ハードウェアを追加する場合の作業手順について説明します。
共用ディスク装置の追加手順について説明します。
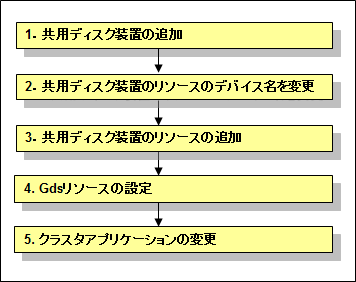
図8.1 共用ディスク装置の追加手順
参考
「5. クラスタアプリケーションの変更」には、RMSの停止が必要です。
ただし、以下のすべての条件を満たす場合は、「5. クラスタアプリケーションの変更」が不要になるため、RMSを停止する必要はありません。
追加した共用ディスク装置をGDSの既存のクラスに登録する。
追加した共用ディスク装置をFsystemリソースとして使用しない。
◆操作手順
共用ディスク装置の追加
“12.2 保守作業の流れ”に従い、当社技術員(CE)に共用ディスク装置の追加を依頼してください。
共用ディスク装置のリソースのデバイス名を変更
既存の共用ディスク装置のリソースに設定されているデバイス名を、現在のデバイス名に更新します。
以下のコマンドを実行してください。filepathには空のファイルを絶対パスで指定します。
# /etc/opt/FJSVcluster/bin/clautoconfig -f filepath
注意
GDSの設定ファイル/etc/opt/FJSVsdx/sdx.cfにSDX_UDEV_USE=offが記述されている場合、clautoconfigコマンドは実行しないでください。
共用ディスク装置のリソースの追加
追加した共用ディスク装置に対応するリソースを、リソースデータベースに登録します。
参照
リソースの登録については、“5.1.3.2 ハードウェア装置の登録”を参照してください。
Gdsリソースの設定
GDSを使用する場合は、GDSの設定を行い、Gdsリソースを作成します。
追加した共用ディスク装置をGDSの既存のクラスに登録する場合、Gdsリソースの設定は不要です。
参照
GDSの設定およびGdsリソースの作成については、“6.3 GDSの構成設定”、“6.7.3.3 Gdsリソースの事前設定”、“6.7.3.4 Gdsリソースの設定”を参照してください。
クラスタアプリケーションの変更
追加した共用ディスク装置に関連する以下のリソースを、クラスタアプリケーションに追加するため、クラスタアプリケーションを変更します。
Fsystemリソース
Gdsリソース
参照
クラスタアプリケーションの変更については、“10.3 クラスタアプリケーションの変更”を参照してください。
業務LAN/管理LANで使用するネットワークインタフェースカードの追加手順について説明します。
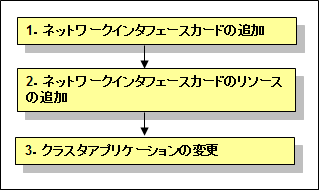
図8.2 ネットワークインタフェースカードの追加手順
◆操作手順
ネットワークインタフェースカードの追加
“12.2 保守作業の流れ”に従い、当社技術員(CE)にネットワークインタフェースカードの追加を依頼してください。
ネットワークインタフェースカードのリソースの追加
追加したネットワークインタフェースカードに対応するリソースを、リソースデータベースに登録します。
参照
リソースの登録については、“5.1.3.2 ハードウェア装置の登録”を参照してください。
クラスタアプリケーションの変更
追加したネットワークインタフェースカードに関連する以下のリソースを、クラスタアプリケーションに追加するため、クラスタアプリケーションを変更します。
引継ぎネットワークリソース
Glsリソース
参照
クラスタアプリケーションの変更については、“10.3 クラスタアプリケーションの変更”を参照してください。
PRIMECLUSTERシステム運用時に、Dynamic Reconfiguration (以降、DR)機能を使用してシステムボートを増設する場合の手順について説明します。
システムボードの活性増設を実施すると、PRIMECLUSTERの監視制御に影響を及ぼし、ノードが強制停止されることがあるため、以下の手順によりクラスタの監視機能を一時停止させてから行ってください。
PRIMECLUSTERのRMSを停止します。各ノードにおいてそれぞれ以下のようにhvshutコマンドを実行し、問合せに対して"yes"と答えてください。この操作によりPRIMECLUSTERのRMSは停止しますが、クラスタアプリケーションは稼働したままです。
# hvshut -L
WARNING
-------
The '-L' option of the hvshut command will shut down the RMS
software without bringing down any of the applications.
In this situation, it would be possible to bring up the same
application on another node in the cluster which *may* cause
data corruption.
Do you wish to proceed ? (yes = shut down RMS / no = leave RMS running).
yes
NOTICE: User has been warned of 'hvshut -L' and has elected to proceed.
