ここでは、JDBCデータソース登録ツールについて説明します。
この画面では、データソースの新規登録、設定変更および削除を行います。
図5.1 データソース一覧画面
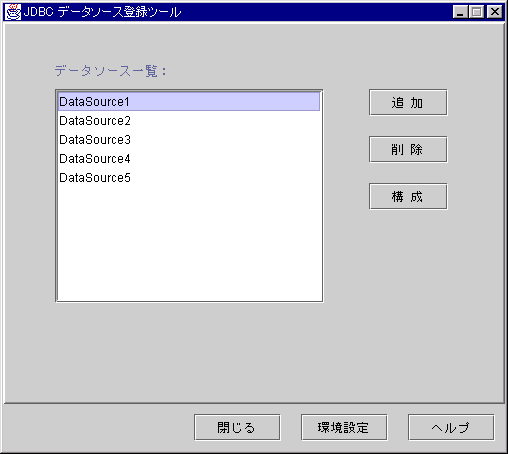
すでに登録されているデータソースの一覧を表示します。
データソース名をダブルクリックすると、選択されているデータソースの情報設定画面を開きます。
データソースが未登録の場合、何も表示されません。
データソースの登録に必要な情報の設定画面を開きます。
データソース一覧で選択されているデータソースを削除します。
データソース一覧で選択されているデータソースの情報設定画面を開きます。
JDBCデータソース登録ツールを終了します。
JDBCデータソース登録ツールのヘルプを表示するための、実行環境を設定します。
JDBCデータソース登録ツールのヘルプを表示します。
[環境設定]ボタンを選択すると、以下のダイアログが表示されます。
図5.2 ヘルプの実行環境設定ダイアログ
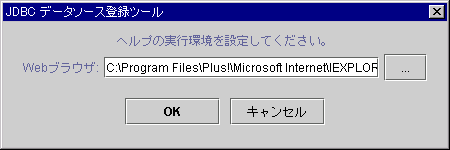
[...]を選択すると、ファイル選択ダイアログが開きます。実行環境をファイル選択ダイアログから選択すると、選択した実行環境のパスが“Webブラウザ”に表示されます。
[OK]を選択すると、指定したパスが保存されます。
[キャンセル]を選択すると、パスを保存しないで、環境設定ダイアログを開く前の画面に戻ります。
データソース一覧から、特定のデータソースを選択して[削除]ボタンを選択すると、確認ダイアログが表示されます。
図5.3 データソースの削除確認ダイアログ
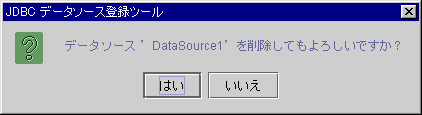
[はい]を選択すると、指定されたデータソースを削除します。
[いいえ]を選択すると、何もしないでデータソース一覧画面に戻ります。
アプリケーションの運用開始後は、ネーミングサービスを再起動するまで、データソースを削除することはできません。アプリケーションの運用開始後にデータソースを削除しようとすると、以下のダイアログが表示されます。
図5.4 アプリケーション運用開始によるエラー発生通知ダイアログ
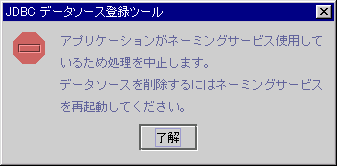
[了解]ボタンを選択して、JDBCデータソース登録ツールを終了してください。
この画面では、データソースの登録および更新を行うための情報を設定します。
図5.5 データソースの情報設定画面
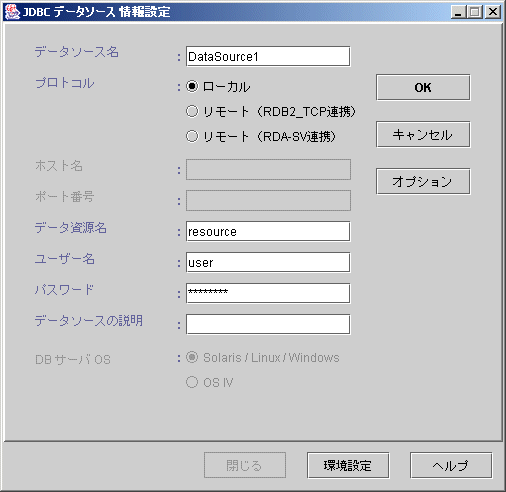
データソース名
アプリケーションから使用される名前を指定します。
省略できません。
データソース名には、以下の文字が指定できます。
各国語文字
英数字
“!”、“#”、“$”、“%”、“&”、“(”、“)”、“=”、“-”、“^”、“~”、“|”、“@”、“[”、“{”、“:”、“*”、“}”、“]”、“;”、“+”、“<”、“,”、“>”、“.”、“?”、“/”、“_”
注意
データソース名には、空白を指定することはできません。
また、以下の記号を指定することはできません。
\(円記号)
'(一重引用符)
"(二重引用符)
記号が文字列中に含まれている場合も無効です。
データベースへの接続形態を、以下の3つから選択します。
ローカル
リモート(RDB2_TCP連携)
リモート(RDA-SV連携)
デフォルトは“ローカル”です。
選択したプロトコルによって、指定可能なオプションが変わります。詳細については、“5.2.3.3 データソースのオプション情報設定画面”を参照してください。
“ローカル”または“リモート(RDB2_TCP連携)”の利用を推奨します。
“リモート(RDA-SV連携)”は、以下の場合に利用してください。
Javaアプレットを使用する場合
グローバルサーバおよびPRIMEFORCEとRDA接続する場合
接続するサーバの18バイト以内のホスト名またはIPアドレスを指定します。
ホスト名は、“プロトコル”で“リモート(RDB2_TCP連携)”または“リモート(RDA-SV連携)”を選択した時に指定可能です。
サーバのポート番号を指定します。
ポート番号は、“プロトコル”で“リモート(RDB2_TCP連携)”または“リモート(RDA-SV連携)”を選択した時に指定可能です。
データベースに接続するためのデータ資源名(データベース名)を指定します。省略できません。
データベースに接続する際のユーザIDを指定します。
省略した場合、DataSourceインタフェースのgetConnectionメソッドの引数に、必ず指定してください。
データベースに接続する際の、ユーザIDに対するパスワードを指定します。
省略した場合、DataSourceインタフェースのgetConnectionメソッドの引数に、必ず指定してください。
このデータソースについての説明を入力します。
DBサーバOS
リモートアクセス(RDB2_TCP連携)時に、接続するデータベースサーバの種類を選択します。
“Solaris/Linux/Windows”を選択してください。“OS IV”は、グローバルサーバおよびPRIMEFORCEに接続する場合に選択します。
DBサーバOSは、“プロトコル”の“リモート(RDB2_TCP連携)”を選択した時に指定可能です。
設定した内容を有効にして、このデータソースを登録/更新します。
設定した内容を無効にして、この画面を終了します。
このデータソースのオプション情報設定画面を開きます。
JDBCデータソース登録ツールとDataSourceインタフェースのgetConnectionメソッドの両方で、ユーザIDとパスワードを指定した場合、getConnectionメソッドに指定した値が有効となります。
アプリケーションの運用開始後は、ネーミングサービスを再起動するまで、アプリケーションで使用されたデータソースを更新することはできません。アプリケーションの運用開始後にデータソースを更新しようとすると、“図5.4 アプリケーション運用開始によるエラー発生通知ダイアログ”が表示されます。[了解]を選択してJDBCデータソース登録ツールを終了してください。
