文字コード変換中に、文字化けする場合があります。これは、文字コード変換の環境が正しく設定されていないためです。以下のことを確認してください。
コード変換処理に必要なコード変換製品/環境変数が正しくインストール/設定されているか
コード変換できない文字を使用していないか
![]() 各国語文字列型のホスト変数の文字コードがUTF-32形式の場合、クライアント、サーバでUTF-32形式が扱えるように正しく設定できているか
各国語文字列型のホスト変数の文字コードがUTF-32形式の場合、クライアント、サーバでUTF-32形式が扱えるように正しく設定できているか
コード変換処理に必要なコード変換製品/環境変数が正しくインストール/設定されているか
UNICODE対応しているiconv(Solaris製品でいうと、標準コード変換 1.1以降、SystemWalker/CharsetMGR 5.0以降)では、JISの文字列データを扱う場合の文字コード系のデフォルト値が、シフトJISコード(R90)からMS-SJISに変わっています。従来のシフトJISコード(R90)に戻す場合は、Symfoware/RDBの起動時、SQLアプリケーションの実行時、およびRDA-SV起動時に、以下の環境変数を設定しておく必要があります。
Cシェルの例を以下に示します。
setenv ICONV_CONVERT_TYPE "s-jistype=r90"
コード変換できない文字を使用していないか
日本語コードをUNICODEに変換する際の変換規則が各ベンダによって異なるため、複数ベンダのシステムを連携させてJavaアプリケーションを動作させた場合、いくつかの文字が文字化けします。文字化けが発生する文字を以下に示します。
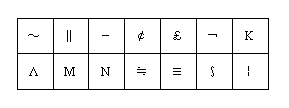
この場合、javaconverterオプションまたはクライアント用の動作環境ファイルのJAVA_CONVERTERパラメタで対象データのエンコーディングを指定する必要があります。
javaconverter=EUC_JP
javaconverter=MS932
JAVA_CONVERTER=(EUC_JP)
JAVA_CONVERTER=(MS932)
![]() 各国語文字列型のホスト変数の文字コードがUTF-32形式の場合、クライアント、サーバでUTF-32形式が扱えるように正しく設定できているか
各国語文字列型のホスト変数の文字コードがUTF-32形式の場合、クライアント、サーバでUTF-32形式が扱えるように正しく設定できているか
各国語文字列型のホスト変数の文字コードがUTF-32形式の場合、以下の設定が正しく行われているか確認してください。
データベースの文字コードはUNICODEのみ対応しています。
参照
データベースの文字コードについては、“解説書”の“文字コード系”を参照してください。
UCS-2形式で格納された補助文字(2文字)を1文字としてSQLの関数で扱うためには、動作環境ファイルのパラメタ“SURROGATE_PAIR_NUMBER”を“1”にする必要があります。
参照
動作環境ファイルについては、“アプリケーション開発ガイド(共通編)”の“動作環境ファイルのパラメタ一覧”を参照してください。