CFは、他の全てのPRIMECLUSTERモジュール/コンポーネントが使用するOSD層などの基盤機能を提供します。
CFには以下の特徴があります。
システム起動時に自動的にロードされる、ロード可能な擬似デバイスドライバの装備
OSDおよび汎用モジュールを含むCFドライバ
次にCFの機能について説明します。
CFのOSD層モジュールは、OSと全てのPRIMECLUSTERモジュールが依存する抽象化されたOS非依存部との間を橋渡しするインタフェースを提供します。このため、PRIMECLUSTERがサポートするOSとアーキテクチャにおけるソースファイルは同一となります。この設計理念は、以下の2つのメリットのために採用しています。
ソース保守管理情報の一本化による万全なユーザ支援体制
新しいOS やアーキテクチャへの移植が容易なため市場ニーズへ迅速に対応できる
ICF (ノード間通信機構) モジュールは、PRIMECLUSTERにおける全てのノード間通信のネットワーク通信層です。ICFモジュールには以下の機能があります。
到着順を保証したクラスタノード間のデータグラム通信サービス
送信順序の保証 (宛先ノードの異常がない場合)
OSDを経由したネットワークへのインタフェース
ハードウェアの一点故障 (Single Point of Failure) を回避するため、ICFは冗長化されたクラスタインタコネクトでも使用できます。複数のクラスタインタコネクトが使用可能な場合、ICFは使用可能な全てのインタコネクトにメッセージを分散させることにより、パフォーマンスを向上させます。ひとたび障害が発生すると、クラスタインタコネクト間の自動切替えが行われます。また、ICFには、クラスタインタコネクトの間欠障害に対する経路リカバリ機構も保持しています。
ICFは、CFの内部コンポーネントのみで使用可能であり、上位層の各種プログラム (一般的なユーザプログラム) では使用することはできません。そのかわり、クラスタインタコネクトにアクセスするアプリケーションにはCluster Interconnect Protocol (CIP) が使用可能です。CIPはICF上でTCP/IPプロトコルを提供します。
JOINモジュールは、ノードを動的にクラスタに参入させる機構です。参入すべきクラスタが存在しない初期状態の場合は、CFが1ノードのクラスタシステム (初期クラスタ) を作成します。このとき、複数ノードが同時に初期クラスタを作成するようなケースが考えられますが、分散ノード環境におけるリーダ選択アルゴリズムにより、マスタノードが決定され、初期クラスタが作成されます。
初期クラスタが作成されると、JOINモジュールは他のノードをクラスタに参入させることができます。JOINモジュールは、初期クラスタ作成段階にプロトコルバージョン情報を提供し、ローリングアップグレードをサポートする機構が組み込まれています。各ノード間で使用しているプロトコルのバージョンが異なる場合、クラスタの全ノードがサポートしているバージョンを自動的に指定します。
Web-Based Admin Viewは、PRIMECLUSTER製品が使用するGUI基盤です。Web-Based Admin Viewの機能を以下に示します。
複数のGUIの共通基盤
PRIMECLUSTER には、CF、RMS、SF を制御する Cluster Admin GUI の他に、GDS や GFS などの他のサービスをサポートする GUI が用意されている。Web-Based Admin View には、これらの全ての GUI が共通基盤として動作する。
シングルログイン
1回のログインで複数ノード、複数のGUI製品を使用することが可能
パスワードの暗号化
クライアントブラウザと管理サーバの間で送信されるパスワードは暗号化される
ロギング
構成設定または管理に関する全てのGUI操作のロギング
3層構造
管理サーバをクラスタシステムと分離した外部に設定
参照
Web-Based Admin Viewの機能の詳細については、“PRIMECLUSTER Web-Based Admin View操作手引書” を参照してください。
PRIMECLUSTERシャットダウン機構 (PRIMECLUSTER SF) は、クラスタシステム内でユーザ資産に対する競合が発生するような異常処理時に、他のノードを停止させることを保証する機能を提供します。PRIMECLUSTER SF は主に以下のコンポーネントで構成されます。
PRIMECLUSTER SFには以下の長所があります。
異常が発生したクラスタノードを強制停止させる。
任意のPRIMECLUSTERモジュールからクラスタノードを強制停止させる。
冗長シャットダウン方式が利用できる。
クラスタノードを強制停止させる経路を定期的 (10分間隔) に確認する。