データソースの情報設定画面が表示されている間は、[閉じる]ボタンを選択することはできません。また、右上の[×]をクリックした場合、次のダイアログが表示されます。
図5.6 JDBCデータソース登録ツールのインフォメーションダイアログ
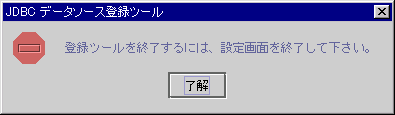
[了解]ボタンを選択すると、データソースの情報設定画面に戻ります。JDBCデータソース登録ツールを終了する場合、データソース一覧画面に戻ってから、[閉じる]ボタンまたは[×]ボタンを選択してください。
この画面は、データソースの登録および更新の際に指定可能なオプションの設定画面です。
図5.7 データソースのオプション情報設定画面
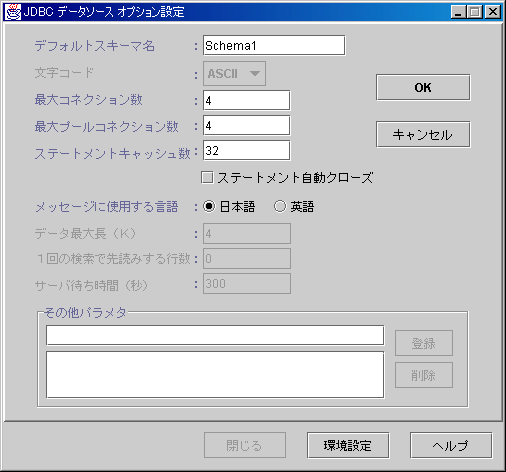
アプリケーション内で使用する、SQL文に対するデフォルトスキーマ名を指定します。
クライアントで使用する文字コードを、以下の3つから選択します。
ASCII
KANA
EIJIS
デフォルトは“ASCII”です。
注意
本オプションは、リモートアクセス(RDA-SV連携)時に指定可能です。
データソースごとに、同時に接続可能なコネクション数の上限を指定します。
1~2147483647の範囲で指定します。
デフォルトは4です。
再利用可能なコネクション数の上限を指定します。
0~2147483647の範囲で指定します。
デフォルトは 4です。
このオプションに 0を指定した場合、コネクションは再利用されずに切断されます。
1以上を指定した場合、Connectionインタフェースのcloseメソッドを実行してもデータベースとの接続は切断されず、コネクションは再利用可能な状態になります。ただし、指定値を超えるコネクションは切断されます。
また、“最大コネクション数”を超える値は指定できません。
ステートメントキャッシュ機能でキャッシュする、文の上限を指定します。
0~32000の範囲で指定します。
デフォルトは32です。
このオプションに 0を指定した場合、ステートメントキャッシュ機能は無効になります。
キャッシュする文の数の見積りは、以下となります。
キャッシュする文の数 = prepareStatementメソッドまたは
prepareCallメソッドで指定するSQL文の数(注)注) 同じSQL文でも以下の場合は別のSQL文として計算してください。
大文字と小文字の違いがある場合
結果セットのタイプが異なる場合
結果セットの並行処理のタイプが異なる場合
注意
本オプションは、ローカルアクセスまたはリモートアクセス(RDB2_TCP連携)時に指定可能です。
ステートメントキャッシュ機能の利用時に、PreparedStatementおよびCallableStatementのクローズをJDBCドライバが自動的に行うかどうかを指定します。
自動的に行う場合には、[ステートメント自動クローズ]チェックボックスをチェックします。デフォルトでは、自動クローズは行いません。
このオプションは、ステートメントキャッシュ数に1~32000が指定された場合に指定可能です。
実行した文の数が、「ステートメントキャッシュ数」で設定されたキャッシュ数に達した場合、以降実行される文はキャッシュしませんが、自動クローズの対象にもなりません。
注意
本オプションは、ローカルアクセスまたはリモートアクセス(RDB2_TCP連携)時に指定可能です。
JDBCドライバから返却されるエラーメッセージを出力する際の言語を選択します。
サーバから1回で読み込むデータの最大長を指定します。
単位はキロバイトです。
4~32までの数値を指定することができます。
デフォルトは 4です。
注意
本オプションは、リモートアクセス(RDA-SV連携)時に指定可能です。
サーバから1回の検索で先読みする行数を指定します。
0~2147483647までの数値を指定することができます。
デフォルトは 0です。
0を指定した場合、1回の検索で問合せを行う最大行数が自動設定されます。その行数は“データ最大長”で指定された値に依存します。また、0以外の値(N)を指定した場合、指定した行数のデータ長の合計が“データ最大長”の指定値以下の時には、N行が先読みされます。指定値を超える時は、“データ最大長”の指定値におさまる行数分が先読みされます。
注意
本オプションは、リモートアクセス(RDA-SV連携)時に指定可能です。
サーバからの応答に対する待ち時間を、秒単位で指定します。
0~2147483までの数値を指定することができます。
デフォルトは300です。
注意
本オプションは、リモートアクセス(RDA-SV連携)時に指定可能です。
その他パラメタには、ctuneparamオプションを指定することができます。
詳細は、“5.2.3.4 ctuneparamオプションについて”を参照してください。
設定した内容を有効にして、データソースの情報設定画面に戻ります。
設定した内容を無効にして、データソースの情報設定画面に戻ります。
データソースのオプション情報設定画面が表示されている間は、[閉じる]ボタンを選択することはできません。また、右上の[×]をクリックした場合、設定画面を終了するように求める“図5.6 JDBCデータソース登録ツールのインフォメーションダイアログ”が表示されます。ダイアログの[了解]ボタンをクリックすると、データソースのオプション情報設定画面に戻ります。
ctuneparamオプションには、Symfoware Serverのクライアント用の動作環境ファイルに相当する指定をすることができます。なお、ctuneparamオプションで設定できるパラメタ名の先頭文字“CLI_”を削除したパラメタが、Symfoware Serverのクライアント用の動作環境ファイルのパラメタと一致しています。
データソースにctuneparamオプションで指定したパラメタはコネクション接続時に読み込まれます。
注意
本オプションは、ローカルアクセスまたはリモートアクセス(RDB2_TCP連携)時に指定可能です。
