

| PRIMECLUSTER 活用ガイド <トラブルシューティング編> (Solaris(TM)オペレーティングシステム/Linux版) |
|
目次
索引
|
| 第1部 事象別トラブル | > 第3章 運用時のトラブル |
RMS の使用中に発生する問題の解決方法について説明します。
以下の現象が発生した場合は、該当する問題の対処方法を試してください。
RMS で異常が発生した場合、トラブルシューティングのための情報を含んだエラーメッセージが出力されます。メッセージの内容を確認し、その内容に従った対処を行ってください。
|
No. |
現象 |
Solaris |
Linux |
|---|---|---|---|
|
ユーザアプリケーションを削除したにもかかわらず、削除前の情報が表示される |
○ |
○ |
|
|
RMS 起動時に毎回ファイルシステムの fsck が行われる |
○ |
− |
|
|
RMS が起動後にハングする ( プロセスは実行中だが、hvdisp がハングする) |
○ |
○ |
|
|
RMS が起動直後にループする ( 停止する場合もある) |
○ |
○ |
|
|
RMS がノードの障害を検出しても (network connection failed to host/ ...)、ノードを停止しようとしない |
○ |
○ |
|
|
hvcm コマンドを使用してRMS を起動した場合に、クラスタアプリケーションに登録しているアプリケーションの機能がパーミッションエラーとなる |
○ |
○ |
|
|
RMS のログ格納ディレクトリ (/var/opt/SMAWRrms/log) に格納されている RMS ログファイルが削除される |
○ |
○ |
|
|
RMS 間のハートビートが切断されてから、相手ノードを強制停止するまでの時間を変更したい |
○ |
○ |
|
|
RMS を起動させると、RMS(BM, 82) のメッセージが出力され RMS が停止し、他ノードより強制停止 (panic/sendbreak/reset) される |
○ |
○ |
|
|
運用中に以下のメッセージが表示され、ノードがパニックした |
○ |
○ |
|
|
RMS を起動すると、RMS (WRP, 34) のメッセージが表示されてハートビートが切断し、ノードが強制停止 (panic/sendbreak/reset) される |
○ |
○ |
|
|
スケーラブル運用のクラスタアプリケーションの状態が Wait 後、Faulted となる |
○ |
○ |
|
|
スケーラブル運用のクラスタアプリケーションが複数ノードで Online になる |
○ |
○ |
|
|
hvshut コマンドを実行すると、以下のエラーメッセージが出力された |
○ |
○ |
|
|
hvipalias ファイルに定義されていない IP アドレスが引継ぎIPアドレスとして活性化された |
○ |
− |
|
|
RMS 停止処理時に、RMS でタイムアウトが発生し、Offline 処理が行われなかった |
○ |
○ |
|
|
RMS を起動すると以下のメッセージが出力され、RMS の起動に失敗する |
○ |
○ |
|
|
"hvswitch -f" コマンドを実行した際に、"Command aborted" のメッセージが出力される |
○ |
○ |
|
|
運用中に RMS(WRP,34)、(WRP,35) のメッセージが表示される |
○ |
○ |
|
|
RMS の停止を行うと 1 台で パニックが発生した |
○ |
○ |
|
|
PRIMECLUSTER 起動時に RMS の起動に失敗し、Cluster Admin の msg タブに以下が出力される |
○ |
○ |
|
|
ノードを停止すると以下のメッセージが表示された |
○ |
○ |
|
|
RMS が起動されない |
○ |
○ |
|
|
hvshut コマンドの -l オプションを両ノードで使用して問題ないか |
○ |
○ |
|
|
運用中以下のメッセージが表示され、ノードが強制停止された |
○ |
○ |
|
|
運用中以下のメッセージが表示され、クラスタノードが Online から Offline に遷移した |
○ |
○ |
|
|
RMSを起動すると以下のメッセージが出力される |
○ |
− |
|
|
RMS の停止処理中にシステムが異常停止しても、業務が待機系に切り替わらない |
○ |
○ |
|
|
以下の条件の時、他ノードから強制停止のアクションが実行される 出力されるメッセージ: |
○ |
○ |
|
|
MAC アドレス引継ぎを設定したリソースが定義されている userApplication を起動すると、引継ぎネットワークリソースの活性化に失敗する。MAC アドレスの設定を表記しないと、正常に引継ぎネットワークリソースを活性化できる |
○ |
− |
|
|
Cmdline リソースが Online 状態にもかかわらず Start スクリプトが実行され、Cmdline リソースから呼ばれるアプリケーションが二重起動される |
○ |
○ |
|
|
Fsystem リソースに異常が発生し、フェイルオーバが発生する |
○ |
○ |
|
|
RMS 起動時に以下のメッセージが出力される |