さらに、各ノードにおいて/opt/SMAW/SMAWRrms/bin/hvenv.local ファイルの末尾に以下の1行を追加します。
export HV_RCSTART=0
上記手順は、RMSがOS起動直後に自動起動しないようにするために必要です。
PRIMECLUSTERのシャットダウン機構を停止します。各ノードにおいてそれぞれ以下のようにsdtoolコマンドを実行してください。
# sdtool -e
LOG3.013806902801080028 11 6 30 4.5A00 SMAWsf : RCSD returned a successful exit code for this command PRIMECLUSTERのCFにおけるタイムアウト値を変更します。各ノードにおいてそれぞれ以下の操作を実行してください。
/etc/default/cluster.configに以下の設定を追加してください。
CLUSTER_TIMEOUT "600"
以下のコマンドを実行してください。
# cfset -r正しくタイムアウト値が変更されたか確認してください。
# cfset -g CLUSTER_TIMEOUT
>From cfset configuration in CF module:
Value for key: CLUSTER_TIMEOUT --->600
#DRの操作を実施してください。
参照
DRの操作手順はハードウェアの関連マニュアルを参照してください。
PRIMECLUSTERのCFにおけるタイムアウト値を元に戻します。各ノードにおいてそれぞれ以下の操作を実行してください。
先に/etc/default/cluster.configに定義したCLUSTER_TIMEOUTの値を10に設定します。
変更前:
CLUSTER_TIMEOUT "600"
変更後:
CLUSTER_TIMEOUT "10"
以下のコマンドを実行してください。
# cfset -r正しくタイムアウト値が変更されたか確認してください。
# cfset -g CLUSTER_TIMEOUT
>From cfset configuration in CF module:
Value for key: CLUSTER_TIMEOUT --->10
#PRIMECLUSTERのシャットダウン機構を起動します。各ノードにおいてそれぞれ以下のようにsdtoolコマンドを実行してください。
# sdtool -bPRIMECLUSTERのシャットダウン機構が起動していることを確認します。(以下、2ノード構成の場合の出力例)
# sdtool -s
Cluster Host Agent SA State Shut State Test State Init State ------------ ----- -------- ---------- ---------- ---------- node0 SA_mmbp.so Idle Unknown TestWorked InitWorked node0 SA_mmbr.so Idle Unknown TestWorked InitWorked node1 SA_mmbp.so Idle Unknown TestWorked InitWorked node1 SA_mmbr.so Idle Unknown TestWorked InitWorked
PRIMECLUSTERのRMSを起動します。各ノードにおいてそれぞれ以下のようにhvcmコマンドを実行してください。
# hvcm
Starting Reliant Monitor Services nowPRIMECLUSTERのRMSが起動していることを確認します。Cluster AdminのRMSメインウィンドウにおいて、各ノードの状態表示アイコンが緑色(Online)になっていることを確認してください。
最後に、各ノードにおいて/opt/SMAW/SMAWRrms/bin/hvenv.localファイルから以下の行を削除します。
export HV_RCSTART=0
注意
DRを使用する予定がある場合は、クラスタシステムの構築段階で必ず上記のテストを実施し、問題がないことを確認してください。
上記の手順1の完了後から手順7の完了後までの間に、ハードウェア異常等の原因でDR実行中のノードの異常終了(パニックやリセット等)やハングアップが発生した場合、以下の手順に従い、DR実行中のノードで稼働していたクラスタアプリケーションを待機ノードで起動する必要があります。
ハングアップが発生している場合は当該ノードを強制的に停止させ、ノードが稼働していないことを確認してください。
異常が発生していないいずれかのノードにおいて、cftoolコマンドを実行し、異常が発生したノードのノード番号とCFノード名を入力することでDOWNマークを付けてください。ただし、“cftool -n”コマンドの結果で、異常が発生したノードの状態がLEFTCLUSTERとなっていない場合、LEFTCLUSTERになるのを待ってから“cftool -k”コマンドを実行してください。
# cftool -n Node Number State Os Cpu node0 1 UP Linux EM64T node1 2 LEFTCLUSTER Linux EM64T # cftool -k This option will declare a node down. Declaring an operational node down can result in catastrophic consequences, including loss of data in the worst case. If you do not wish to declare a node down, quit this program now. Enter node number: 2 Enter name for node #2: node1 cftool(down): declaring node #2 (node1) down cftool(down): node node1 is down # cftool -n Node Number State Os Cpu node0 1 UP Linux EM64T node1 2 DOWN Linux EM64T #
異常が発生していない全てのノードで手順5~手順9を実行し、RMSを起動してください。運用・待機構成のクラスタアプリケーションの場合、"hvswitch -f "コマンドを実行してクラスタアプリケーションを強制起動してください。詳細は“PRIMECLUSTER 活用ガイド<コマンドリファレンス編>”hvswitchの-fオプションの説明を参照してください。
# hvswitch -f userApplication The use of the -f (force) flag could cause your data to be corrupted and could cause your node to be killed. Do not continue if the result of this forced command is not clear. The use of force flag of hvswitch overrides the RMS internal security mechanism. In particular RMS does no longer prevent resources, which have been marked as "ClusterExclusive", from coming Online on more than one host in the cluster. It is recommended to double check the state of all affected resources before continuing. IMPORTANT: This command may kill nodes on which RMS is not running in order to reduce the risk of data corruption! Ensure that RMS is running on all other nodes. Or shut down OS of the node on which RMS is not running. Do you wish to proceed ? (default: no) [yes, no]:yes #
異常が発生していたノードの復旧後、当該ノードで手順5~手順9を実行し、RMSを起動してください。