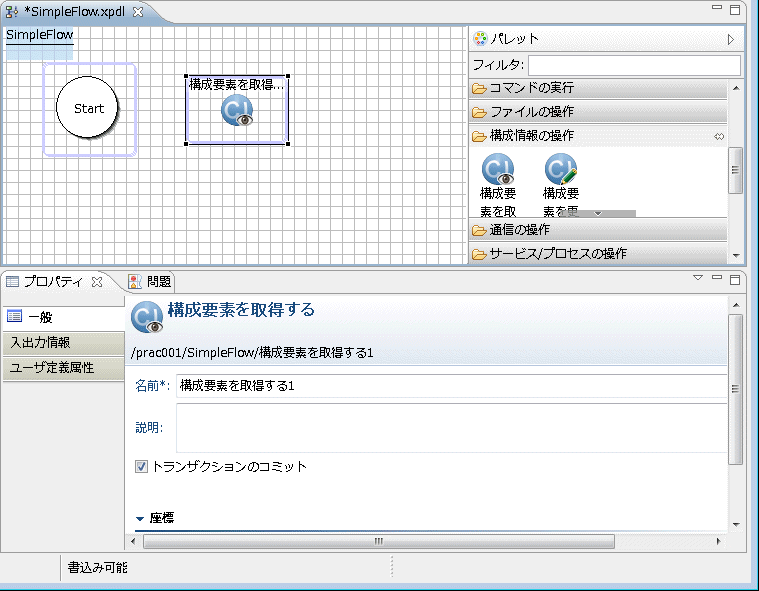
[プロパティ]-[入出力情報]-[出力情報]タブを選択します。
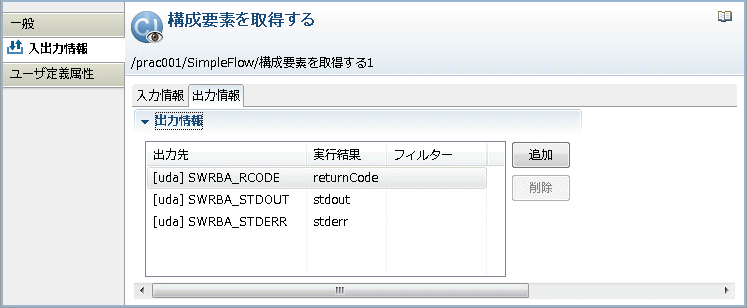
[追加]ボタンをクリックします。
→[出力情報]のリストに新しい出力情報が追加されます。
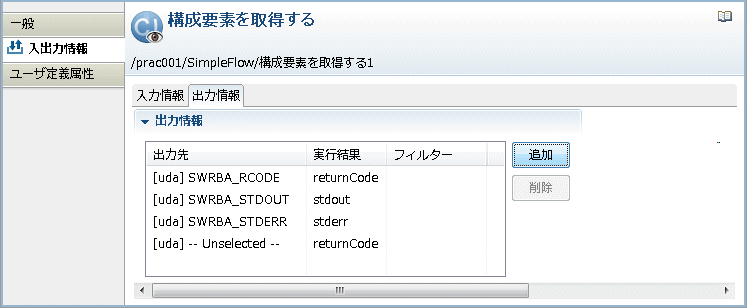
[出力情報]のリストから新しく追加した出力情報を選択します。
→右側に設定画面が表示されます。
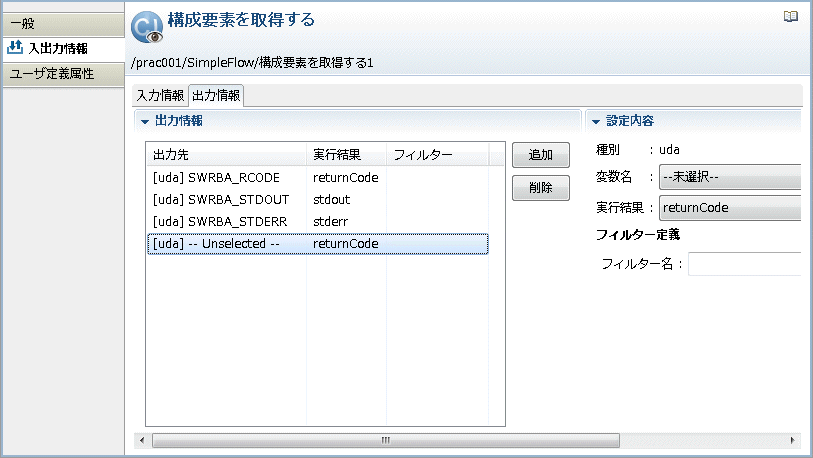
[設定内容]-[変数名]コンボボックスから、フィルタリングした結果を格納する変数(UDA)の名前を選択します。ここでは、"hostname" を選択しています。
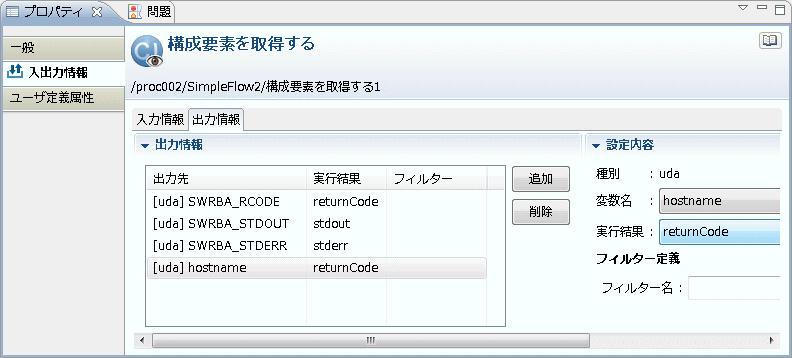
[設定内容]-[実行結果]コンボボックスから、"stdout" を選択します。
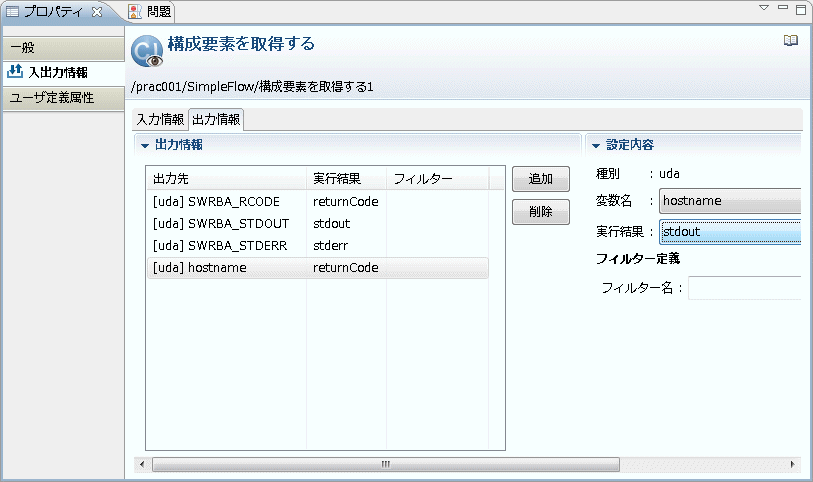
[設定内容]-[フィルター定義]の[追加]ボタンをクリックします。
→[フィルター定義]ダイアログが表示されます。
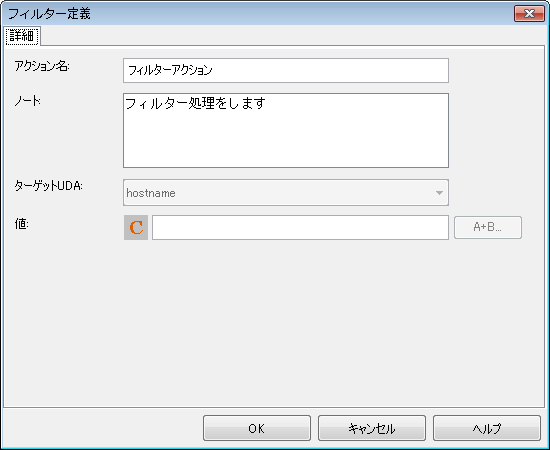
