SCANエレメントは、データベースやソートテーブル、ワークテーブルからデータを取り出す処理単位です。データの取出し方法には、複数のアクセス方式があります。
アクセス方式 | アクセス対象 |
|---|---|
データベースの表 | |
データベースの表 ソートテーブル ワークテーブル | |
データベースの表 | |
インデックス | |
インデックス | |
データベースの表とインデックス |
データベースの表の目的のレコードを、表のクラスタキー値あるいはレコードの格納アドレスで検索するアクセス方式です。レコードの格納アドレスはTID(Tuple ID)と呼びます。
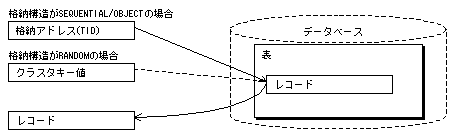
レコードのTIDでレコードを取り出します。TIDは、表の格納構造がSEQUENTIALまたはOBJECTの場合に、インデックスのデータ部に表レコードとの関係付けのために格納されています。
表の格納構造がRANDOMの場合、クラスタキー値を作成して、目的のレコードが格納されているバケットを位置づけて、バケット中のレコード群から目的のレコードを取り出します。クラスタキー値は、RANDOM構造の表の場合に、インデックスのデータ部に表レコードとの関係付けのために格納されています。
SQL文のWHERE探索条件に表のクラスタキー値を一意に指定するような条件を指定すると、指定した条件からクラスタキー値を作成して、TABLE KEY SCAN(クラスタキー値検索)を行うことができます。
クラスタキー値を利用したTABLE KEY SCANができる場合(TBL1の格納構造はRANDOMで、クラスタキーを(C1,C2)とします。)
SELECT * FROM TBL1 WHERE C1 = 1................(注) AND C2 = 1................(注) 注)クラスタキー値を作成してTABLE KEY SCAN
クラスタキー値を利用したTABLE KEY SCANができない場合(TIの格納構造はRANDOMで、クラスタキーを(C1,C2)とします。)
SELECT * FROM TBL1 WHERE C1 = 1................(注) AND C2 > 1................(注) 注)条件を“=”またはIN述語で与えないと、クラスタキー値を一意に指定できません。
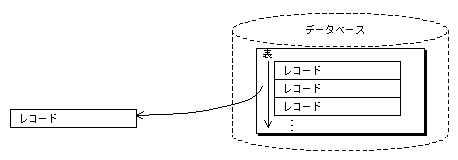
表やソートテーブルまたはワークテーブルの全レコードを取り出すアクセス方式です。
複数のDSIに分割されたデータベースを並列に同時に検索してデータを取り出すアクセス方式です。
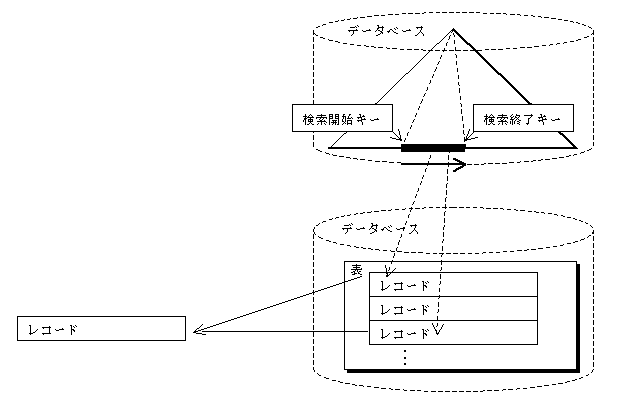
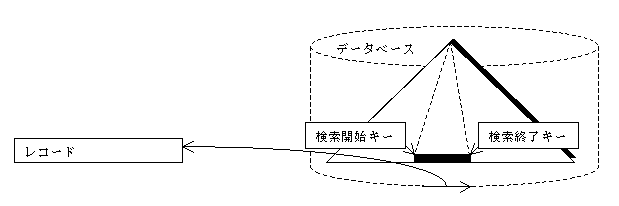
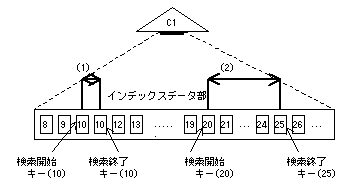
インデックスに対して、検索範囲(検索開始キーまたは検索終了キー)を指定して、その範囲にあるインデックスデータ部のレコードを検索するアクセス方式です。
インデックスの検索範囲は、SQL文に指定したWHERE探索条件から生成します。
インデックスの検索範囲の検索開始キー値、検索終了キー値の生成は、次のように行います。
なお、下表では列“C1”を先頭に持つインデックスを想定しています。:Hはホスト変数を表現しています。