動作環境パラメタの指定の優先順位
動作環境の設定項目の中には、システム用の動作環境ファイル、サーバ用の動作環境ファイルおよびctuneparamオプションで重複して指定できるパラメタがあります。重複して指定した場合の優先順位は、以下のとおりです。
サーバ用の動作環境ファイル
ctuneparamオプション
システム用の動作環境ファイル
【記述形式】
ctuneparam='<param>'
<param>...ctuneparamオプションで指定するパラメタ
【記述例】
CLI_MAX_SQLとCLI_WAIT_TIMEを指定した場合
ctuneparam='CLI_MAX_SQL=(255);CLI_WAIT_TIME=(30)'
注意
ctuneparamオプションに複数のパラメタを指定する場合、値を“;”(セミコロン)で区切って設定します。
【パラメタ】
JDBCドライバを利用するアプリケーションから指定可能なパラメタは以下となります。
分類 | パラメタ | 概要 |
|---|---|---|
通信 | 通信に使用するバッファサイズ | |
使用するサーバ用の動作環境ファイル | ||
SQLエラー発生時のトランザクション | ||
1つのトランザクションの最大使用可能時間 | ||
通信時の待ち時間 | ||
作業領域など | 同時に操作できるオブジェクトの数 | |
SQL文の実行手順を格納しておくバッファのサイズ | ||
一括FETCHを行う場合のバッファの数とサイズ | ||
作業用ソート領域として使うメモリサイズ | ||
作業用ソート領域および作業用テーブルとして使うファイルサイズ | ||
作業用テーブルとして使うメモリのサイズ | ||
作業用テーブルおよび作業用ソート領域のパス | ||
データ処理 | 代入処理でオーバフローが起きた場合の処理 | |
文字コードの変換をクライアントで行うか否か | ||
表・インデックス | 格納構造定義を簡略化したインデックスを定義する場合のインデックスのデータ格納域の初期量、拡張量、ページ長など | |
格納構造定義を簡略化した表を定義する場合のOBJECT構造の表のデータ格納域の初期量、拡張量、ページ長など | ||
格納構造定義を簡略化した表を定義する場合の表のデータ格納域の初期量、拡張量、ページ長など | ||
DSIの容量拡張を起動するか否か | ||
アプリケーションで使用するDSIを限定する | ||
一時表にインデックスを定義する場合のインデックスのデータ格納域の初期量、拡張量など | ||
一時表を定義する場合の表のデータ格納域の初期量、拡張量など | ||
アクセスプラン | アプリケーション単位でアクセスプランを取得するか否かおよびSQL文に対するアドバイスを出力するか否か | |
性能情報 | インデックスを使用しないアクセスプランを選択するか否か | |
非活性状態のインデックスDSIを含むインデックスを使用したアクセスプランを選択するか否か | ||
ジョインする方法 | ||
結合表と他の表のジョイン順 | ||
四則演算の検索範囲について、インデックスの範囲検索、または、クラスタキー検索を行うか否か | ||
探索条件のCASTオペランドに指定した列でインデックスの範囲検索、または、クラスタキー検索を行うか否か | ||
ソート処理がレコードをハッシングして格納するための領域サイズ | ||
アプリケーション単位でSQL性能情報を取得するか否か | ||
述語ごとの検索範囲の選択率の値 | ||
インデックス検索と表データ取得のアクセスモデルでTIDソートを利用するか否か | ||
TIDユニオンマージのアクセスモデルを有効にするか否か | ||
UPDATE文:探索またはDELETE文:探索の更新標的レコードを位置づける部分の占有モード | ||
排他 | 使用するDSOの占有の単位、占有モード | |
占有待ちの方式 | ||
占有の単位を行とする | ||
デバッグ | ストアドプロシジャのルーチンのトレースを出力するか否か | |
リカバリ | アプリケーションのリカバリ水準を指定する | |
予約語 | アプリケーションの予約語レベルを設定する | |
並列クエリ | データベースを並列に検索する場合の多重度 | |
アプリケーション単位またはコネクション単位にデータベースを並列に検索するか否か | ||
その他 | アーカイブログ満杯時にエラー復帰するか否か |
アプリケーション単位でアクセスプランを取得するかどうかを指定します。
CLI_ACCESS_PLAN = ({ON | OFF},ファイル名[,出力レベル][,SQLアドバイザ出力レベル])
CLI_ACCESS_PLAN = (OFF)
アクセスプラン取得機能を利用する場合に指定します。
アクセスプラン取得機能を利用しない場合に指定します。
出力先のサーバ側のファイル名を、絶対パスで指定します。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
出力レベルには1または2を指定します。
1を指定すると、アクセスプランのセクション情報のみを出力し、2を指定すると、セクション内の各エレメント詳細情報も出力します。
省略した場合は、2が指定されたものとみなします。
SQLアドバイザ出力レベルには、“ADVICE”または“NOADVICE”を指定します。
“ADVICE”を指定すると、SQL文に対するアドバイスを出力します。“NOADVICE”を指定すると、SQL文に対するアドバイスを出力しません。省略した場合は、“NOADVICE”が指定されたものとみなします。
アーカイブログファイルが満杯状態になったとき、エラー復帰するか否かを指定します。
CLI_ARC_FULL = ({RETURN | WAIT})
省略した場合は、システム用の動作環境ファイルにおけるARC_FULLの指定に従います。
エラーとしてアプリケーションに復帰します。
空きのアーカイブログファイルが作成されるまで待ちます。
注意
“WAIT”を指定した場合、空きのアーカイブログファイルが作成されるまでアプリケーションは無応答状態となりますので注意してください。