[アクション名]フィールドに任意のフィルター名を入力します。ここでは、フィルターの名前として"ホスト名の抽出"を入力しています。
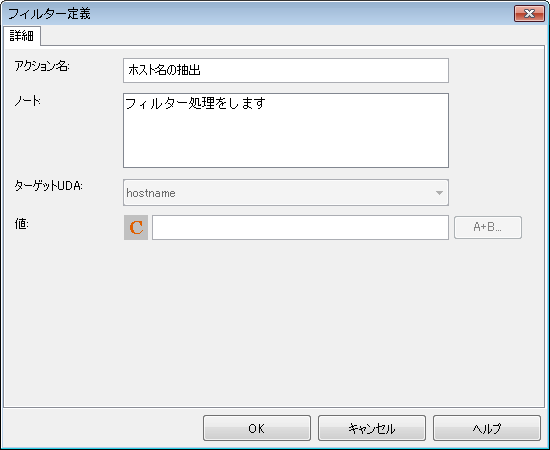
[式モード選択]ボタンをクリックして、[E]ボタンに変更します。
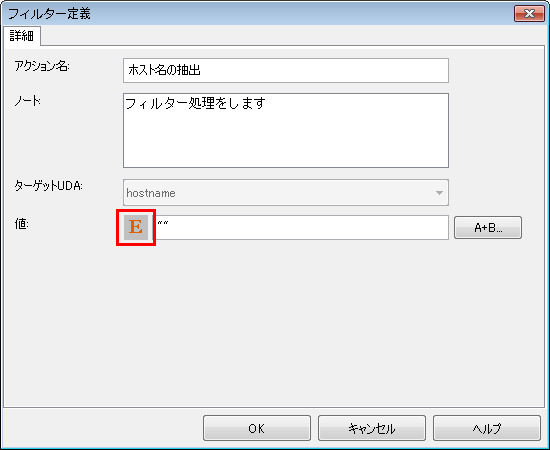
[A+B...]ボタンをクリックします。
→[式の作成]ダイアログが表示されます。
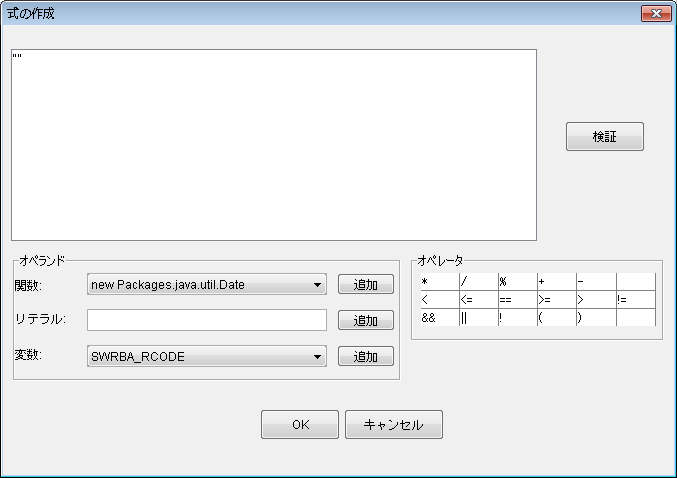
次のようなJavaScriptを入力します。
target_uda = "hostname"; ・・・・・(1) xpath = "/entities/item/record/LogicalServer/@hostname"; ・・・・・(2) factory = Packages.javax.xml.parsers.DocumentBuilderFactory.newInstance(); builder = factory.newDocumentBuilder(); strReader = new Packages.java.io.StringReader(uda.get(target_uda)); doc = builder.parse(new Packages.org.xml.sax.InputSource(strReader)); xpathFactory = Packages.javax.xml.xpath.XPathFactory.newInstance().newXPath(); xpathFactory.evaluate(xpath, doc); |
JavaScriptのターゲットUDAおよびXPathは必要に応じて修正してください。
(1) ターゲットUDAの名前を指定します。
(2) ノードの値を抽出するためのXPathを指定します。
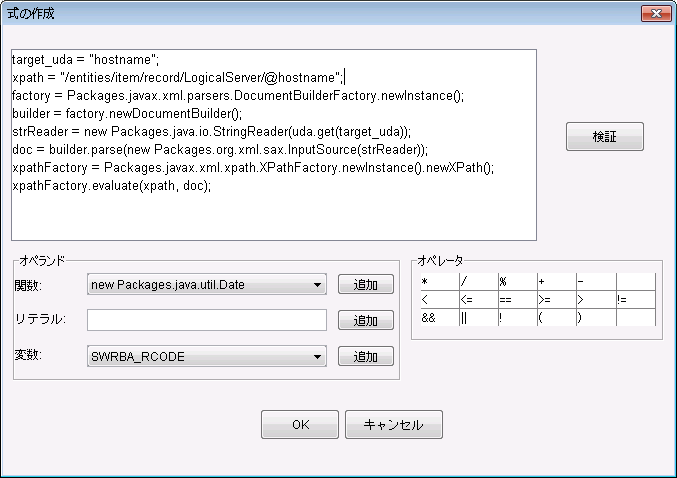
[式の作成]ダイアログで、[OK]ボタンをクリックします。
[フィルター定義]ダイアログで、[OK]ボタンをクリックします。
→[設定内容]-[フィルター名]に、作成したフィルターの名前が表示されます。また、[出力情報]のリストの[フィルター]欄にも表示されます。
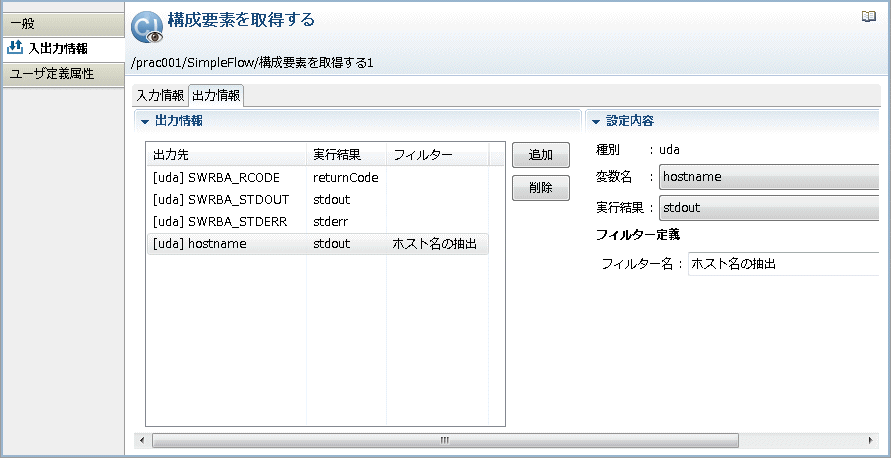
以降の運用操作部品の入力情報として、hostname を渡すことができます。
運用操作部品の出力情報から指定したキーワードを含んだ行を抽出することができます。