○ |
○ |
|
|
hvswitch コマンドを実行しても、userApplication の切替えができない |
○ |
○ |
|
|
PRIMECLUSTER 動作中、/var 領域が 100% になった |
○ |
○ |
|
|
userApplication の切替えを行うとパトロール診断リソースが Fault になる |
○ |
− |
|
|
userApplication の排他設定が行われているにも関わらず、同一ノードで優先度の高い userApplication と優先度の低い userApplication が Standby -Online 状態で混在する |
○ |
○ |
|
|
手動切替時、自ノードの userApplication の Offline 処理が完了する前に、相手ノードが停止した。このため自ノードで再度userApplication が Onlineになることを期待したが、自動的に Online にならなかった |
○ |
○ |
ユーザアプリケーションを削除しても Configuration 情報の構成に矛盾がある場合、削除前の構成情報が表示されます。
RMS 構成に矛盾がないかを確認してください。
/etc/dfs/dfstab ファイルに、誤って Fsystem リソースとして設定されているファイルシステムに対する share の記述が行われている可能性があります。
クラスタアプリケーションに含まれるファイルシステムリソースをネットワークで共有 (NFS) する場合は、"PRIMECLUSTER 導入運用手引書" の "6.6.1.2.1 事前設定" の "■ファイルシステムをネットワークで共有 (NFS) する場合の準備" に従い、事前設定してください。
ローカルノードが他のクラスタノードから見て LEFTCLUSTER 状態の場合に、この問題が発生します。
すべてのクラスタノード上で cftool -n を実行し、ローカルノードの状態が LEFTCLUSTER 状態となっているか確認してください。
LEFTCLUSTER 状態となっている場合は、ローカルノードで cftool -k を実行し、LEFTCLUSTER 状態をクリアしてください。ノードがクラスタに参入したあとも、RMS は稼動し続けます。RMS を再起動する必要はありません
CIP 構成定義ファイル(/etc/cip.cf)にネットマスクのエントリが含まれている可能性があります。
RMS では、ネットマスクのエントリがあると、ネットマスクを IP アドレスと判断してホスト名を検索する処理を行うため処理が停止します。
ネットマスクのエントリが /etc/cip.cf に存在することを調べてください。
ネットマスクのエントリを削除して、RMS を再起動してください。
過去の停止要求が失敗したときからノードが Wait 状態になっている場合に、この問題が発生します。

Wait 状態の SysNode に対する停止要求が失敗すると、システム管理者がこの状態を手動でクリアするまで、Wait 状態は変化しません。
hvdisp -T SysNode を使用してすべての SysNode オブジェクトの状態を確認してください。
(hvdisp コマンドの実行には、ルート権限は必要ありません。)
SysNode が Wait 状態であることを確認したら、hvutil -o SysNode または hvutil -u SysNode を実行します。
hvutil -u を実行すると、正常なノードは SysNode が停止しているものとみなし、直ちにフェイルオーバを起動します。このとき、ノードがアクティブの場合は、データが破損する可能性があります。必ず、ノードを停止させてからコマンドを実行してください。
hvutil -o を実行すると、正常なノードは SysNode が稼動しているものとみなします。したがって、正常なノードはリモート SysNode と同期がとられているものと想定して動作します。正常に動作していない場合は、本コマンドを実行しないでください。データが破損する可能性があります。
hvcm コマンドを使用して RMS を起動すると、クラスタが起動するプロセスの実グループID と実効グループ ID は 1(other) になります。よって、起動するクラスタサービスの実効グループID が 0(root) でなければならない場合は、hvcm(1M) コマンドで RMS を起動する際に、スーパーユーザ権限で、以下を実行して実効グループを変更してください。
|
# newgrp root |
hvcm(1M) コマンドのオプション:hvcm(1M) コマンドに指定するオプションを指定します。
hvcm(1M) コマンドのオプションの指定方法については、hvcm(1M) コマンドのオンラインマニュアルを参照してください。
InterAPLINK を使用している場合は、グループ ID が 0(root) でなければならないため RMS の起動を Cluster Admin GUI から行うか、上記方法で hvcm コマンドを実行してください。
RMS ログファイルは、RMS の環境変数 HV_LOG_ACTION、HV_LOG_ACTION_THRESHOLD、HV_LOG_WARN_THRESHOLD、RELIANT_LOG_LIFE の設定内容に従って、保持日数、サイズがチェックされ、古いログは自動的に削除されます。