また、本実行パラメタの指定が、互いに異なる複数のアプリケーションが同時に同じDSIを扱うような運用はしないでください。例えば、以下の事象が発生する場合があります。
トランザクションAは、CLI_ARC_FULL=RETURNを設定し、アーカイブログ満杯の状態であるとします。トランザクションBは、CLI_ARC_FULL=WAITを設定し、アーカイブログ満杯の状態で資源を占有しているとします。このとき、トランザクションBは、空きのアーカイブログファイルが作成されるまで待ちます。同じ資源にアクセスしているトランザクションAは、トランザクションBの終了を待つため、CLI_ARC_FULL=RETURNを設定しているにもかかわらず、無応答状態になります。
この場合は、rdblkinfコマンドのlオプションやrdblogコマンドのVオプションかつaオプションで排他やアーカイブログの状況を確認できます。また、アーカイブログに関する以下のシステムメッセージが表示されます。これらの情報をもとに、バックアップ可能なアーカイブログファイルをバックアップするか、または新規にアーカイブログファイルを追加して対処してください。
qdg13336w:RDB:WARNING 転送可能なアーカイブログ域が不足しています. qdg03132u:RDB:ERROR アーカイブログファイルが満杯です.
通信に利用するバッファサイズを指定します。
単位はキロバイトです。
CLI_BUFFER_SIZE = ([初期量][,拡張量])
バッファの初期量を1~10240で指定します。
省略した場合、1になります。
拡張量を1~10240で指定します。
省略した場合、32になります。
代入処理でオーバフローが発生した場合の処理を指定します。
CLI_CAL_ERROR = ({REJECT | NULL})
CLI_CAL_ERROR = (REJECT)
例外エラーにします。
演算結果をNULLにします。
データベースシステムの文字コード系が、アプリケーションで使用している文字コード系と異なる場合、コード変換をクライアントで行うか、サーバで行うかを指定します。
CLI_CHARACTER_TRANSLATE = ({CLIENT | SERVER})
CLI_CHARACTER_TRANSLATE = (SERVER)
クライアントでコード変換を行う場合に指定します。
サーバでコード変換を行う場合に指定します。
注意
サーバの負荷を少しでも減らしたい場合は、クライアントで行うよう指定します。
簡略化した格納構造定義を行う場合、インデックスのベース部とインデックス部の割り付け量、ページ長などを指定します。
CLI_DEFAULT_INDEX_SIZE=(
ベース部ページ長,
インデックス部ページ長,
ベース部初期量,
インデックス部初期量
[,拡張量,拡張契機])
システム用の動作環境ファイルの、DEFAULT_INDEX_SIZEの指定値
ベース部のページ長を1、2、4、8、16、32の中から指定します。
インデックス部のページ長を1、2、4、8、16、32の中から指定します。
ベース部の初期量を2~2097150の範囲で指定します。
単位はキロバイトです。
インデックス部の初期量を2~2097150の範囲で指定します。
単位はキロバイトです。
インデックスのベース部とインデックス部の拡張量を1~2097150の範囲で指定します。
単位はキロバイトです。
省略した場合、32になります。
インデックス部の拡張量は、ベース部の5分の1の値となります。
ベース部とインデックス部の拡張を行うタイミングとして、DSIの空き容量を0~2097150の範囲で指定します。
インデックスのDSIの空き容量がここで指定した値になると、ベース部とインデックス部の拡張が行われます。
単位はキロバイトです。
省略した場合、0になります。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
ベース部の5分の1がインデックス部のページ長の倍数でない場合、インデックス部のページ長の倍数に繰り上げます。
簡略化した格納構造定義を行う場合、OBJECT構造の表の、データ格納域の割り付け量、ページ長などを指定します。
CLI_DEFAULT_OBJECT_TABLE_SIZE = (
ページ長,
初期量
[,拡張量,拡張契機])
システム用の動作環境ファイルの、DEFAULT_OBJECT_TABLE_SIZEの指定値
データ格納域のページ長を指定します。
必ず32を指定します。
データ格納域の初期量を2~2097150の範囲で指定します。
単位はキロバイトです。
データ格納域の拡張量を1~2097150の範囲で指定します。
単位はキロバイトです。
省略した場合、32768になります。
データ格納域の拡張を行うタイミングとして、表のDSIの空き容量を0~2097150の範囲で指定します。
表のDSIの空き容量がここで指定した値になると、データ格納域の拡張が行われます。
単位はキロバイトです。
省略した場合、0になります。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
簡略化した格納構造定義を行う場合、表のデータ格納域の割り付け量、ページ長などを指定します。
CLI_DEFAULT_TABLE_SIZE = (
ページ長,
初期量
[,拡張量,拡張契機])
システム用の動作環境ファイルの、DEFAULT_TABLE_SIZEの指定値
データ格納域のページ長を1、2、4、8、16、32の中から指定します。
データ格納域の初期量を2~2097150の範囲で指定します。
単位はキロバイトです。
データ格納域の拡張量を1~2097150の範囲で指定します。
単位はキロバイトです。
省略した場合、64になります。
データ格納域の拡張を行うタイミングとして、表のDSIの空き容量を0~2097150の範囲で指定します。
表のDSIの空き容量がここで指定した値になると、データ格納域の拡張が行われます。
単位はキロバイトです。
