Hadoopは、タスクスケジューラにより、Hadoopジョブの処理時のMapReduceスロットの使用量を制御することができます。タスクスケジューラは以下の3つから選択します。
org.apache.hadoop.mapred.JobQueueTaskScheduler【FIFOスケジューラ】
依頼された順にすべてのスロットを使用して一つずつHadoopジョブを実行します。
org.apache.hadoop.mapred.CapacityTaskScheduler【Capacityスケジューラ】
スロットの割当率を指定したキューを複数定義し、それらのキューを選択してHadoopジョブを投入することで複数同時にHadoopジョブを実行することができます。
org.apache.hadoop.mapred.FairScheduler【Fairスケジューラ】
利用可能なスロットを制限するためにHadoopジョブを実行するユーザ毎にプールが与えられます。ユーザは与えられたプールに割り当てられたスロットの範囲でHadoopジョブを実行することができます。各プールに割り当てられるスロットはプールの数に応じて均等になるよう動的に変更されます。このため複数ユーザが同時にHadoopジョブを実行することができます。
タスクスケジューラは、以下のプロパティで指定します。
プロパティ名 | 説明 | デフォルト値 | 設定ファイル |
mapred.jobtracker.taskScheduler | 使用するタスクスケジューラのクラス名を指定します。 | org.apache.hadoop.mapred.CapacityTaskScheduler | mapred-site.xml |
FIFOスケジューラ
Hadoopジョブを依頼された順に、すべてのスロットを用いて実行することができます。先行のHadoopジョブのMapタスクがすべて終了(Mapスロットをすべて解放)した時点で、後続のジョブのMapタスクが開始されます。Reduceタスクも同様です。
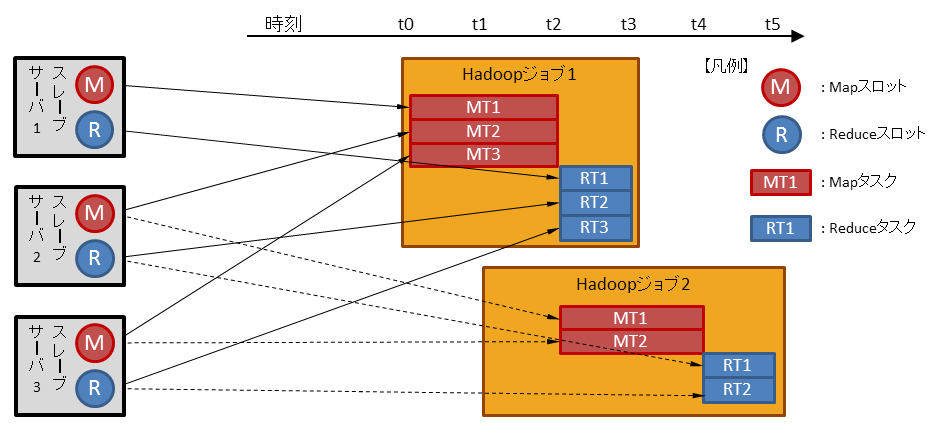
上図は、3台のスレーブサーバにMap/Reduceスロットを計3つずつ定義している場合に、2つのHadoopジョブを時間をおいて実行した例です。
時刻 t0: (Hadoopジョブ1) 実行を依頼
すべてのMapスロットを使用して、Mapタスクが開始 時刻 t1: (Hadoopジョブ2) 実行を依頼
Hadoopジョブ1でMapスロット使用中のため、Mapタスクはスロットの解放待ち 時刻 t2: (Hadoopジョブ1) Mapタスクが終了
すべてのReduceスロットを使用して、Reduceタスクが開始(Hadoopジョブ2) Mapスロットを2つ使用して、Mapタスクが開始
時刻 t3: (Hadoopジョブ1) Reduceタスクが終了し、ジョブ全体が終了
時刻 t4: (Hadoopジョブ2) Mapタスクが終了
2つのReduceスロットを使用して、Reduceタスクが開始時刻 t5: (Hadoopジョブ2) Reduceタスクが終了し、ジョブ全体が終了
参照
Hadoopジョブの実行については、以下を参照してください。
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
Capacityスケジューラ
