知識データ管理機能では、ベクトルとグラフを利用する意味的関係性に基づいた検索、およびそれらのデータを管理することができます。
Retrieval-Augmented Generation(RAG)アプローチで大規模言語モデル(LLM)を使用する場合、LLMに与える外部の知識データが必要になります。Fujitsu Enterprise Postgresではベクトル形式やグラフ形式の知識データを管理できるため、それぞれの形式に対応する専用データベースを用意する必要がありません。また、Fujitsu Enterprise Postgresのデータベースの多重化や、アクセス制御、データ暗号化などの機能を使用して、知識データを安全に管理できます。
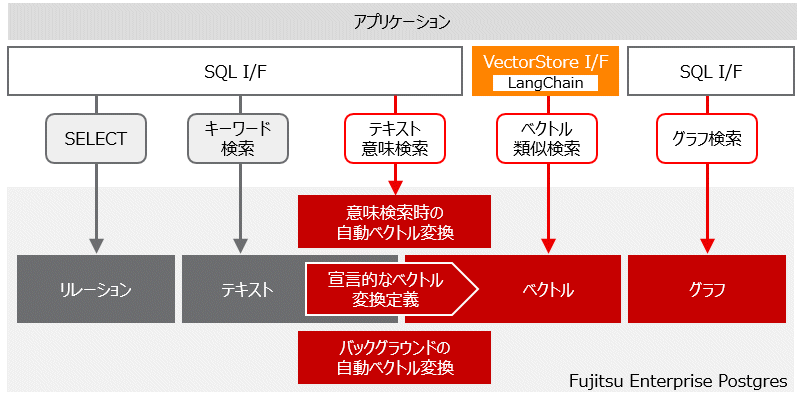
知識データ管理機能では、既存の検索に加え、以下の3つの方法で知識データを検索できます。
ベクトルデータの類似検索
指定されたベクトルデータと、Fujitsu Enterprise Postgresに格納されたベクトルデータ間の類似検索を行います。
![]() 意味的類似性に基づいたテキストデータの検索
意味的類似性に基づいたテキストデータの検索
指定されたテキストと、Fujitsu Enterprise Postgresに格納されたテキスト間の意味的類似性の検索を意味ベクトルへの埋込みを利用して行います。
Fujitsu Enterprise Postgresに意味検索を行いたいテキストデータを格納すると、それらの意味的な類似性を保存するベクトル(意味ベクトル)がデータベース内で自動的に生成、保存されます。検索時は指定されたテキストデータが自動的にベクトルデータに変換され、ベクトルの類似検索によって意味検索を行います。
![]() 関係性に基づいたグラフの検索
関係性に基づいたグラフの検索
グラフはエンティティ間の関係性をノードとノード間をつなぐエッジで表すデータ構造です。グラフに対し、プロパティや関係性に基づく検索を行えます。
また、知識データへのアクセスは、アプリケーションからFujitsu Enterprise PostgresへSQL文を発行することで行えます。また、AIアプリケーション開発フレームワークのLangChainを使用して、Fujitsu Enterprise Postgresの知識データにアクセスすることができます。
知識データ管理機能でできること
知識データ管理機能では、以下が実施できます。
ベクトルデータ管理機能によるベクトルデータの格納と検索
float32、float16、ビットベクトル、およびスパースベクトルの格納
コサイン距離やユークリッド距離によるデータの近傍検索
HNSWとIVFFlatベクトルインデックス
![]() 大規模データセットに適したDiskANNベースのベクトルインデックス
大規模データセットに適したDiskANNベースのベクトルインデックス
![]() テキストの意味検索と自動的なベクトル変換
テキストの意味検索と自動的なベクトル変換
テキスト追加時の自動化されたバックグラウンドベクトル変換
検索対象のベクトル表現と整合性のある意味検索時の自動的なベクトル化
Ollama、OpenAIなどの外部のベクトル埋込モデルの利用
![]() グラフ管理機能によるグラフデータの格納と探索
グラフ管理機能によるグラフデータの格納と探索
グラフの格納
openCypherによるグラフの探索・更新
アプリケーション開発支援
LangChain連携
LangChainを利用するPythonアプリケーションからのアクセスについては、下記サイトで公開されている技術文書を参照してください。
https://www.fujitsu.com/jp/products/software/resources/technical/symfoware/fep/search/