省略した場合、0になります。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
データ操作で、DSIに指定された拡張契機(rdbalmdsiコマンドまたはDSI定義文で定義します)を無視するかどうかを指定します。
CLI_DSI_EXPAND_POINT=({ON | OFF})
CLI_DSI_EXPAND_POINT=(ON)
DSIに定義された拡張契機は有効になります。
データ操作で、DSIの空きページ容量が拡張契機に達した時点で、領域を拡張します。
DSIに定義された拡張契機は無効になります。
データ操作で、DSIの空きページ容量が拡張契機に達しても、領域を拡張しません。この場合、DSIの空き領域が枯渇した時点で、領域を拡張します。
使用するDSOおよびその占有の単位、占有モードを指定します。
CLI_DSO_LOCKが指定された場合、ConnectionインタフェースのsetTransactionIsolationメソッドは指定できません。
また、システム用の動作環境ファイルのR_LOCKおよびctuneparamオプションのCLI_R_LOCKの値により、CLI_DSO_LOCKを指定できない場合があります。以下にCLI_DSO_LOCKとR_LOCKおよびCLI_R_LOCKの関係を示します。
ctuneparamオプションのCLI_R_LOCK | システム用の動作環境ファイルのR_LOCK | CLI_DSO_LOCKの指定 | 占有単位 |
|---|---|---|---|
NO | NO | 指定可 | CLI_DSO_LOCKの指定による |
YES | 指定可 | CLI_DSO_LOCKの指定による | |
YES | NO | 指定不可 | 行単位で占有(注) |
YES | 指定不可 | 行単位で占有(注) | |
省略 | NO | 指定可 | CLI_DSO_LOCKの指定による |
YES | 指定不可 | 行単位で占有(注) |
注) CLI_DSO_LOCKを指定した場合、データベースへの接続時にエラーとなります。
CLI_DSO_LOCK = (DSO名[/[P][占有モード]][,DSO名[/[P][占有モード]]・・・])
使用するDSO名を以下の形式で指定します。
データベース名.DSO名
DSOの占有単位をページにします。
省略した場合、占有の単位はDSIになります。
占有のモードとして以下のどちらかを指定します。省略した場合、EXになります。
EX:
更新モードの排他を行います。
SH:
参照モードの排他を行います。
データベースを検索する時に、インデックスを使用せずにデータベースにアクセスするか否かを指定します。データウェアハウジングにおいて大量のデータを検索および集計する場合には、インデックスだけではデータが絞りきれず、インデックスを使う分だけ無駄なオーバヘッドが発生することがあります。このような場合は、当パラメタにYESを指定することにより、表の全件検索または並列スキャンのアクセスモデルを採用します。
CLI_IGNORE_INDEX = ({YES | NO})
CLI_IGNORE_INDEX = (NO)
インデックスを使用しないアクセスモデルを選択する。
インデックスが使用できる時は、インデックスを使用したアクセスモデルを選択する。
データベースを検索する時に、非活性状態のインデックスDSIを含むインデックスを使用したアクセスプランを選択するか否かを指定します。インデックスを非活性状態とし、一括更新処理でインデックスを更新しない高速なバッチ処理を行うアプリケーションの場合、当パラメタにNOを指定してください。YESが指定されている場合、バッチ処理がエラーとなる場合があります。
CLI_INACTIVE_INDEX_SCAN = ({YES | NO})
CLI_INACTIVE_INDEX_SCAN = (YES)
非活性状態のインデックスDSIを含むインデックスを使用したアクセスプランを選択する。
非活性状態のインデックスDSIを含むインデックスを使用したアクセスプランを選択しない。
DSIを限定したい表のDSI名を指定します。
限定されたDSIを含む表に対しては、そのDSIだけがデータ操作の範囲となります。また、このパラメタの指定により、探索条件の記述が省略ができます。なお、DSIを限定していない表に対しては、データ操作をすることができます。
CLI_INCLUSION_DSI = (
データベース名.DSI名
[,データベース名.DSI名・・・])
限定したい表のDSI名を指定します。
あるトランザクションで資源にアクセスしようとしたとき、別のトランザクションがその資源を占有していた場合に、資源の占有が解除されるまで待つかどうかを指定します。
CLI_ISOLATION_WAIT = ({WAIT | REJECT})
CLI_ISOLATION_WAIT = (WAIT)
資源の占有が解除されるまで待ちます。
エラーとして復帰します。
ジョインする方法を指定します。
CLI_JOIN_RULE = ({AUTO | MERGE | FETCH})
CLI_JOIN_RULE = (AUTO)
Symfoware/RDBが自動的に選択する。
マージジョインのアクセスモデルを優先する。
フェッチジョインのアクセスモデルを優先する。
結合表と他の表をジョインする場合のジョイン順を指定します。
CLI_JOIN_ORDER = ({AUTO | INSIDE | OUTSIDE})
CLI_JOIN_ORDER = (INSIDE)
Symfoware/RDBが自動的に選択する。
結合表から先にジョインする。
結合表の中に指定した表と結合表の外に指定した表から先にジョインする。
SQL文でデータベースを並列に検索する場合の多重度です。
SQL文でデータベースを並列に検索できるのは、単一行SELECT文またはカーソル宣言で並列指定を指定した場合です。
表のDSIの数が、指定した多重度よりも少ない場合は、DSIの数を多重度として並列検索を行います。
CLI_MAX_PARALLEL = (多重度)