非同期監視は、ハードウェア特性を活かしてノードの状態を監視し、ノードダウンを即時に検出します。PRIMECLUSTERシステムは、クラスタインタコネクトを利用した、ハートビートの送信と応答によるノードの状態監視を定周期間隔で行っていますが、非同期監視を利用することにより、より即時的なノードのダウン検出を実現します。
非同期監視は以下の機能を提供します。
ノードの状態監視
非同期監視は、ハードウェアが提供する機能を利用したノードの状態監視を行います。突然のシステムパニックや電源切断など、万が一他のノードに異常が発生した場合、SFにその異常を通知します。また、システム負荷 (System Load) が著しく高いことが原因で、クラスタノード間でのハートビート要求の送信と応答が一時的に途切れた場合でも、非同期監視がオプションハードウェアを経由してノードの状態を正確に判断します。
ノードの強制停止
SA (シャットダウンエージェント) としての機能を提供し、異常が発生したノードの強制停止を保証します。
オプションハードウェアの接続確認(シャットダウンエージェントのテスト)
SA ( シャットダウンエージェント) としての機能を提供し、ノードの状態監視やノードの強制停止で使用するオプションハードウェアへの接続が正しく行えるかを定期的 (10分間隔) に確認します。
PRIMECLUSTER SFでは、以下の非同期監視を提供します。
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、RCIを利用してノードの状態を監視する機能です。ハードウェア本体に標準で実装されているシステム監視機構(System Control Facility: SCFと略する)がハードウェアの状態を監視し、その状態をソフトウェアに通知することでノードダウンを判断することができます。
また、他ノードを意図的にパニックあるいはリセットさせることで確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
注意
RCI 非同期監視のノード状態の監視は、/var/adm/messages ファイルに以下のメッセージ(a) が出力されてから、(b) が出力されるまでの間機能しています。
コンソール非同期監視の場合は、それぞれ(c) と(d) に該当します。
SNMP非同期監視の場合は、それぞれ(e) と(f) に該当します。
MMB非同期監視の場合は、それぞれ (g) と (h) に該当します。
ノード状態の監視が機能していない状態では、ノードを強制的に停止する機能が正常に動作しないことがあります。
(a) FJSVcluster:INFO:DEV:3042: The RCI monitoring agent has been started
FJSVcluster:情報:DEV:3042: RCI非同期監視機能を開始しました。
(b) FJSVcluster:INFO:DEV:3043: The RCI monitoring agent has been stopped
FJSVcluster:情報:DEV: 3043: RCI非同期監視機能を停止しました。
(c) FJSVcluster:INFO:DEV:3040: The console monitoring agent has been started (node:monitored node name) FJSVcluster:情報:DEV: 3040: コンソール非同期監視機能を開始しました。
(node:監視対象ノード名)(d) FJSVcluster:INFO:DEV:3041: The console monitoring agent has been stopped (node:monitored node name) FJSVcluster:情報:DEV:3041: コンソール非同期監視機能を停止しました。
(node:監視対象ノード名)(e) FJSVcluster:INFO:DEV:3110: The SNMP monitoring agent has been started.
FJSVcluster: 情報:DEV:3110: SNMP 非同期監視を開始しました。
(f) FJSVcluster:INFO:DEV:3111: The SNMP monitoring agent has been stopped.
FJSVcluster: 情報:DEV: 3111: SNMP 非同期監視を停止しました。
(g) FJSVcluster:INFO:DEV:3080: The MMB monitoring agent has been started.
FJSVcluster: 情報:DEV: 3080: MMB 非同期監視を開始しました。
(h) FJSVcluster:INFO:DEV:3081: The MMB monitoring agent has been stopped.