ここでは、「任意のコマンドを実行する」部品を使って実行するコマンドが標準出力へ出力した結果からキーワードを含んだ特定の行を抽出する例を示します。
プロセス定義エディタで、運用操作部品ノードを選択します。
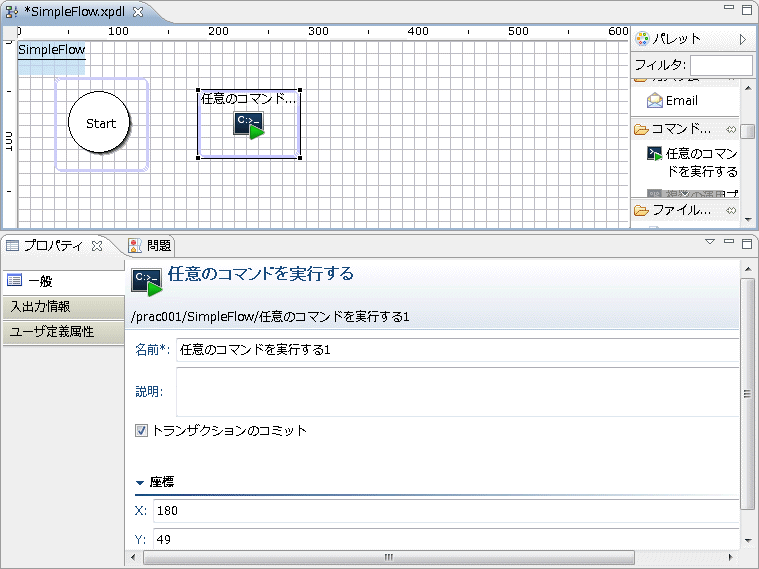
[プロパティ]-[入出力情報]-[出力情報]タブを選択します。
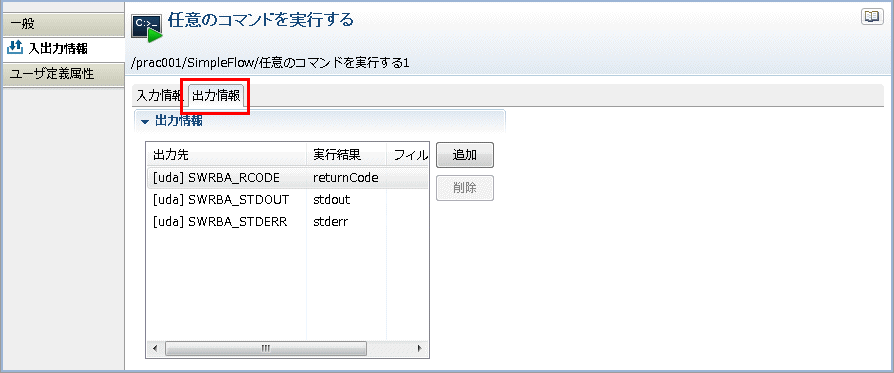
[追加]ボタンをクリックします。
→[出力情報]のリストに新しい出力情報が追加されます。
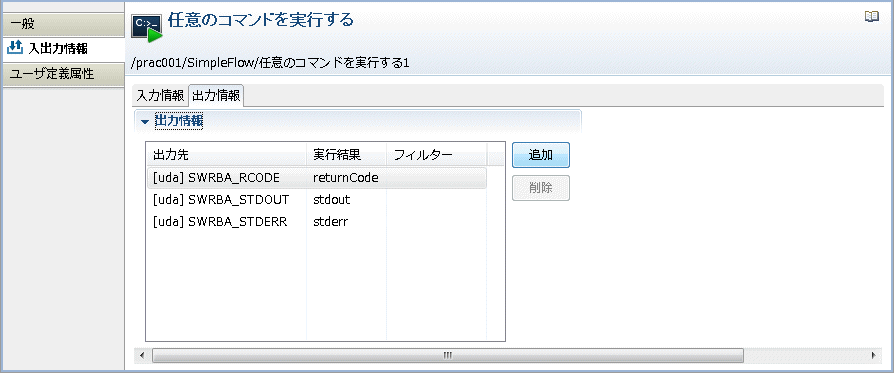
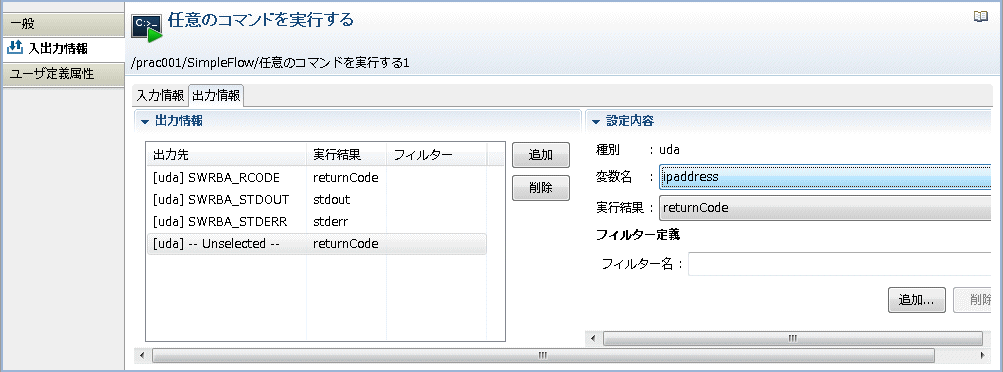
[出力情報]のリストから新しく追加した出力情報を選択します。
→右側に設定画面が表示されます。
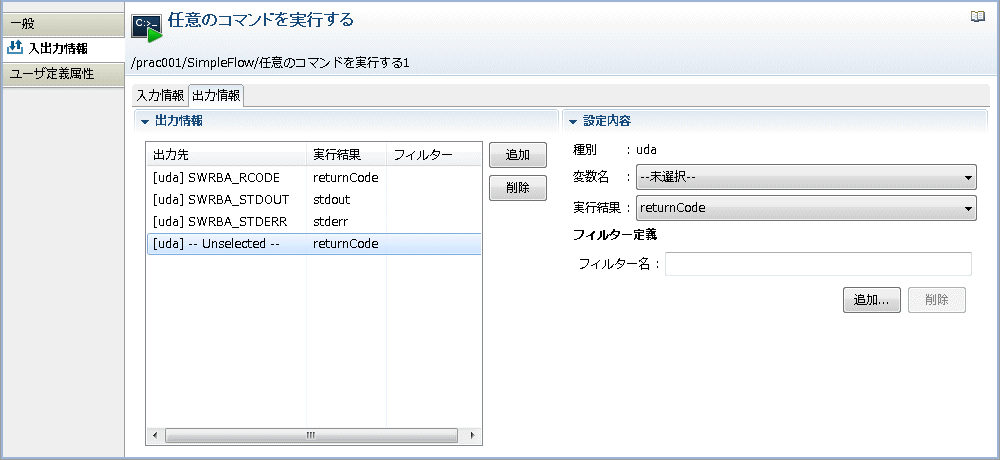
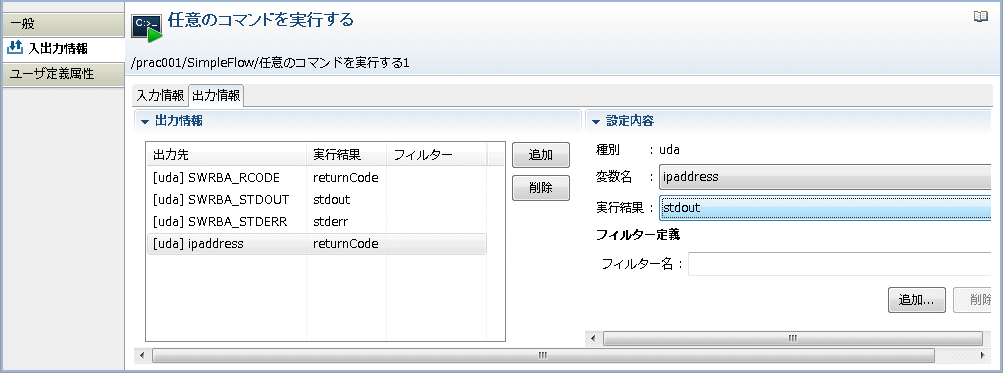
[設定内容]-[変数名]コンボボックスから、フィルタリングした結果を格納する変数(UDA)の名前を選択します。ここでは、"ipaddress" を選択しています。