省略した場合は、システム用の動作環境ファイルにおけるMAX_PARALLELの指定に従って並列検索(並列クエリ)を行います。
2~100の範囲で指定します。
同一Connectionオブジェクト内で同時に作成できる、Statementオブジェクト、PreparedStatementオブジェクト、CallableStatementオブジェクトの数を指定します。
CLI_MAX_SQL = (オブジェクトの数)
CLI_MAX_SQL = (32)
2~32000の範囲で指定します。
Statementインタフェース、PreparedStatementインタフェース、CallableStatementインタフェースを使用して、同一SQL文を複数回実行するときに、最初の実行で作成した処理手順を使用することによって処理効率の向上を図っています。
この領域は、サーバ側で獲得されます。
CLI_OPL_BUFFER_SIZE = (バッファサイズ)
SQLの処理手順を格納するバッファのサイズを1~10240で指定します。
単位はキロバイトです。
省略した場合、256になります。
注意
同一SQL文を複数回実行するとき、以下の場合については最初の実行で作成した処理手順は使用されず、新たに処理手順を作成します。
前回の実行後、保持可能な処理手順の数(CLI_MAX_SQLに指定した値と同数)以上の異なるSQL文を実行した場合
前回の実行後、SET TRANSACTION文によりトランザクションモード(アクセスモードまたは独立性水準)を変更した場合
前回の実行後、SET CATALOG文により被準備文の対象となるデータベース名を変更した場合
前回の実行後、SET SCHEMA文により被準備文の省略したスキーマ名を変更した場合
前回の実行後、SET SESSION AUTHORIZATION文によりスコープの異なる利用者に変更した場合
前回の実行後、SQL文が使用するデータベース資源についてALTER TABLE文により動的に列の追加または削除を実行した場合
前回の実行後、SQL文が使用するデータベース資源についてCREATE DSI文により動的にDSIの追加または削除を実行した場合
前回の実行後、SQL文が使用するデータベース資源についてALTER DSI文により動的にDSIの分割値変更を実行した場合
動作環境ファイルのパラメタINACTIVE_INDEX_SCANにNOを指定している場合、またはctuneparamオプションのパラメタCLI_INACTIVE_INDEX_SCANにNOを指定している場合に、前回の実行後、rdbexdsiコマンドにより任意のDSIの除外または除外の解除を実行した場合
前回の実行後、SQL文が使用するデータベース資源を削除した場合
アプリケーション単位またはコネクション単位に、データベースを並列に検索する(並列クエリ)か否かを指定します。
CLI_PARALLEL_SCAN = ({YES | NO})
CLI_PARALLEL_SCAN = (NO)
データベースを並列に検索します。この場合、そのアプリケーションの単一行SELECT文およびOPEN文を並列検索で実行できます。
ただし、以下のいずれかの条件を満たす場合、並列検索は実行されず従来のアクセス手順でデータベースにアクセスします。
- 表がDSI分割されていない、または1つのDSIに対するアクセスの場合
- クラスタキーを利用したデータベースアクセスが可能な場合
- 探索条件にROW_IDを指定した検索の場合
- インデックスを利用したデータベースアクセスが可能な場合
データベースを並列に検索しません。
ドライバのリカバリ水準を指定します。
CLI_RCV_MODE = ({RCV | NRCV})
CLI_RCV_MODE = (RCV)
リカバリ機能を利用します。
この場合、リカバリを適用しないデータベースをアクセスすることはできますが、ログは取得されません。
リカバリ機能を利用しません。
この場合、リカバリを適用するデータベースを更新することはできません。
占有の単位を行にするかどうかを指定します。
CLI_R_LOCKにYESが指定された場合、以下の指定はできません。
サーバ用の動作環境ファイルのDSO_LOCK
ctuneparamオプションのCLI_DSO_LOCK
CLI_R_LOCK = ({YES | NO})
システム用の動作環境ファイルの、R_LOCKの指定値
占有の単位を行にします。
占有の単位は、CLI_DSO_LOCKの指定に従います。
このパラメタを指定し、かつDSO_LOCKが指定されていない場合は、Symfoware Serverによって自動的に占有の単位が選択されます。
注意
動作環境ファイルのR_LOCKがNOで、ConnectionインタフェースのsetTransactionIsolationメソッドを省略、またはConnectionインタフェースのsetTransactionIsolationメソッドでTRANSACTION_REPEATABLE_READを指定した場合、独立性水準はSERIALIZABLEとなります。
動作環境ファイルのR_LOCKがYESで、ConnectionインタフェースのsetTransactionIsolationメソッドを省略、またはConnectionインタフェースのsetTransactionIsolationメソッドでTRANSACTION_SERIALIZABLEを指定した場合、独立性水準はREPEATABLE READとなります。
ROUTINE_SNAP機能を利用するかどうかを指定します。
CLI_ROUTINE_SNAP = ({ON | OFF},ファイル名[,出力レベル])
CLI_ROUTINE_SNAP = (OFF)
ROUTINE_SNAP機能を利用する場合に指定します。
ROUTINE_SNAP機能を利用しない場合に指定します。
SQL手続き文の実行情報の出力先のサーバ側のファイル名を、絶対パスで指定します。
指定されたファイルがすでに存在する場合、情報を追加して出力します。
出力する情報のレベルとして、1または2を指定します。
省略した場合、2になります。