FJSVcluster: 情報:DEV: 3081: MMB 非同期監視を停止しました。
クラスタシステムを構成する各ノードのコンソールに表示されるメッセージを監視する機能です。パニック発生時等のコンソールメッセージを他ノードが検出し、メッセージ出力ノードのノードダウンを判断します。コンソール非同期監視は通常、数珠状に1対1の関係で他ノードの状態を監視しており、異常が発生してノードがダウンした場合、ダウンノードが監視していたノードを監視する役目を、その他のノードに引き継ぎます。また、ノードに対してbreak 信号を送信して確実なノード停止を行います。
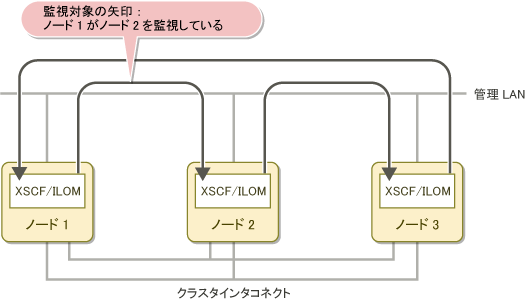
ノードがダウンした場合の監視の引き継ぎについて、3 ノードで構成されるクラスタシステムを例に示します。
以下の図は、 3ノードのクラスタシステムにおいて、1つのノードが停止した場合に監視機能がどのように引き継がれるかを示しています。矢印は、どのノードがどのノードを監視しているかを表します。
図2.3 正常稼動時のコンソール非同期監視の処理
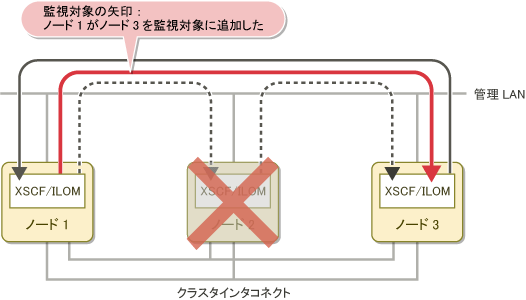
ノード2に異常が発生してダウンすると、以下の処理が実行されます。
ノード1はノード3の状態監視を開始します。
以下のメッセージがノード1の/var/adm/messagesファイルに出力されます。
FJSVcluster:INFO:DEV:3044: The console monitoring agent took over monitoring (node: targetnode)FJSVcluster:情報:DEV:3044: コンソール非同期監視機能の監視対象にノードtargetnodeを追加しました。以下の図は、ノード2が停止した場合に、ノード1がノード3を監視対象ノードとして追加する様子を示しています。
図2.4 ノード異常発生時のコンソール非同期監視の処理
注意
コンソール非同期監視が停止していたときに監視機能の引き継ぎが行われた場合、停止していたコンソール非同期監視が再開されます。
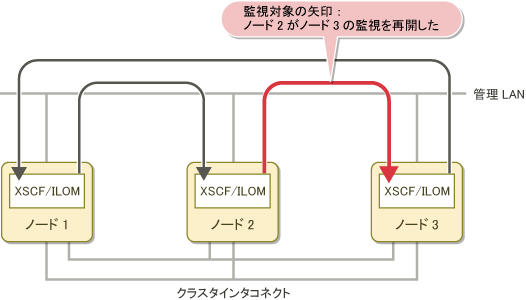
ノード2が異常から復旧後に起動してくると、以下の処理が実行されます。
従来の正常起動時の監視形態に戻ります。
以下のメッセージがノード1の/var/adm/messages ファイルに出力されます。
FJSVcluster:INFO:DEV:3045: The console monitoring agent cancelled to monitor (node: targetnode)FJSVcluster:情報:DEV:3045: コンソール非同期監視機能の監視対象からノードtargetnodeを削除しました。以下の図は、クラスタに復旧したノード2がノード3の監視を再開する様子を示しています。
図2.5 ノード復旧時のコンソール非同期監視の処理
注意
コンソール非同期監視では、コンソールのメッセージを監視しているため、突然の電源切断の状態を判断できずLEFTCLUSTER状態が発生します。本現象が発生した場合は、ノードにDOWNマークを付ける必要があります。DOWNマークの付けかたについては、“PRIMECLUSTER Cluster Foundation 導入運用手引書”を参照してください。
SPARC M10 に搭載されるシステム監視機構(eXtended System Control Facility: XSCFと略する)を利用して、ノードの状態を監視する機能です。
XSCFがハードウェアの状態を監視し、その状態をソフトウェアに通知することで、ノードダウンを判断することができます。
また、他ノードを意図的にパニックあるいはリセットさせることで、確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
PRIMEQUESTに搭載されるハードウェアの1つ、MMBを利用してノードの状態を監視する機能です。ハードウェア本体に標準で実装されているMMBがハードウェアの状態を監視し、その状態をソフトウェアに通知することでノードダウンを判断することができます。
また、他ノードを意図的にパニックあるいはリセットさせることで確実な強制停止を実現し、ユーザ資産への競合を防ぎます。
注意
MMBの異常が発生している状態でノード異常が発生した場合、通常よりノードのダウンを確定するまでにかかる時間が長くなることがあります (最大6秒)。
全ノードで片系のMMB管理LANに異常が発生している状態でノード異常が発生した場合、通常よりノードのダウンを確定するまでにかかる時間が長くなることがあります (最大6秒)。
MMBの異常を検出するには最大20分かかります。
MMBの異常を復旧させた場合、その復旧を検出するには最大10分かかります。ただし、復旧をまだ検出していない状態でノードの異常が発生した場合、その時点で復旧されたことを認識するため、実際にはMMB非同期監視は問題なく動作します。MMBの異常を復旧させた後、すぐにその復旧を検出させたい場合は、シャットダウン機構 (SF) を再起動してください。
自ノードに異常 (snmptrapdが停止) が発生した場合、以下のメッセージが表示されます。
FJSVcluster:INFO:DEV:3084:Monitoring another node has been stopped.