RMS の環境変数 HV_LOG_ACTION、HV_LOG_ACTION_THRESHOLD、HV_LOG_WARN_THRESHOLD、RELIANT_LOG_LIFE の設定内容を確認し、運用に合わせて変更してください。
RMS を起動する hvcm コマンドにおいて、-h オプションと変更したい時間(秒)を指定して実行することで変更できます。なお、本オプションを指定しない場合のデフォルトは 45 秒です。
例)相手ノードを強制停止するまでの時間を 100 秒に変更する場合
# hvcm -c config -h 100 -a <Return>
なお、本オプションを指定しない場合のデフォルトはバージョンにより異なり、以下のとおりです。
クラスタインタコネクトを使用したノード間の通信ができていません。その原因として、OS 起動時に、クラスタインタコネクトが使用する NIC が、half-duplex で起動している可能性があります。
ノード間の通信が確実に行われるようにしてください。
Switching Hub の Port の設定、またはノードの NIC の negotiation の設定を見直してください。
その後、ローカルの RMS モニタを再起動してください。
RMS のハートビートが切れたため相手ノードを強制停止したと考えられます。
RMS ではハートビート切れを検出すると、45 秒間ハートビートの復旧を待ちますが、45 秒間経過しても、復旧しなかった場合、相手ノードを強制停止します。
システムの負荷など、ハートビート切れとなる要因が発生していないか確認し、その原因の対処を行なってください。
RMS のハートビート監視時間を変更したい場合は、RMS を起動する際、-hオプションで監視時間を指定してください。
クラスタインタコネクトを使用したノード間の通信ができていません。
ノード間通信が失敗した原因として、RMS(WRP, 39) のメッセージが表示されている場合は、メモリ不足などの I/O 負荷やシステム負荷が発生している可能性があります。
I/O 負荷やシステム負荷がないか確認し、負荷を取り除いてください。
また、/tmp の空き領域が少ない場合、メモリ不足が発生したり、RMS がエラーとなりますので、/tmp の使用状況を確認し、/tmp の領域を空けてください。
排他関係を設定したスタンバイ運用で構成するスケーラブル運用のクラスタアプリケーションにおいて、スケーラブル運用のクラスタアプリケーションの状態が Wait 後、Faulted となる場合があります。
以下の条件の場合、スケーラブル運用のクラスタアプリケーションの状態が Wait 後、Faulted となります。
例)
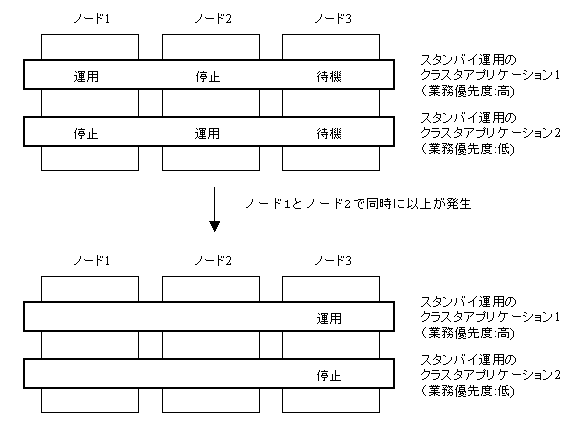
ノード 1 とノード 2 で異常が発生し、スタンバイ運用のクラスタアプリケーション 2 で運用となれるノードが存在しないため、スケーラブル運用のクラスタアプリケーションが Wait 後、Faulted となります。
"説明" に記載した条件にあてはまる場合、すべてのスタンバイ運用のクラスタアプリケーションが運用状態になるまでの間、スケーラブル運用のクラスタアプリケーションの状態は Wait となり、タイムアウト時間が経過すると Faulted となります。
タイムアウト時間はスケーラブル運用のクラスタアプリケーションの ScriptTimeout 属性値です。
スケーラブル運用のクラスタアプリケーションが Faulted となった後にスケーラブル運用のクラスタアプリケーションの Faulted をクリアしてください。
例)
# hvutil -c スケーラブル運用のuserApplication名
また、ノード異常やリソース故障を解消した後、スタンバイ運用のクラスタアプリケーションが Online となるように切替えを行ってください。"説明" に記載した例の場合、ノード 1 またはノード 2 の異常を解消し、起動した後、スタンバイ運用のクラスタアプリケーション2をノード1またはノード 2 が Online となるよう切替えを行ってください。
例)
# hvswitch スタンバイ運用のuserApplication名 ノード1のSysNode名
スケーラブル運用のクラスタアプリケーションが Online となっているノードがパニックなどの要因で異常停止後の再起動時において、OS 起動中に hvcm コマンドの実行または ClusterAdmin で RMS を起動した場合に発生します。
OS 起動中に RMS を起動してしまった場合には、RMSを起動してしまったノードで Online となっているスケーラブル運用のクラスタアプリケーションを Offline に切替えてください。
例)
# hvutil -f RMSを起動したOnlineとなっているスケーラブルのuserApplication名
また、RMS の起動は OS 起動完了(通常運用している OS ランレベルの最後の起動スクリプトの実行が完了)を管理者が確認したあとに実施することで回避できます。
hvshut コマンド自体がタイムアウトしたことを意味しています。
RMS の環境変数である RELIANT_SHUT_MIN_WAIT を適切な値に変更してください。