JDBCドライバは、データを取り出すときの性能を良くするため、複数の行を一度に取り出し、JDBCドライバ内部に格納することができます。
この行を格納するバッファの数とサイズを指定します。
単位はキロバイトです。
また、1つのカーソルが1つのバッファを使用するので、複数のバッファを用意すれば、複数カーソルの操作の性能を良くすることができます。
バッファを使用しない場合、個数に0を指定します。
この領域は、クライアント側とサーバ側で獲得されます。
バッファサイズを大きくするほど性能は良くなりますが、メモリが圧迫され、他のアプリケーションの実行に支障が発生する場合があります。
バッファサイズを大きくする場合、メモリの空き容量に注意してください。
CLI_RESULT_BUFFER = (個数,サイズ)
使用するバッファの個数を0~255で指定します。
省略した場合、2になります。
使用するバッファのサイズを1~10240で指定します。
単位はキロバイトです。
省略した場合、32になります。
四則演算の検索範囲について、インデックス範囲検索、または、クラスタキーの検索を行うか否かを指定します。
CLI_SCAN_KEY_ARITHMETIC_RANGE = ({YES | NO})
CLI_SCAN_KEY_ARITHMETIC_RANGE = (YES)
四則演算の検索値について、インデックス範囲検索、または、クラスタキーの検索を行います。
四則演算の検索値について、インデックス範囲検索、または、クラスタキーの検索を行いません。
探索条件のCASTオペランドに指定した列でインデックスの範囲検索、または、クラスタキー検索を行うか否かを指定します。
CLI_SCAN_KEY_CAST = ({YES | NO})
CLI_SCAN_KEY_CAST = (YES)
探索条件のCASTオペランドに指定した列でインデックスの範囲検索、または、クラスタキー検索を行います。
探索条件に指定したインデックスキーまたは、クラスタキーで範囲検索を行います。
使用するサーバ用の動作環境ファイル名を指定します。
コネクションごとにサーバの実行環境を変更する場合に指定します。
CLI_SERVER_ENV_FILE = (SQLサーバ名,ファイル名)
接続するデータ資源名を記述します。
サーバ用の動作環境ファイル名を、絶対パスで指定します。
ソート処理がレコードをハッシングして格納するための領域のサイズです。
単位はキロバイトです。
CLI_SORT_HASHAREA_SIZE = (メモリサイズ)
省略した場合は、メモリ上のすべてのレコードをハッシングして格納します。
2112~2097150の範囲で指定します。
ソート処理のために作業用ソート領域としてサーバ側で使用するメモリの大きさを指定します。
省略した場合、システム用の動作環境ファイルにおけるSORT_MEM_SIZEの指定に従います。
この領域は、RDBプロセスのローカルメモリにセション単位に獲得されます。
CLI_SORT_MEM_SIZE = (メモリサイズ)
サーバ側で使用するメモリの大きさを64~2097150の範囲で指定します。
単位はキロバイトです。
予約語のレベルを設定します。
予約語のレベルを設定することで、キーワードの範囲を変更できます。
ファンクションルーチンおよびロールを利用する場合は、SQL2000が指定されていなければなりません。
プロシジャルーチンで、条件宣言、ハンドラ宣言、SIGNAL文およびRESIGNAL文を利用する場合は、SQL2000が指定されていなければなりません。これらを利用しないプロシジャルーチンの場合は、SQL95、SQL96またはSQL2000のいずれかを指定します。
トリガ、行識別子または並列指定を利用する場合、SQL96またはSQL2000を指定します。
CLI_SQL_LEVEL = ({SQL88 | SQL92 | SQL95 | SQL96 | SQL2000})
CLI_SQL_LEVEL = (SQL2000)
予約語のレベルをSQL88とします。
予約語のレベルをSQL92とします。
予約語のレベルをSQL95とします。
予約語のレベルをSQL96とします。
予約語のレベルをSQL2000とします。
アプリケーション単位でSQL性能情報を取得するかどうかを指定します。
CLI_SQL_TRACE = ({ON | OFF},性能情報ファイル名[,出力レベル])
CLI_SQL_TRACE = (OFF)
SQL性能情報取得機能を利用する場合に指定します。
SQL性能情報取得機能を利用しない場合に指定します。
出力先のサーバ側のファイル名を、絶対パスで指定します。指定されたファイルがすでに存在する場合は、情報を追加して出力します。
複数のアプリケーションが動作する場合は、個別のトレース情報を出力しません。
アプリケーションがマルチスレッド環境で動作する場合は、出力ファイル名の後にプロセスIDやセションIDなどの情報を自動的に付加して、個別のトレース情報を出力します。
出力レベルには1または2を指定します。1を指定すると、DSOごとに集計された性能情報を出力します。2を指定すると、DSI単位の情報までも出力します。
省略した場合は、2が指定されたものとみなします。
BETWEEN述語、比較述語、LIKE述語およびCONTAINS関数でインデックスを検索する時、インデックスの検索範囲の割合を0以上1以下の小数で指定します。値は、小数第6位まで指定できます。
CLI_SS_RATE = ([選択率1][,[選択率2][,[選択率3][,[選択率4][,[選択率5]]]]])
BETWEEN述語を指定した場合のインデックスの検索範囲。
省略値は、0.2
比較述語“>”、“>=”、と“<”、“<=”でインデックスの検索開始位置および検索終了位置の両方が指定されている場合のインデックスの検索範囲。
省略値は、0.25
比較述語“>”、“>=”、“<”、“<=”でインデックスの検索開始位置または検索終了のみが指定されている場合のインデックスの検索範囲。
省略値は、0.5
LIKE述語を指定した場合のインデックスの検索範囲。
省略値は、0.4
CONTAINS関数を指定した場合のインデックスの検索範囲。