[設定内容]-[実行結果]コンボボックスから、"stdout" を選択します。
[設定内容]-[フィルター定義]の[追加]ボタンをクリックします。
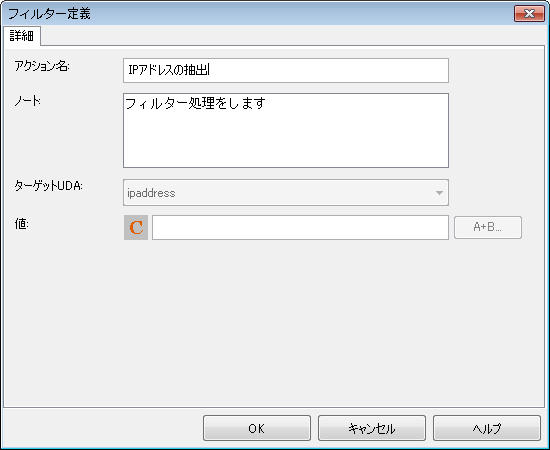
→[フィルター定義]ダイアログが表示されます。
[アクション名]フィールドに任意のフィルター名を入力します。ここでは、フィルターの名前として"IPアドレスの抽出"を入力しています。
[式モード選択]ボタンをクリックして、[E]ボタンに変更します。
[A+B...]ボタンをクリックします。
→[式の作成]ダイアログが表示されます。
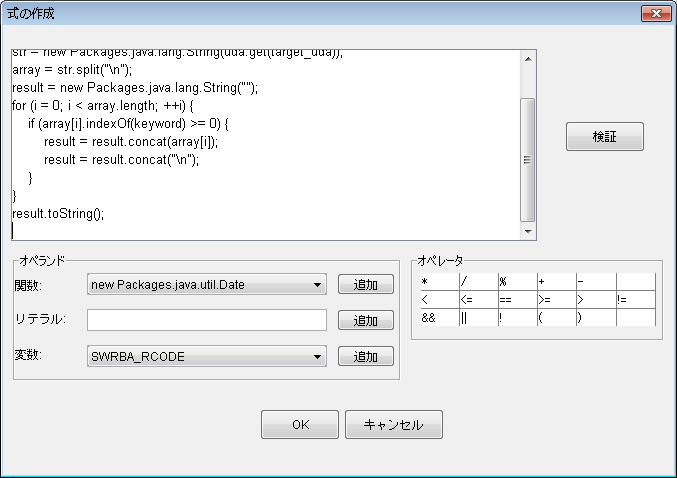
次のようなJavaScriptを入力します。
target_uda = "ipaddress"; ・・・・・(1)
keyword = "IP Address"; ・・・・・(2)
str = new Packages.java.lang.String(uda.get(target_uda));
array = str.split("\n");
result = new Packages.java.lang.String("");
for (i = 0; i < array.length; ++i) {
