Hadoopジョブは、入力データ、出力ディレクトリ、およびデータ処理するためのMapReduceアプリケーションを指定して実行します。ジョブはタスクと呼ばれる内部的な単位に細分化され各スレーブサーバで並列に処理されます。タスク内のデータ処理はタスクの延長で起動されるMapReduceアプリケーションにより行います。
タスクには、MapタスクとReduceタスクの2種類があります。各Mapタスクには入力データを一定のサイズで分割(本製品のデフォルトの設定では256MB)したデータが渡されます。したがって、処理されるMapタスク数は入力データのサイズに依存します。Mapタスクから出力されたデータは指定したReduceタスク数で分割されてReduceタスクに渡されます。
各Mapタスクから出力したデータはMapタスクが動作したスレーブサーバのローカルファイルシステム上のMapReduce作業領域に作業ファイルとして格納された後、各スレーブサーバのReduceタスクに渡されます。そのため、MapReduce作業領域に必要な容量は、MapReduceアプリケーションの論理としてMapタスクからどれだけのデータ量を出力するかに依存します。実行するMapReduceアプリケーションが作業ファイルを格納するのに十分な容量を確保してください。なお、「17.2.3 データの圧縮」で述べたように、Mapタスクの出力を圧縮することで容量の削減が見込めます。
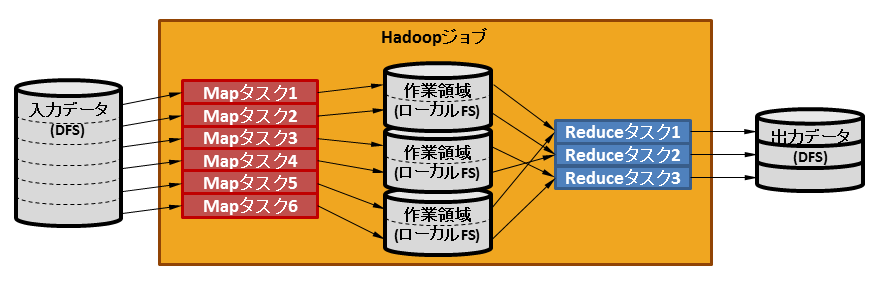
Mapタスクが出力したデータは各データに設定されたKeyの値を元にReduceタスクに渡されます。MapタスクがデータをKeyの順にソートして作業ファイルに出力した後、Reduceタスクは以下の3フェーズで動作します。
shuffleフェーズ
Reduceタスクが、自身が処理対象とするKeyのデータを各TaskTrackerに要求し取得します。
sortフェーズ
shuffleフェーズで取得した、自身が処理対象とするデータ全体をソートします。
reduceフェーズ
ソートされた順に、MapReduceアプリケーションのReducerに渡して処理します。
参考
Mapタスクが出力したデータのうち個々のReduceタスクに処理対象として渡されるデータは、Partitionerと呼ばれる機能により決定されます。デフォルトの設定ではKeyから生成したハッシュ値とReduceタスク数との剰余から対象のReduceタスクを決定するHashPartitionerクラスが使用されます。これは、MapReduceアプリケーションのJobConfに設定することで、自作のPartitionerクラス等に変更することもできます。詳細は「http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html」を参照してください。
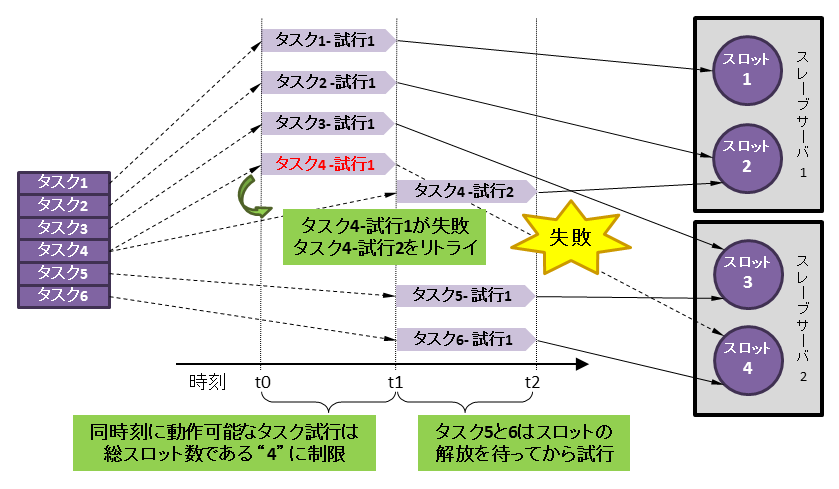
各タスクのMapReduceアプリケーションに記述された処理は内部的にはタスク試行(attempt)に対応づけされ、スレーブサーバ上でorg.apache.hadoop.mapred.Childクラスのjavaプロセスとして実行されます。タスク試行に成功した場合は『成功タスク』となりますが、タスク試行が失敗してもただちに『失敗タスク』にはなりません。タスク試行を他スロットでリトライすることでタスクは継続されます。リトライの結果、最終的にタスク試行が4回(本製品のデフォルトの設定)失敗したタスクは『失敗タスク』となりジョブは異常終了します。すべてのタスクが成功した場合のみジョブは正常終了します。
タスク試行は各タスクごとにスレーブサーバ上で並列に処理されますが、その瞬間最大の並列度は事前に定義したスロット呼ばれる数に制限されます。スロット数はMapスロットとReduceスロットをそれぞれ事前に定義します。たとえば本製品のデフォルトの設定では各スレーブサーバのMap/Reduceの各スロット数は「CPUコア数 - 1」と定義しており、それにスレーブサーバの台数を乗じたものが総スロット数になります。
参考
Hadoopジョブ実行中、同じスレーブサーバ(TaskTracker)でタスク試行が40回以上失敗した場合、そのTaskTrackerへのタスク試行の割り当ては中断されます。ただし、割り当てが中断されるTaskTrackerの最大数はすべてのTaskTrackerの数の1/4の範囲内です。
タスク試行の割り当ては次のHadoopジョブの実行時に再開されます。
ジョブ・タスクに関連する設定は、以下のプロパティで指定します。
プロパティ名 | 説明 | デフォルト値 | 設定ファイル |
mapred.tasktracker.map.tasks.maximum | スレーブサーバ毎のMap、およびReduceスロット数を指定します。 | スレーブサーバのCPUコア数-1 | mapred-site.xml |
mapred.tasktracker.reduce.tasks.maximum | スレーブサーバのCPUコア数-1 | mapred-site.xml | |
mapred.max.tracker.failures | 当該スレーブサーバへのタスク試行の割り当てを中断する契機となる、タスク試行失敗の回数を指定します。 | 40 | mapred-site.xml |
pdfs.fs.local.block.size | 各Mapタスクが入力するデータサイズの上限をバイト数で指定します。 | 268435456 | pdfs-site.xml |
mapred.reduce.tasks | Hadoopジョブで使用するReduceタスク数を指定します。 | mapred.tasktracker.reduce.tasks.maximum×スレーブサーバ台数 | mapred-site.xml |
mapred.map.max.attempts | ひとつのMap、およびReduceタスクにおけるタスク試行回数を指定します。本プロパティに指定された回数、タスク試行に失敗した場合はタスク失敗となります。 | 4 | mapred-site.xml |
mapred.reduce.max.attempts | 4 | mapred-site.xml |