この場合は、ノード状態の監視が機能していない状態となります。よって、この状態でノード異常が発生した場合、通常よりノードのダウンを確定するまでにかかる時間が長くなることがあります。
また、ノード起動またはシャットダウン機構(SF)の再起動後、以下のメッセージが表示されていない場合も、ノード状態の監視が機能していない状態となります。よって、この状態でノード異常が発生した場合、通常よりノードのダウンを確定するまでにかかる時間が長くなることがあります。
FJSVcluster:INFO:DEV:3083:Monitoring another node has been started.
ノード起動中に以下のメッセージが表示されることがあります。
FJSVcluster: INFO: DEV: 3084: Monitoring another node has been stopped.
これは、snmptrapdが起動中のためであり、snmptrapdが起動してから約10分以内に以下のメッセージが出力されれば問題ありません。
FJSVcluster: INFO: DEV: 3083: Monitoring another node has been started.
ノード起動直後にsdtool -s を実行すると、自ノードのテスト状態(Test State)にTestFailedと表示される場合があります。ノード起動直後に自ノードのテスト状態を参照したい場合は、sdtool -r を実行後、sdtool -s を実行してください。
MMBの非同期監視では、MMB管理LANが切断した場合、以下のメッセージが表示されます。
FJSVcluster:WARN:DEV:5021:An error has been detected in part of the transmission route to MMB. (node:nodename mmb_ipaddress1:mmb_ipaddress1 mmb_ipaddress2:mmb_ipaddress2 node_ipaddress1:node_ipaddress1 node_ipaddress2:node_ipaddress2)
FJSVcluster:ERROR:DEV:7213:An error has been detected in the transmission route to MMB. (node:nodename mmb_ipaddress1:mmb_ipaddress1 mmb_ipaddress2:mmb_ipaddress2 node_ipaddress1:node_ipaddress1 node_ipaddress2:node_ipaddress2)
各メッセージの対処法に従い、対処を行ってください。
なお、7213番のエラーメッセージが表示された場合は、ノード状態の監視が機能していない状態となります。よって、ノードを強制的に停止する機能が正常に動作しないことがあります。
また、自ノードに異常 (snmptrapdが異常終了等) が発生した場合は、以下のメッセージが表示されます。
FJSVcluster:ERROR:DEV:7210:An error was detected in MMB. (node:nodename mmb_ipaddress1:mmb_ipaddress1 mmb_ipaddress2:mmb_ipaddress2 node_ipaddress1:node_ipaddress1 node_ipaddress2:node_ipaddress2 status:status detail:detail)
この場合も、ノード状態の監視が機能していない状態となります。よって、ノードを強制的に停止する機能が正常に動作しないことがあります。
メッセージの詳細については、“PRIMECLUSTER 活用ガイド<メッセージ集>” を参照してください。
シャットダウンエージェントはリモートクラスタノードのシャットダウンを保証します。シャットダウンエージェントは、クラスタノードのアーキテクチャによって異なる場合があります。
シャットダウンエージェントは以下の機能を提供します。
ノードの強制停止
異常が発生したノードの強制停止を保証します。
オプションハードウェアの接続確認(シャットダウンエージェントのテスト)
ノードの強制停止で使用するオプションハードウェアへの接続が正しく行えるかを定期的 (10分間隔) に確認します。
PRIMECLUSTER SFでは、以下のシャットダウンエージェントを提供します。
RCI (SA_pprcip, SA_pprcir)
Remote Cabinet Interface
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、RCIを利用して、他ノードを意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
XSCF (SA_xscfp, SA_xscfr, SA_rccu, SA_rccux)
eXtended System Control Facility
SPARC Enterprise Mシリーズに搭載されるハードウェアの1つ、XSCFを利用して、他ノードを意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
また、コンソールにXSCFを使用している場合は、他ノードにbreak信号を送信して確実なノード停止を実現します。