if (array[i].indexOf(keyword) >= 0) { ・・・・・(3)
result = result.concat(array[i]);
result = result.concat("\n");
}
}
result.toString();
JavaScriptのターゲットUDAおよびkeywordは必要に応じて修正してください。
(1) ターゲットUDAの名前を指定します。
(2) ノードの値を抽出するためのkeywordを指定します。
(3) の行の条件を変更することにより、キーワードの検索方式を指定することができます。以下のような条件を指定することができます。
前方一致:array[i].startsWith(keyword)
後方一致:array[i].endsWith(keyword)
部分一致:array[i].indexOf(keyword) >= 0
正規表現:array[i].matches(keyword)
注意
後方一致を行う場合はWindows環境での改行コード(キャリッジリターン(CR))を考慮する必要があります。以下の例では、"Files"という文字列で終わる行を抽出するための判定条件として、"Files"または"Files\r"という文字列で終わっているかどうかを判定しています。
target_uda = "result";
keyword1 = "Files";
keyword2 = "Files\r";
str = new Packages.java.lang.String(uda.get(target_uda));
array = str.split("\n");
result = new Packages.java.lang.String("");
for (i = 0; i < array.length; ++i) {
if (array[i].endsWith(keyword1) || array[i].endsWith(keyword2)) {
result = result.concat(array[i]);
result = result.concat("\n");
}
}
result.toString();[式の作成]ダイアログで、[OK]ボタンをクリックします。
[フィルター定義]ダイアログで、[OK]ボタンをクリックします。
→[設定内容]-[フィルター名]に、作成したフィルターの名前が表示されます。また、[出力情報]のリストの[フィルター]欄にも表示されます。
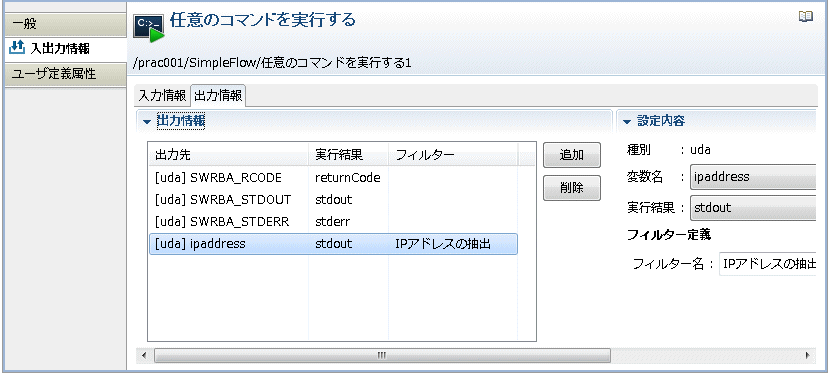
以降の運用操作部品の入力情報として、ipaddress を渡すことができます。