Interstage Big Data Parallel Processing Serverでは、以下のハードウェア構成でシステムを構築します。
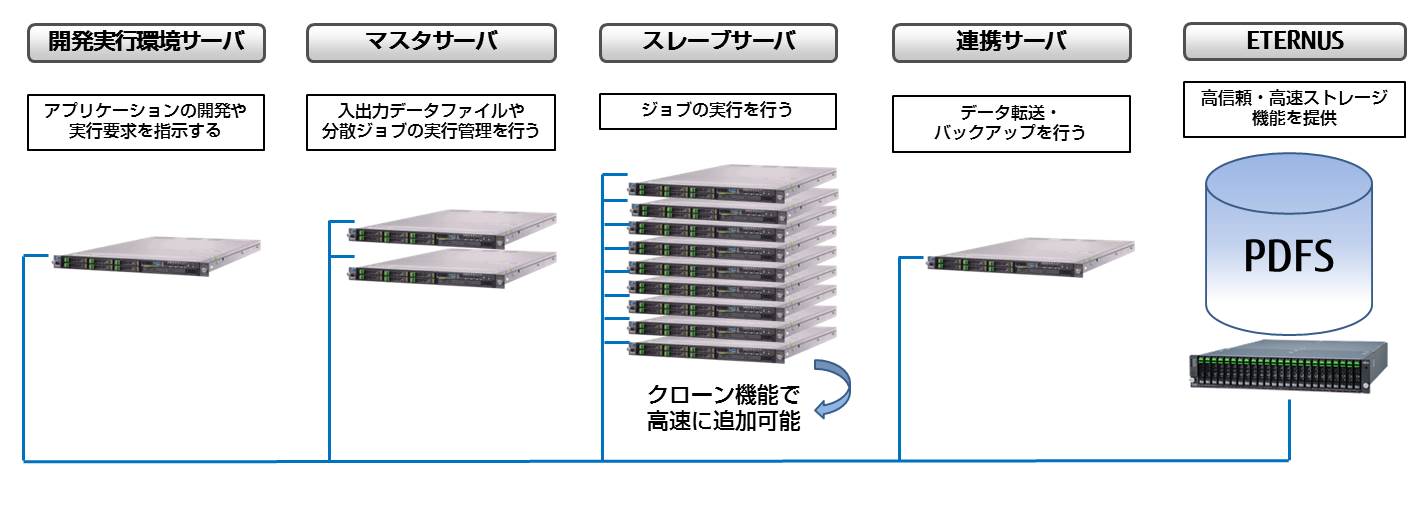
マスタサーバ
大量のデータファイルをブロックに分けた上でファイル化(分散ファイルシステム)し、そのファイル名や保管場所を一元管理するサーバです。また、Hadoopへの実行要求を受け付け、スレーブサーバに対して並列分散処理を実行させることができます。
スレーブサーバ
マスタサーバによってブロック化されたデータファイルを、複数のスレーブサーバが並列分散処理することによって、短時間に分析処理を行うことができます。
開発実行環境サーバ
並列分散を行うアプリケーション(MapReduce)の開発を容易にするPigやHiveを導入し実行するサーバです。
連携サーバ
業務システム上の大量データを直接転送し、分析を行うサーバです。
ETERNUS
Hadoopで使用する入出力データを格納するストレージです。
また、Interstage Big Data Parallel Processing Serverでは、Hadoop分散ファイルシステム(HDFS)に加え、独自の分散ファイルシステム(DFS)が利用できます。業務アプリケーションのデータをいったん「HDFS」に転送してから処理するHadoopに対し、独自の分散ファイルシステムを利用した場合は、データ転送が不要になるため、処理時間を大幅に短縮することができます。
DFSは、Interstage Big Data Parallel Processing Serverを構成するすべてのサーバからアクセス可能な共用ストレージ領域です。
MapReduceアプリケーションはスレーブサーバで実行されます。このため、スレーブサーバにはNetCOBOLの運用環境が必要です。
Hadoop連携機能では、開発実行環境サーバでHadoopジョブを実行します。このため、開発実行環境サーバにはNetCOBOLの運用環境が必要です。また、開発実行環境サーバ上でCOBOLアプリケーションをビルドする場合は、開発実行環境サーバにNetCOBOLの開発・運用環境が必要です。別サーバ上でビルドしたCOBOLアプリケーションを使用する場合は、開発実行環境サーバにはNetCOBOLの運用環境のみをインストールします。
参考
スレーブサーバが複数台の場合でも、「スマートセットアップ」のクローン機能によりNetCOBOLのインストール作業を短時間に行うことができます。「スマートセットアップ」については“Interstage Big Data Parallel Processing Server ユーザーズガイド”を参照してください。