省略値は、0.0001
一時表にインデックスを定義する場合に、インデックスのベース部とインデックス部の割付け量を指定します。単位はキロバイトです。
CLI_TEMPORARY_INDEX_SIZE = (ベース部初期量,インデックス部初期量[,拡張量,拡張契機])
この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるTEMPORARY_INDEX_SIZEの指定に従います。
ベース部の初期量を64~2097150の範囲で指定します。
インデックス部の初期量を64~2097150の範囲で指定します。
インデックスのベース部の拡張量を32~2097150の範囲で指定します。インデックス部の拡張量は、ベース部の5分の1の値となります。
ベース部およびインデックス部の拡張を行うタイミングとして、インデックスの空き容量を0~2097150の範囲で指定します。つまり、インデックスの空き容量がここで指定した値になると、インデックスのベース部およびインデックス部の拡張が行われます。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
ベース部の5分の1がインデックス部のページ長の倍数でない場合、インデックス部のページ長の倍数に繰り上げます。
一時表を定義する場合に、表のデータ格納域の割付け量を指定します。
単位はキロバイトです。
CLI_TEMPORARY_TABLE_SIZE = (初期量[,拡張量,拡張契機])
この実行パラメタを省略した場合は、システム用の動作環境ファイルにおけるTEMPORARY_TABLE_SIZEの指定に従います。
データ格納域の初期量を64~2097150の範囲で指定します。
データ格納域の拡張量を32~2097150の範囲で指定します。
データ格納域の拡張を行うタイミングとして、表の空き容量を0~2097150の範囲で指定します。
つまり、表の空き容量がここで指定した値になると、表のデータ格納域の拡張が行われます。
注意
自動容量拡張の拡張量と拡張契機は、ページ長単位に繰り上げますので、ページ長の倍数で指定してください。
インデックス検索と表データ取得のアクセスモデルにおいて、TIDソートを利用するか否かを指定します。
CLI_TID_SORT = ({YES | NO})
CLI_TID_SORT = (YES)
TIDソートを利用する。
TIDソートを利用しない。
TIDユニオンマージのアクセスモデルを有効にするか否かを指定します。
CLI_TID_UNION = ({YES | NO})
CLI_TID_UNION = (YES)
TIDユニオンマージのアクセスモデルを有効にする。TIDユニオンマージが効果的と判断した場合に選択する。
TIDユニオンマージのアクセスモデルを有効にしない。
SQL文が実行中にエラーとなった場合のトランザクションの対処方法を指定します。
CLI_TRAN_SPEC = ({NONE | TRANSACTION_ROLLBACK})
CLI_TRAN_SPEC = (NONE)
各プラットフォームのトランザクションの仕様に従います。
SQL文の実行がエラーとなった場合、トランザクションをロールバックします。
1つのトランザクションで使用可能な時間を指定します。単位は秒です。0を指定すると無制限になります。指定時間を超過した場合には、トランザクションをロールバックして、接続中のコネクションを切断します。
CLI_TRAN_TIME_LIMIT = (最大トランザクション実行時間)
CLI_TRAN_TIME_LIMIT = (0)
最大トランザクション実行を0~32767で指定します。
UPDATE文:探索およびDELETE文:探索において、更新レコードを検索するアクセスモデルの表の占有モードを指定します。
CLI_USQL_LOCK = ({SH | EX})
CLI_USQL_LOCK = (SH)
更新標的レコードを検索するアクセスモデルで共用モードで表を占有する。
更新標的レコードを検索するアクセスモデルで非共用モードで表を占有する。
サーバからのデータ受信の待ち時間を指定します。
単位は秒です。
このパラメタで指定された時間内に、サーバからのデータが受信できなかった場合、実行中のSQL文はエラーとなり、コネクションは切断されます。
0を指定した場合、データが受信できるまで待ちます。
CLI_WAIT_TIME = (待ち時間)
CLI_WAIT_TIME = (0)
待ち時間を0~32767で指定します。
注意
Solaris 9上でサーバからのデータ受信の待ち時間を監視したい場合は、接続先情報にリモートアクセス(RDB2_TCP連携)を指定してください。
作業用ソート領域および作業用テーブルとしてサーバ側で使用するファイルサイズの初期量、増分量、最大量、保持指定を指定します。単位はキロバイトです。
CLI_WORK_ALLOC_SPACESIZE = ([初期量][,[増分量][,[最大量][,[保持指定]]]])
CLI_WORK_ALLOC_SPACESIZE = (10000,50000,,HOLD)
作業用ソート領域および作業用テーブルとして外部ファイルを作成する場合の初期量を5000~50000の範囲で指定します。
省略した場合は10000が指定されたとみなします。
作業用ソート領域および作業用テーブルとして作成した外部ファイルを拡張する場合の増分量を1000~100000の範囲で指定します。
省略した場合は、50000が指定されたとみなします。
作業用ソート領域および作業用テーブルとして作成する外部ファイルの最大量を5000~2000000の範囲で指定します。
省略した場合は、WORK_PATHで指定したパス名のディスク容量となります。
以下の中から1つを選択します。省略した場合は、HOLDが指定されたものとみなします。
- FREE:作業用ソート領域および作業用テーブルとして作成した外部ファイルを初期量まで解放します。
- HOLD:作業用ソート領域および作業用テーブルとして作成した外部ファイルを保持します。