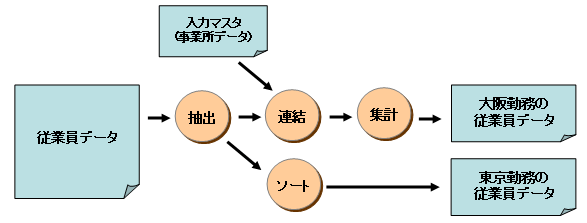
まず、従業員データから勤務地が大阪の従業員データと東京の従業員データを抽出します。
次に、大阪の従業員データは、入力マスタファイルと連結して、最後に集計します。
同時に、東京の従業員データは、従業員番号順にソートします。
入力データから目的のデータを取得するために必要な処理とファイルについて、説明します。
図7.5 統合コマンドの処理概要(処理を順番に実行)
順番 | 使用する DataEffectorの機能 | 処理内容 | 入力ファイル (形式、文字コード) | 入力マスタファイル (形式、文字コード) |
|---|---|---|---|---|
1 | 抽出機能 | 従業員データより、勤務地が大阪の従業員情報を抽出します。 | 従業員データ (XML、SHIFT-JIS) | - |
2-1 | 連結機能 | 入力マスタファイルと連結して事業所情報を付け加えます。 | 1の結果 (XML、SHIFT-JIS) | 事務所データ (XML、SHIFT-JIS) |
2-2 | 集計機能 | 勤務地ごとに集計します。 | 2-1の結果 (CSV、SHIFT-JIS) | - |
3 | ソート機能 | 従業員番号順にソートします。 | 1の結果 (XML、SHIFT-JIS) | - |
従業員データ![]()
<EMPLOYEE><ENO>070</ENO><NAME>田中</NAME><DEPARTMENT>総務</DEPARTMENT><POSITION>課員</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>031</ENO><NAME>鈴木</NAME><DEPARTMENT>総務</DEPARTMENT><POSITION>課員</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>003</ENO><NAME>高橋</NAME><DEPARTMENT>総務</DEPARTMENT><POSITION>課長</POSITION><AREA>東京</AREA><BLDG>松ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>009</ENO><NAME>渡辺</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課長</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>120</ENO><NAME>伊藤</NAME><DEPARTMENT>総務</DEPARTMENT><POSITION>課長</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>055</ENO><NAME>山本</NAME><DEPARTMENT>総務</DEPARTMENT><POSITION>課員</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>135</ENO><NAME>中村</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課長</POSITION><AREA>東京</AREA><BLDG>松ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>095</ENO><NAME>小林</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課員</POSITION><AREA>東京</AREA><BLDG>松ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>094</ENO><NAME>斎藤</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課員</POSITION><AREA>東京</AREA><BLDG>松ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>085</ENO><NAME>加藤</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課員</POSITION><AREA>大阪</AREA><BLDG>竹ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>033</ENO><NAME>佐藤</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課員</POSITION><AREA>福岡</AREA><BLDG>梅ビル</BLDG></EMPLOYEE> <EMPLOYEE><ENO>032</ENO><NAME>吉田</NAME><DEPARTMENT>営業</DEPARTMENT><POSITION>課員</POSITION><AREA>福岡</AREA><BLDG>梅ビル</BLDG></EMPLOYEE> |
事務所データ![]()