事前に定義したキューを指定してHadoopジョブの実行を依頼します。キューには、すべてのスロットを使用可能な場合を100%とした時に、そのキューで最大限使用することができる割合を定義します。
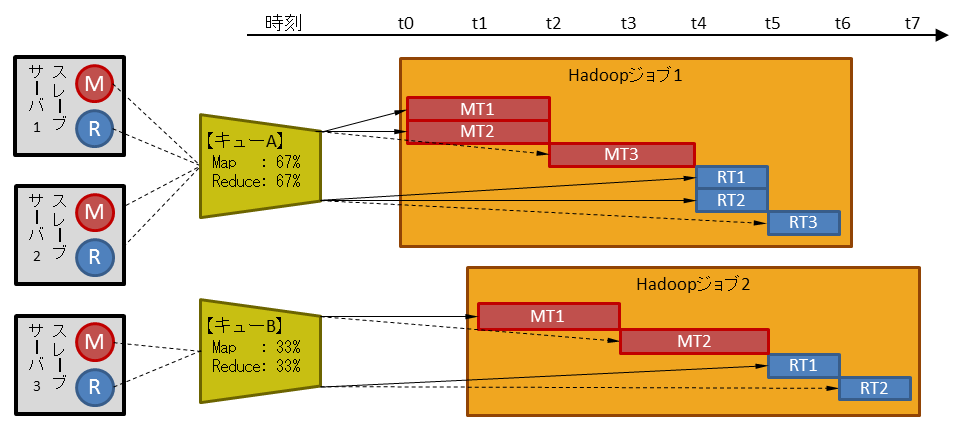
上図は、3台のスレーブサーバにMap/Reduceスロットを計3つずつ定義している場合に、2つのHadoopジョブを時間をおいて実行した例です。
時刻 t0: (Hadoopジョブ1) キューAを指定して実行を依頼
キューAで使用可能な2つのMapスロット(67%)を使用して、Mapタスクが部分的に開始 時刻 t1: (Hadoopジョブ2) キューBを指定して実行を依頼
キューBで使用可能な1つのMapスロット(33%)を使用して、Mapタスクが部分的に開始 時刻 t2: (Hadoopジョブ1) 先行のMapタスクが終了
スロットの解放を待っていた残りのMapタスクが開始 時刻 t3: (Hadoopジョブ2) 先行のMapタスクが終了
スロットの解放を待っていた残りのMapタスクが開始 時刻 t4: (Hadoopジョブ1) 残りのMapタスクが終了
キューAで使用可能な2つのReduceスロット(67%)を使用して、Reduceタスクが部分的に開始 時刻 t5: (Hadoopジョブ1) 先行のReduceタスクが終了
スロットの解放を待っていた残りのReduceタスクが開始 (Hadoopジョブ2) Mapタスクが終了
キューBで使用可能な1つのReduceスロット(33%)を使用して、Reduceタスクが部分的に開始時刻 t6: (Hadoopジョブ1) 残りのReduceタスクが終了し、ジョブ全体が終了
(Hadoopジョブ2) 先行のReduceタスクが終了
スロットの解放を待っていた残りのReduceタスクが開始時刻 t7: (Hadoopジョブ2) 残りのReduceタスクが終了し、ジョブ全体が終了
なお、上図ではキューAとスレーブサーバ1、2のスロットがキューBとスレーブサーバ3のスロットがそれぞれ対応づいているように見えますが、実際にはキューとスレーブサーバやスロットに対応づけはありません。キューに定義された割合をもとに、いずれかのスレーブサーバのいずれかのスロットを使用してHadoopジョブが実行されます。
Capacityスケジューラの設定は、以下のプロパティで指定します。
プロパティ名 | 説明 | デフォルト値 | 設定ファイル |
mapred.queue.names | キュー名を定義します。カンマで区切って複数指定することができます。 | default | mapred-site.xml |
mapred.capacity-scheduler.queue.<キュー名>.capacity | <キュー名>のキューで最大限使用可能なスロットの割合を100以下の整数で指定します。 mapred.queue.namesに指定したキューごとに、総和が100以下になるように指定します。 | 100 | mapred-site.xml |
mapred.job.queue.name | Hadoopジョブ実行時に使用するキュー名を指定します。Hadoopジョブ起動時に指定することで、使用するキューを選択します。 | default | mapred-site.xml |
参考
本製品でのデフォルトの指定値では、1つのキュー(default)に100%のスロットを割り当てているため、動作はFIFOスケジューラと同等になります。
参照