引継ぎ IP アドレスを定義するためのファイルである、/etc/hosts が /etc/inet/hosts に正常にシンボリックリンクが張られていないことが原因です。
シンボリックリンクを張り直してください。
RMS 環境変数に従い RMS の停止処理にてタイムアウトが発生したことは、PRIMECLUSTER の正常な動作です。
環境に適した hvshut コマンドのタイムアウト値が環境変数に設定されているかを確認してください。
クラスタアプリケーションに登録されてないリソースが残っている可能性があります。
または、クラスタアプリケーションを作成していない可能性があります。
必要に応じて、該当するリソースをクラスタアプリケーションに登録するか、リソースを削除してください。
または、クラスタアプリケーションを作成してください。クラスタアプリケーションの概要と作成方法については、"PRIMECLUSTER 導入運用手引書" を参照してください。
"hvswitch -f" コマンドを実行後の応答メッセージに対して、オペレータの入力誤りがあったと考えられます。
"Do you wish to proceed ? (default: no) [yes, no]: "のメッセージが出力後、正しい入力を行ってください。
NTP サーバとネットワーク接続されていない可能性があります。
NTP サーバとネットワーク接続してください。また、NTP の設定が正しく行われているか確認してください。
クラスタアプリケーションの HaltFlag 属性に "Yes" を設定している場合で、クラスタアプリケーションの Offline 処理で、リソースの異常が発生したために最終的に panic している可能性があります。
/var/adm/messagesで、リソース異常のエラーが出力されていないか確認してください。リソース異常が発生していた場合は、リソース異常の原因を調査し、正常になるよう対処してください。
クラスタインタコネクトで使用しているインタフェースにおいて、OS 起動時に IP アドレスを活性化する設定がされている場合、CF の起動に時間がかかり、RMS やクラスタリソース管理機構が正常に動作できないことがあります。
クラスタインタコネクトで使用しているインタフェースにおいて、OS 起動時に IP アドレスを活性化しないように、OS の設定を変更してください。
RMS を停止しないで、ノードを shutdown させた場合、RMS の停止処理を実行する旨のメッセージが出力されます。
対処は不要です。ノードを停止する場合は、事前に RMS を停止させてください。
リソース作成後、クラスタアプリケーションを作成していない可能性があります。
あるいは、userApplication に登録していないリソースが存在する可能性があります。
クラスタアプリケーションを作成してください。
あるいは、userApplication に登録していないリソースがある場合は、登録してください。リソースを RMS で使用しない場合は、削除してください。
hvshut コマンドの -l オプションを両ノードで使用しても問題ありません。
なお、両ノード同時に hvshut を実行したい場合は、-a オプションを使用してください。
RMS 間のハートビートが途切れ、<time> 秒以上たっても応答がないため、相手ノードを強制停止したと考えられます。
以下の要因が考えられます。要因に従って対処を行ってください。
LAN カード交換、ケーブル交換などを行い、ハード故障の要因を取り除いてください。
<SysNode> のホストが高負荷となっている処理を見直してください。
クラスタホスト <hostname> で異常が発生したか、<hostname> が高負荷状態で 3 秒以上ハートビートをやり取りできないことが考えられます。
強制停止が実行される前に表示される警告です。頻繁に出力されてもノードが強制停止されない場合は、ノード間通信や業務負荷が高いと考えられます。システムの状態を調査分析し、問題を取り除いてください。
SYS,88 が定期的に発生する場合はその時刻に cron などの自動的な処理により CPU に負荷がかかっている可能性があります。
sar コマンドなどで CPU の負荷を調べた上、CPU 負荷の原因を取り除いてください。
例えば以下の手順のように CPU 負荷の原因を調査してください。
#grep "SYS, 88" /var/opt/SMAWRrms/log/switchlog を実行。
SYS, 88 は以下のように表示されます。
下記の例の場合、13 時に発生し、その後 1 時間おきに表示されています。