<INFO><LOCALE>東京</LOCALE><BLDG></BLDG><NEWBLDG></NEWBLDG><PHONE>7100</PHONE><CODE>00001</CODE><ADDRESS>東京都港区高輪</ADDRESS></INFO> <INFO><LOCALE>大阪</LOCALE><BLDG>竹ビル</BLDG><NEWBLDG>亀ビル</NEWBLDG><PHONE>7200</PHONE><CODE>00002</CODE><ADDRESS>大阪府大阪市北区梅田</ADDRESS></INFO> <INFO><LOCALE>福岡</LOCALE><BLDG>梅ビル</BLDG><NEWBLDG></NEWBLDG><PHONE>7300</PHONE><CODE>00008</CODE><ADDRESS>福岡県福岡市博多区博多駅</ADDRESS></INFO> |
設計した内容を、統合定義ファイルに定義していきます。
データの文字コード、ログファイル名を定義します。
使用する機能の定義を、処理条件定義部に定義します。ここでは4つの機能を使っているので、それぞれを定義します。
実行順序を、シナリオ定義部に定義します。
まずは、Select1を定義します。
次にReplace1とAnalyze1は、順番に実行するので、Type属性は“serial”です。
Sort1は、Replace1およびAnalyze1と並行に処理するので、Type属性は“parallel”です。
統合定義ファイルの例
統合定義ファイルの指定例を以下に示します。
deconfig1.xml
<?xml version="1.0" encoding="utf-8"?>
<DataEffector>
<!-- 共通定義部 -->
<CommonCfg>
<Data CharacterCode ="SHIFT-JIS" />
<LogFile>/home/shun/Sample1/log/all.log</LogFile>
</CommonCfg>
<!-- 処理条件定義部:Select -->
<Select Name="Select1">
<BaseDirectory>/home/shun/Sample1</BaseDirectory>
<DataFile InFileType="XML">
<File>data/Employee.xml</File>
</DataFile>
<SkipChar>\s,\n,\t,\S</SkipChar>
<SeparateChar>\s,\n,\t</SeparateChar>
<ANKmix Flag="false" />
<KNJmix Flag="false" />
<OutCondition SearchNumber="1">
<Query>/EMPLOYEE/AREA = '大阪'</Query>
<OutFile>data/select_kekka_osaka.xml</OutFile>
</OutCondition>
<OutCondition SearchNumber="2">
<Query>/EMPLOYEE/AREA = '東京'</Query>
<OutFile>data/select_kekka_tokyo.xml</OutFile>
</OutCondition>
</Select>
<!-- 処理条件定義部:Replace -->
<Replace Name="Replace1">
<BaseDirectory>/home/shun/Sample1</BaseDirectory>
<WorkFolder>tmp</WorkFolder>
<Memory MemorySize="1500" />
<InFile InFileType="XML">
<JnlFile ID="Journal">
<File>data/select_kekka_osaka.xml</File>
<ListDef>
<Item ID="JENO">/EMPLOYEE/ENO/text()</Item>
<Item ID="JNAME">/EMPLOYEE/NAME/text()</Item>
<Item ID="JDEPARTMENT">/EMPLOYEE/DEPARTMENT/text()</Item>
<Item ID="JPOSITION">/EMPLOYEE/POSITION/text()</Item>
<Item ID="JAREA">/EMPLOYEE/AREA/text()</Item>
<Item ID="JBLDG">/EMPLOYEE/BLDG/text()</Item>
</ListDef>
</JnlFile>
<MstFile ID="Master">
<File>data/Company.xml</File>
<ListDef>
<Item ID="MLOCALE">/INFO/LOCALE/text()</Item>
<Item ID="MBLDG">/INFO/BLDG/text()</Item>
<Item ID="MNEWBLDG">/INFO/NEWBLDG/text()</Item>
<Item ID="MPHONE">/INFO/PHONE/text()</Item>
</ListDef>
</MstFile></InFile>
<OutCondition>
<OutFile>data/replace_kekka.csv</OutFile>
<Jcondition>
<Item Compare="complete" JoinType="inner">
<Left InFileID="Journal">$JAREA</Left>
<Right InFileID="Master">$MLOCALE</Right>
</Item>
</Jcondition>
<OutputDef>
<Item>$JAREA</Item>
<Item>$JENO</Item>
<Item>$JNAME</Item>
<Item>$JDEPARTMENT</Item>
<Item>$MNEWBLDG</Item>
