Linuxで、以下の環境の場合のクラスタシステムの可用性について説明します。
物理環境のクラスタシステム
管理OS異常切替機能を使用したクラスタシステム(KVM)
異なる管理OS上のゲストOS間クラスタ(KVM)
同一管理OS上のゲストOS間クラスタ(KVM)
異なるコンピュートノード上のゲストOS間クラスタ(RHOSP)
同一コンピュートノード上のゲストOS間クラスタ(RHOSP)
ゲストOS間クラスタ(K5)
異なるESXiホスト上のゲストOS間クラスタ(VMware)
同一ESXiホスト上のゲストOS間クラスタ(VMware)
以下の表では、各監視対象の異常検出の可否についてまとめています。
監視対象 | 物理サーバ | KVM | RHOSP | K5 | VMware | ||||
|---|---|---|---|---|---|---|---|---|---|
管理OS異常切替機能を使用した | 異なる管理OS上のゲストOS間 | 同一管理OS上のゲストOS間 | 異なるコンピュートノード上のゲストOS間クラスタ | 同一コンピュートノード上のゲストOS間クラスタ | ゲストOS間クラスタ | 異なるESXiホスト上のゲストOS間 | 同一ESXiホスト上のゲストOS間 | ||
1. 筐体 | ○ | ○ | × | × | ○*1 | × | × | ○*2 | × |
2. 共用ディスクおよびディスクアクセスパス | ○ | ○ | ○ | × | ○ | × | ○ | ○ | × |
3. 業務LAN | ○ | ○ | ○ | × | ○ | × | ○ | ○ | × |
4. OS(物理、管理OS/ESXiホスト) | ○ | ○ | × | × | ○*1 | × | × | ○*2 | × |
5. OS(ゲストOS) | - | ○ | ○ | ○ | ○ | ○ | ○ | ○*3 | ○*4 |
6. 業務(クラスタアプリケーション) | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
異常時の業務継続 ○:可、×:不可、-:対象外
*1 コンピュートインスタンスの高可用設定により業務継続可能
コンピュートインスタンスの高可用設定の詳細については、“Red Hat OpenStack Platform コンピュートインスタンスの高可用性”を参照してください
*2 I/Oフェンシング機能使用時、または、VMware vCenter Server連携機能とVMware vSphere HA使用時
ゲストOSのハングアップを検出しゲストOSを待機系に自動切替えできない場合は、LEFTCLUSTERとなります
*3 ゲストOSを待機系に自動切替えできない場合は、LEFTCLUSTERとなります
*4 VMware vCenter Server連携機能使用時のみ自動切替え可能となります
図1.13 物理環境
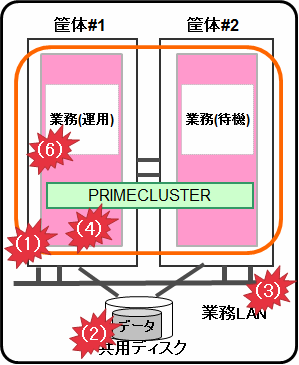
図1.14 仮想環境
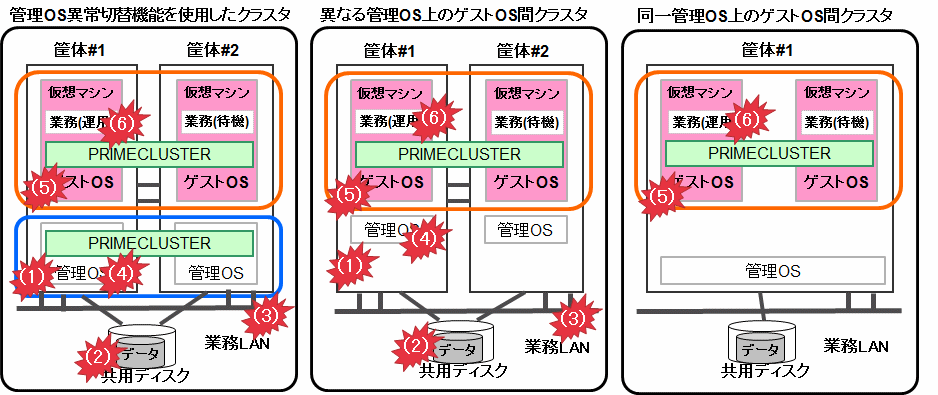
RHOSP環境の場合、管理OSをコンピュートノードと、VMware環境の場合、管理OSをESXiホストと読み替えてください。K5環境の場合、異なる管理OS上のゲストOS間クラスタの場合の図と同様です。
監視対象の異常検出方法
筐体
PRIMEQUEST 2000の場合はサーバ管理ボード(MMB)、PRIMEQUEST 3000の場合はiRMC/MMBと連携した非同期監視機能が、CPUやメモリ等の異常を契機とするパニック、およびリセットを即時検出し、待機系に切り替えます。PRIMERGYおよび仮想環境の場合、ハートビート監視で異常を検出し、待機系に切り替えます。*1
共用ディスクおよびディスクアクセスパス
ボリューム管理機能(GDS)と組み合わせることで、ディスクアクセスおよび、ディスクアクセスパスの故障を検出(Gdsリソースで監視)し、ディスクアクセス不可または、ディスクアクセスパスの全系故障の場合に待機系に切り替えます。
業務LAN
ネットワーク多重化機能(Global Link Services。以降、GLS)と組み合わせることで、業務LANのネットワークアダプタや経路の故障を検出(Glsリソースで監視)し、ネットワークの全系故障の場合に待機系に切り替えます。
OS(物理、管理OS/ESXiホスト)
ハートビート監視で異常を検出し、待機系に切り替えます。*1
OS(ゲストOS)
ハートビート監視で異常を検出し、待機系に切り替えます。
業務(クラスタアプリケーション)
クラスタアプリケーションのリソース異常発生時に待機系に切り替えます。
*1 異なる管理OS上のゲスト間クラスタ(RHOSP、VMware)の場合、LEFTCLUSTERとなります。コンピュートインスタンスの高可用設定(RHOSP)やvSphere HA機能(VMware)により、ゲストOSが再起動することで、LEFTCLUSTER状態が自動的に解消され、待機系に切り替わります。