2005-11-17 13:00:00.000:(SYS, 88): WARNING: No heartbeat from cluster host pw400 -sn03RMS within the last 10 seconds. This may be a temporary problem caused by high system load. RMS will react if this problem persists for 35 seconds more. :==== 2005-11-17 14:00:00.000:(SYS, 88): WARNING: No heartbeat from cluster host pw400 -sn03RMS within the last 10 seconds. This may be a temporary problem caused by high system load. RMS will react if this problem persists for 35 seconds more. :==== 2005-11-17 15:00:00.000:(SYS, 88): WARNING: No heartbeat from cluster host pw400 -sn03RMS within the last 10 seconds. This may be a temporary problem caused by high system load. RMS will react if this problem persists for 35 seconds more. :====
SYS, 88 が 00 分に発生し、1 時間ごとに出力されています。1 時間ごとに起動される処理が本システムで動作している可能性があります。
00 分で1時間ごとに起動される処理があると考えられるので、00 分前後(下記例の場合は10 時)の CPU 使用率を調べます。(Solaris,Linux 共通)
例)Solaris の場合
# sar -u 1 5
09:59:56 %usr %sys %wio %idle
09:59:57 5 2 1 93
09:59:58 5 2 1 92
09:59:59 5 3 13 80
10:00:00 5 3 34 57
10:00:01 5 2 1 92
Average 5 2 10 83例)Linux の場合# sar -u 1 509:59:56 AM CPU %user %nice %system %idle 09:59:57 AM all 5.00 2.00 1.00 93.00 09:59:58 AM all 5.00 2.00 1.00 92.00 09:59:59 AM all 5.00 3.00 13.00 80.00 10:00:00 AM all 5.00 3.00 34.00 57.00 10:00:01 AM all 5.00 2.00 1.00 92.00 Average: all 5.00 2.40 10.00 82.80CPU 使用率が SYS, 88 が表示されなかった時刻と比べて著しく高かった場合、その時間の処理が CPU 負荷の原因と考えられます。
この場合、10:00:00 の wio (Solaris の場合)、system (Linux の場合) の CPU 使用率が高いので、この時間の処理が CPU 負荷の原因と考えます。
userApplication Configuration Wizard で symfoware のスケーラブルアプリケーションを作成する時、Symfoware より上位の階層に 2 つ以上のリソースが存在すると、userApplication Configuration Wizard が作成するファイルの値に誤りがあることがあります。このため、userApplication 起動時に (SCR, 25) のメッセージが出力されます。
メッセージが出力されるだけで動作に影響ありませんが、userApplication Configuretaion Wizard で作成した設定ファイルに誤りがあります。
以下の手順で変更してください。
例:DB_Symfo ファイルにリソース名 ("symfoDB") が重複定義されている場合"symfoDB.symfoDB" を 1 つにします。
[修正前]
SFW_RDBSYSLIST=nodeARMS:DB_Symfo:symfoDB.symfoDB
nodeBRMS:DB_Symfo:symfoDB.symfoDB (1 行で設定されています)
[修正後]
SFW_RDBSYSLIST=nodeARMS:DB_Symfo:symfoDB nodeBRMS:DB_Symfo:symfoDB
すべてのノードの /opt/FJSVclsfw/etc/RDBnet/ 配下のファイルについて、同様にリソース名の重複設定が行われていないか確認し、重複定義されているものについては修正を行ってください。
以下の条件の時、PRIMECLUSTER の仕様により業務は待機系に切り替わりません。
PRIMECLUSTER V41 系製品では上記と同一条件のもと、業務が待機系に切り替わるように仕様改善されています。
運用ノードの RMS 停止操作を行う前に、業務を待機系に切り替えてください。
以下の条件の時、PRIMECLUSTER の仕様により業務は待機系に切り替わりません。
PRIMECLUSTER V41 系製品では上記と同一条件のもと、業務が待機系に切り替わるように仕様改善されています。
運用ノードの RMS 停止操作を行う前に、業務を待機系に切り替えてください。
/opt/SMAW/SMAWRrms/etc/hvipalias ファイルの MAC アドレスの指定が規定のフォーマットに従っていない場合に本現象が発生する場合があります。MAC アドレスは、コロン ':' で区切られたそれぞれの数値を必ず 2 桁で表記する必要があります。