<Item>$MPHONE</Item>
</OutputDef>
<ExceptRecordFolder>exp</ExceptRecordFolder>
</OutCondition>
</Replace>
<!-- 処理条件定義部:Analyze -->
<Analyze Name="Analyze1">
<BaseDirectory>/home/shun/Sample1</BaseDirectory>
<WorkFolder>tmp</WorkFolder>
<Memory MemorySize="1500" />
<InFile>
<File>data/replace_kekka.csv</File>
</InFile>
<OutCondition>
<GCondition Total="true">
<Item Subtotal="true">$JDEPARTMENT</Item>
<Item Subtotal="true">$JENO</Item>
</GCondition>
<RCondition>
<Item Label="JNAME">$JNAME</Item>
<Item Label="JPOSITION">$JPOSITION</Item>
<Item Label="JAREA">$JAREA</Item>
<Item Label="MNEWBLDG">$MNEWBLDG</Item>
<Item Label="MPHONE">$MPHONE</Item>
<Item Label="COUNT">count()</Item>
</RCondition>
<OutFile>result/kekka01.csv</OutFile>
</OutCondition>
</Analyze>
<!-- 処理条件定義部:Sort -->
<Sort Name="Sort1">
<BaseDirectory>/home/shun/Sample1</BaseDirectory>
<WorkFolder>tmp</WorkFolder>
<Memory MemorySize="1500" />
<InFile InFileType="XML">
<File>data/select_kekka_tokyo.xml</File>
</InFile>
<OutCondition>
<OutFile>result/kekka02.csv</OutFile>
<OCondition>
<Item>/EMPLOYEE/ENO/text()</Item>
</OCondition>
<RCondition>
<Item Label="ENO">/EMPLOYEE/ENO/text()</Item>
<Item Label="NAME">/EMPLOYEE/NAME/text()</Item>
<Item Label="DEPARTMENT">/EMPLOYEE/DEPARTMENT/text()</Item>
<Item Label="POSITION">/EMPLOYEE/POSITION/text()</Item>
<Item Label="AREA">/EMPLOYEE/AREA/text()</Item>
<Item Label="BLDOG">/EMPLOYEE/BLDG/text()</Item>
</RCondition>
</OutCondition>
</Sort>
<!-- シナリオ定義部 -->
<Scenario Name="Scenario1">
<Step>Select1</Step>
<StepGroup Type="parallel">
<StepGroup Type="serial">
<Step>Replace1</Step>
<Step>Analyze1</Step>
</StepGroup>
<Step>Sort1</Step>
</StepGroup>
</Scenario>
</DataEffector> |
統合コマンドにシナリオ名:Scenario1を指定して実行します。
# deex -p Scenario1 -f /home/shun/cfg/deconfig1.xml |
実行結果イメージ![]()
kekka01.csv
"JDEPARTMENT","JENO","JNAME","JPOSITION","JAREA","MNEWBLDG","MPHONE","COUNT" "営業","009","渡辺","課長","大阪","亀ビル","7200",1 "営業","085","加藤","課員","大阪","亀ビル","7200",1 "営業","-","渡辺","課長","大阪","亀ビル","7200",2 "総務","031","鈴木","課員","大阪","亀ビル","7200",1 "総務","055","山本","課員","大阪","亀ビル","7200",1 "総務","070","田中","課員","大阪","亀ビル","7200",1 "総務","120","伊藤","課長","大阪","亀ビル","7200",1 "総務","-","鈴木","課員","大阪","亀ビル","7200",4 "-","-","渡辺","課長","大阪","亀ビル","7200",6 |
kekka02.csv
"ENO","NAME","DEPARTMENT","POSITION","AREA","BLDG" "003","高橋","総務","課長","東京","松ビル" "094","斎藤","営業","課員","東京","松ビル" "095","小林","営業","課員","東京","松ビル" "135","中村","営業","課長","東京","松ビル" |