機能
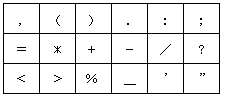
SQL文で使用可能な文字を規定します。
記述形式
一般規則
各国語文字は、日本語の文字を表します。
各国語文字のコードは、EUCコードでのJIS漢字/非漢字の範囲(コードセット1である2バイト)およびJEF拡張漢字/非漢字の範囲(コードセット3である3バイト)です。
各国語文字に、半角カタカナは含みません。
各国語文字は、日本語の文字を表します。
各国語文字のコードは、シフトJISコードでのJIS漢字/非漢字を含む範囲(2バイト)です。
各国語文字に、半角カタカナは含みません。
各国語文字は、日本語の文字を表します。
各国語文字のコードは、UNICODEでのJIS漢字/非漢字を含む範囲です。
UTF-8形式では2バイト、3バイトまたは4バイト、UCS-2形式では2バイトまたは4バイトです。UCS-2形式では、UNICODEの補助文字(1~16面の4バイト文字)はUCS-2の2文字として扱われます。
補助文字のコード変換はUnicode 4.1で変換します。Unicode 4.1の補助文字のコード変換は、文字列型ではUTF-8の4バイト、各国語文字列型ではUCS-2の2文字として扱われます。ただし、以下のいずれかに該当する場合、Unicode 2.0でコード変換を行います。
1)Symfoware Server 9.1.0以前のバージョンレベル
2)Unicode 4.1に対応していない以下の製品をインストールしている場合
<Windows版>
・SystemWalker/CharsetMGR-M V5.1L10以降
・Interstage Charset Manager V8.2以前
<Linux版>
・Interstage Charset Manager V8.2以前
<Solaris 32ビット版>
・Interstage Charset Manager V8
Unicode 2.0とUnicode 4.1の補助文字のコード変換はサロゲートペア領域の扱いが異なります。Unicode 4.1はUNICODEの補助文字を、UTF-8に変換すると、4バイト文字に変換します。Unicode 2.0はUTF8として3バイトまでしか扱えません。そのため、UNICODEの補助文字をUTF-8に変換すると、3バイト文字のペア(3バイト×2)に変換されます。
サーバとクライアントで、Unicode 4.1とUnicode 2.0のコード変換環境が混在する場合、クライアント用の動作環境ファイルのCHARACTER_TRANSLATEの指定により、Unicode 2.0でコード変換を行う場合があります。UNICODEの補助文字をUnicode 4.1で扱いたい場合、クライアント用の動作環境ファイルのCHARACTER_TRANSLATEにUnicode 4.1のコード変換環境を指定してください。
使用例
英大文字
UPDATE
英大文字と特殊文字
COUNT(*)