Capacityスケージューラの詳細やHadoopジョブの実行については、以下を参照してください。
http://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
Fairスケジューラ
Hadoopジョブを実行するユーザごとにプールが提供されます。、プールには、全スロットに対してその時点でそのユーザが使用可能なスロット数が割り当てられます。ユーザが1人の場合にはプールに対してすべてのスロットが配分されますが、異なるユーザが同時にHadoopジョブを実行した場合にはプール内のスロット数はすべてのユーザ(プール)で均等になるように配分されます。また、同じユーザが同時に複数のHadoopジョブを実行した場合、プールに配分されたスロット数の範囲内でさらに各Hadoopジョブに均等化されて配分されます。
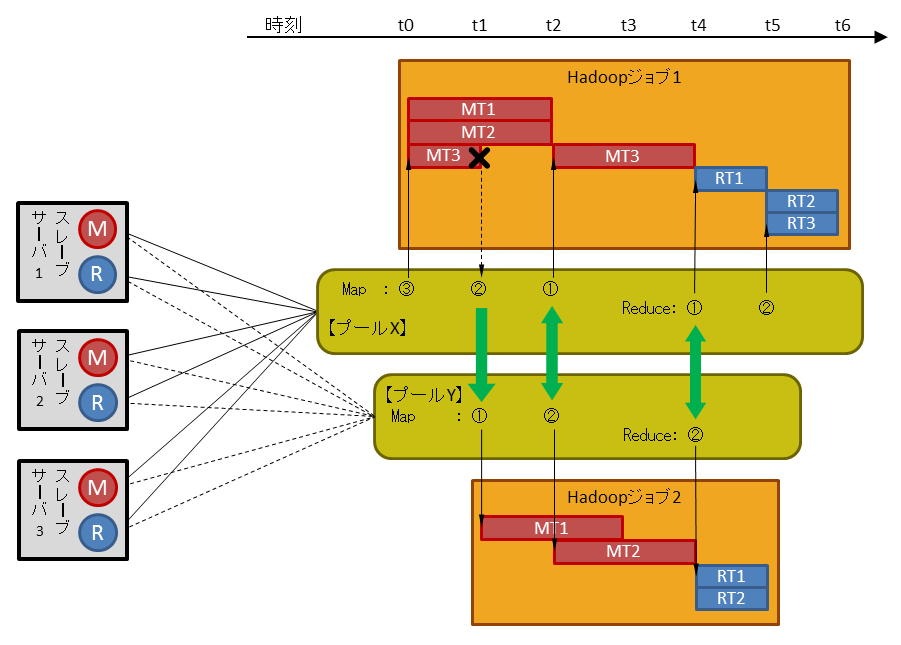
上図は、3台のスレーブサーバにMap/Reduceスロットを計3つずつ定義している場合に、ユーザXとユーザYが時間をおいてHadoopジョブを実行した例です。
時刻 t0: (Hadoopジョブ1) ユーザXが実行を依頼
プールXに配分されたすべてのMapスロットを使用してMapタスクが開始 時刻 t1: (Hadoopジョブ2) ユーザYが実行を依頼
プール間のスロット均等化のために、Hadoopジョブ1のMapタスクを停止することで
確保(Preemtion)したMapスロットがプールYに配分され、Mapタスクが部分的に開始 時刻 t2: (Hadoopジョブ1) Mapタスクが部分的に終了
プールXに配分された1つのMapスロットを使用して、t1で停止された残りのMapタスクが開始 (Hadoopジョブ2) プールXで不要となりプールYに配分されたMapスロットを利用し
残りのMapタスクが開始時刻 t3: (Hadoopジョブ2) 先行のMapタスクが終了
時刻 t4: (Hadoopジョブ2) 残りのMapタスクが終了
プールYに配分された2つのReduceスロットを使用して、Reduceタスクが開始 (Hadoopジョブ1) 残りのMapタスクが終了
プールXに配分された1つのReduceスロットを使用して、Reduceタスクが部分的に開始時刻 t5: (Hadoopジョブ2) Reduceタスクが終了し、ジョブ全体が終了
(Hadoopジョブ1) プールYで不要となりプールXに配分されたReduceスロットを利用し
残りのReduceタスクが開始時刻 t6: (Hadoopジョブ1) 残りのReduceタスクが終了し、ジョブ全体が終了
Fairスケジューラの設定は、以下のプロパティで指定します。
プロパティ名 | 説明 | デフォルト値 | 設定ファイル |
mapred.fairscheduler.preemption | スロットを配分するために他の実行中のタスクを停止するか、タスクの完了を待って配分するかをbool値で指定します。 | false | mapred-site.xml |
参照
Fairスケジューラの詳細やHadoopジョブの実行については以下を参照してください。
http://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html
http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html