条件の種別 | インデックスの検索範囲 | 備考 |
|---|---|---|
比較述語 = | 例 C1 = :H |
|
比較述語 >(=) | 例 C1 >= :H |
|
比較述語 <(=) | 例 C1 <= :H |
|
BETWEEN述語 | 例 C1 BETWEEN :H1 AND :H2 |
|
IN述語 | 例 C1 IN (:H1, :H2, ‥) | 複数範囲となる。 |
LIKE述語 | 例 C1 LIKE :H | “%”、“_”またはESCAPE文字までの文字列より,検索開始キー、検索終了キーを生成する。 |
NULL述語 | 例 C1 IS NULL | NULL値データを検索する検索開始キー値、終了キー値を生成する。 |
同一の列に対して複数の条件をブール演算子“AND”でつないだ場合、検索範囲の検索開始キーまたは検索終了キーはデータベースアクセス前にマージされ、作成された範囲のデータのみを検索します。
インデックスの検索範囲は下図のようになる。
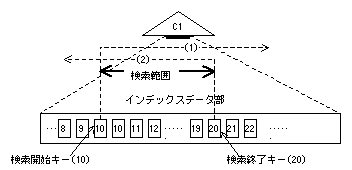
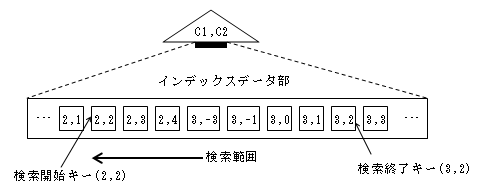
同一の列に対して複数の条件をブール演算子“OR”でつないだ場合、複数の検索範囲が生成され、各検索範囲のデータを検索します。
インデックスの検索範囲は下図のようになる。
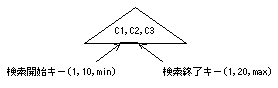
複数列から構成されるインデックスは、インデックスの構成列(複数の列)でインデックスのキー値を構成し、インデックスのデータ部にはこのキー値の昇順にデータが格納されています。マルチカラムインデックスの検索範囲は、この複数列で検索開始キーおよび検索終了キーを作成して、その範囲のデータを検索します。
WHERE C1 BETWEEN 2 AND 3 AND C2 = 2の場合
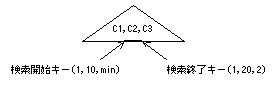
複数列から構成されるインデックスのn番目の構成列が検索範囲として有効でない場合は、その列の取りうる最小値および最大値を補って検索範囲を作成します。
WHERE C1 = 1 AND C2 BETWEEN 10 AND 20の場合
WHERE C1 = 1 AND C2 > 10 AND C2 <=20 AND C3 = 2の場合
WHERE C1 = 1 AND (C2 = 2 OR C2 = 3) AND C3 > 4の場合
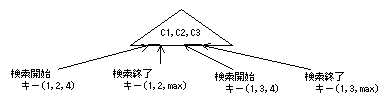
WHERE C1 > 1 AND C2 = 1 AND C3 = 1の場合

参考
インデックスキー順について
第1構成列に条件が指定されないような、複数列から構成されるインデックスは、検索範囲を作成できません。

比較述語“=”で条件を指定する列を優先的に先頭に配置したほうが、検索するデータ量が少なくなり、効果的です。

インデックスのデータ部の全データを検索するアクセス方式です。
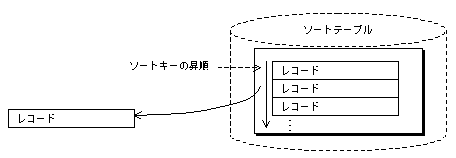
インデックスのデータ部の全レコードを読み込み、インデックスのキー値の昇順でデータを取り出します。
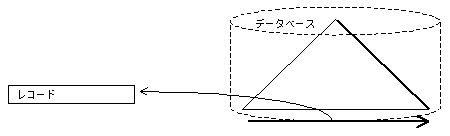
インデックスを範囲検索しながら、同時に対応する表のレコードも取り出すアクセス方式です。