以下の例の場合、* の部分において 1 となっている箇所は 01 と記載する必要があります。
(誤)
*
node01 hikitugi_ip hme0 0xffffff00 02:1:22:33:34:40
node02 hikitugi_ip hme0 0xffffff00 02:1:22:33:34:40
(正)
node01 hikitugi_ip hme0 0xffffff00 02:01:12:23:34:40
node02 hikitugi_ip hme0 0xffffff00 02:01:12:23:34:40
Cmdline リソースに NULLDETECTOR フラグが設定されている場合、すでに Online状態であっても、userApplication の Online 処理が行われると Start スクリプトが実行されます。
アプリケーションの二重起動を防止する場合は、NULLDETECTOR フラグの使用をやめ、Cmdline リソースに Check スクリプトを設定してください。
Check スクリプトには、最低限以下の処理が必要です。
Fsystem リソースの活性化時にファイルシステムのマウントが失敗し、かつ、マウント再施行の前処理として実施した fsck の実行時にタイムアウトが発生した可能性があります。
環境によって fsck が完了するまでに必要な時間が異なります。
その環境に合った fsck が完了するまでに必要な時間を見積もり、Fsystem リソースの Timeout の設定値の見直しをしてください。
設定の変更方法については“PRIMECLUSTER 導入運用手引書”を参照してください。
リソースの活性化による userApplication の初期化に時間が掛かっている可能性があります。
その後、以下のメッセージが確認できればクラスタシステムとしては問題はないので対処は不要です。
(US, 16): NOTICE: Online processing finished!
(US, 9): NOTICE: Cluster host XXXXXXXXRMS has become online.
以下のすべての条件を満たす場合、hvswitch コマンドを実行しても SysNode の優先度が高いノードへ切替えることができません。
OnlinePriority が設定されている userApplication の切替えを行う場合は、hvswitch コマンドに SysNode 名も指定してください。
RMS 関連のログファイルの肥大化により /var 領域が 100% になったと考えられます。
RMS 関連のログファイルは、/var 領域が 98% 以上になると定期的に削除されます。
しかし、RMS から起動されたアプリケーションプログラムが標準出力と標準エラー出力に大量にログを出力した場合は、/var 領域が 100% になります。
以下の手順で RMS ログのバックアップ、削除を実施してください。
/var/opt/SMAWRrms/log 配下のログを対象に cp(1) でコピーしてください。
mv(1) は使用しないでください。
削除対象のログに対して /dev/null を cp(1) でコピーし初期化してください。
例: cp /dev/null /var/opt/SMAWRrms/log/userApp0.log
パトロール診断のディスク診断処理に時間がかかり、リソースの ScriptTimeout 以内に処理が完了しなかった可能性があります。
パトロール診断のリソースに設定されている ScriptTimeout を変更してください。
ScriptTimeout に設定する値は、以下の計算式で算出してください。
パトロール診断の監視対象となるデバイス(ディスク)が 300 個未満の場合は 300 秒を設定してください。
デバイスが 300 個以上の場合は "デバイス(ディスク)数 × 1秒" を設定してください。
ただし、パトロール診断の監視間隔は、この ScriptTimeout より大きな時間であることを確認してください。
userApplication の排他設定を行っている場合、同一ノードで 2つ以上の userApplication が同時に Online 状態にはなりません。
ただし優先度の高い userApplication が Standby 状態に遷移可能な設定の場合は、待機ノードで Offline ではなく Standby 状態になります。
例)以下のように、node1 で優先度高の userApp_0 と優先度低の userApp_1 が、Standby - Online 状態で混在する
|
|
node0 |
node1 |
|---|---|---|
|
userApp_0(優先度高) |
Online |
Standby |
|
userApp_1(優先度低) |
Offline |
Online |
不要です。
RMS は、userApplication の Offline 処理が完了した後に、切り替え先を選択します。切替先には自ノードを含まないため、自ノード以外に切替可能なノードが生存していない場合、切替処理を行いません。
hvswitch コマンドを使用し、手動で userApplication を Online にしてください。
|
目次
索引
|