XSCF SNMP (SA_xscfsnmpg0p, SA_xscfsnmpg1p, SA_xscfsnmpg0r, SA_xscfsnmpg1r, SA_xscfsnmp0r, SA_xscfsnmp1r)
eXtended System Control Facility Simple Network Management Protocol
SPARC M10 に搭載されるハードウェアの1つ、XSCF を利用して、他ノードを意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
ALOM (SA_sunF)
Advanced Lights Out Management
SPARC Enterprise T1000、T2000 の ALOM を利用して、他ノードに break 信号を送信して確実なノード停止を実現します。
ILOM (SA_ilomp, SA_ilomr)
Integrated Lights Out Manager
SPARC Enterprise T5120、T5220、T5140、T5240、T5440、SPARC T3、T4シリーズのILOM を利用して、他ノードを意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
KZONE(SA_kzonep, SA_kzoner, SA_kzchkhost)
Oracle Solaris カーネルゾーン
SPARC M10、SPARC T4 シリーズでOracle Solaris カーネルゾーンを使用している場合、他ノード(カーネルゾーン)を意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
また、グローバルゾーンホストの状態を確認し、グローバルゾーンホストが停止した場合に他ノード(カーネルゾーン)が停止状態であると判断します。グローバルゾーンホストの強制停止は行いません。
RPDU(SA_rpdu)
リモート電源制御ユニット
SPARC M10-1、M10-4、SPARC Enterprise M3000, M4000, M5000でリモート電源制御ユニットを使用する場合、ノードの主電源および冗長電源の切断を行うことで、確実なノード停止を実現します。
BLADE (SA_blade)
PRIMERGYブレードサーバで使用可能な機能で、SNMPコマンドを使用して、他ノードをシャットダウンさせることで、確実なノード停止を実現します。
IPMI (SA_ipmi)
Intelligent Platform Management Interface
PRIMERGYに搭載されるハードウェアの1つ、IPMIを使用して、他ノードをシャットダウンさせることで、確実なノード停止を実現します。
kdump (SA_lkcd)
PRIMERGY 、PRIMERGY ブレードサーバで kdump を使用して、他ノードをパニックさせることで、確実なノード停止を実現します。
MMB (SA_mmbp, SA_mmbr)
Management Board
PRIMEQUESTに搭載されるハードウェアの1つ、MMBを利用して、他ノードを意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
ICMP (SA_icmp)
ネットワーク経路を使用して他ノードの状態を確認し、他ノードから応答がない場合に停止状態であると判断します。
他ノードの強制停止は行いません。
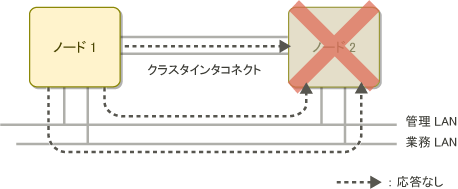
以下の図は、 2ノードのクラスタシステムにおいて、1つのノード(ノード2)が停止した場合のSA_icmp による状態確認の例です。
指定されたすべてのネットワーク経路でノード2から応答がなかった場合、SA_icmpはノード2が停止状態であると判断します。
図2.6 他ノードが停止している場合の SA_icmp による状態確認
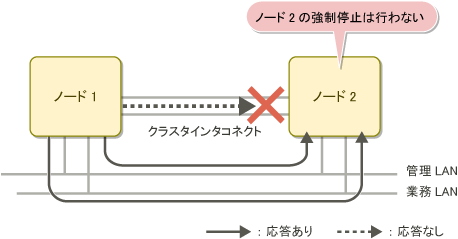
以下の図は、 2ノードのクラスタシステムにおいて、クラスタインタコネクトが故障した場合のSA_icmp による状態確認の例です。
指定されたネットワーク経路のいずれかで、ノード2からノード1に応答があった場合、SA_icmp はノード2が運用状態であると判断します。
この場合、SA_icmp はノード2の強制停止を行いません。
図2.7 クラスタインタコネクトが故障している場合の SA_icmp による状態確認
VMCHKHOST (SA_vmchkhost)
KVM 仮想マシン機能で管理OSにクラスタシステムを導入している場合、管理OSのクラスタシステムと連携してゲストOSの状態を確認します。
他ノードの強制停止は行いません。
libvirt (SA_libvirtgp, SA_libvirtgr)
PRIMERGY 、PRIMERGY ブレードサーバ 、 PRIMEQUEST 1000 / 2000シリーズで KVM 仮想マシン機能を使用している場合、他ノード(ゲストOS)を意図的にパニックあるいはリセットさせることで、確実なノード停止を実現します。
VMware vCenter Server連携(SA_vwvmr)
VMware vCenter Serverと連携し、他ノード(ゲストOS)を意図的に電源断させることで、確実なノード停止を実現します。