RMS is an application availability manager that ensures the availability of both hardware and software resources in a cluster with configuration of 2 or more nodes. This is accomplished through redundancy and through the ability to fail over monitored resources to surviving nodes.
For example, monitored resources can be almost any system component, such as the following:
File system
Volume (disk)
Application
Network interface
Entire node
For redundancy, RMS uses multiple nodes in the cluster. Each node is configured to assume the resource load from any other node. In addition, RAID hardware and/or RAID software replicate data stored on secondary storage devices.
For application availability, RMS monitors resources with detector programs. When a resource fails, RMS triggers a user-defined response. Normally, the response is to make the resource available on other nodes.
Resources that are mutually dependent can be combined into logical groups such that the failure of any single resource in the group triggers a response for the entire group. During switchover, RMS ensures that all of a group's resources on the original node (before the failure) are brought offline prior to any resources being brought online on the new node. This prevents any possibility of data corruption by two or more nodes attempting to access a resource simultaneously.
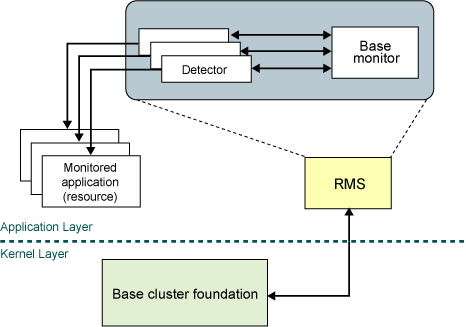
The figure below shows how RMS uses detectors to monitor resources. A detector reports any changes in the state of a resource to the RMS base monitor, which then determines if any action is required.
Figure 2.8 RMS resource monitoring