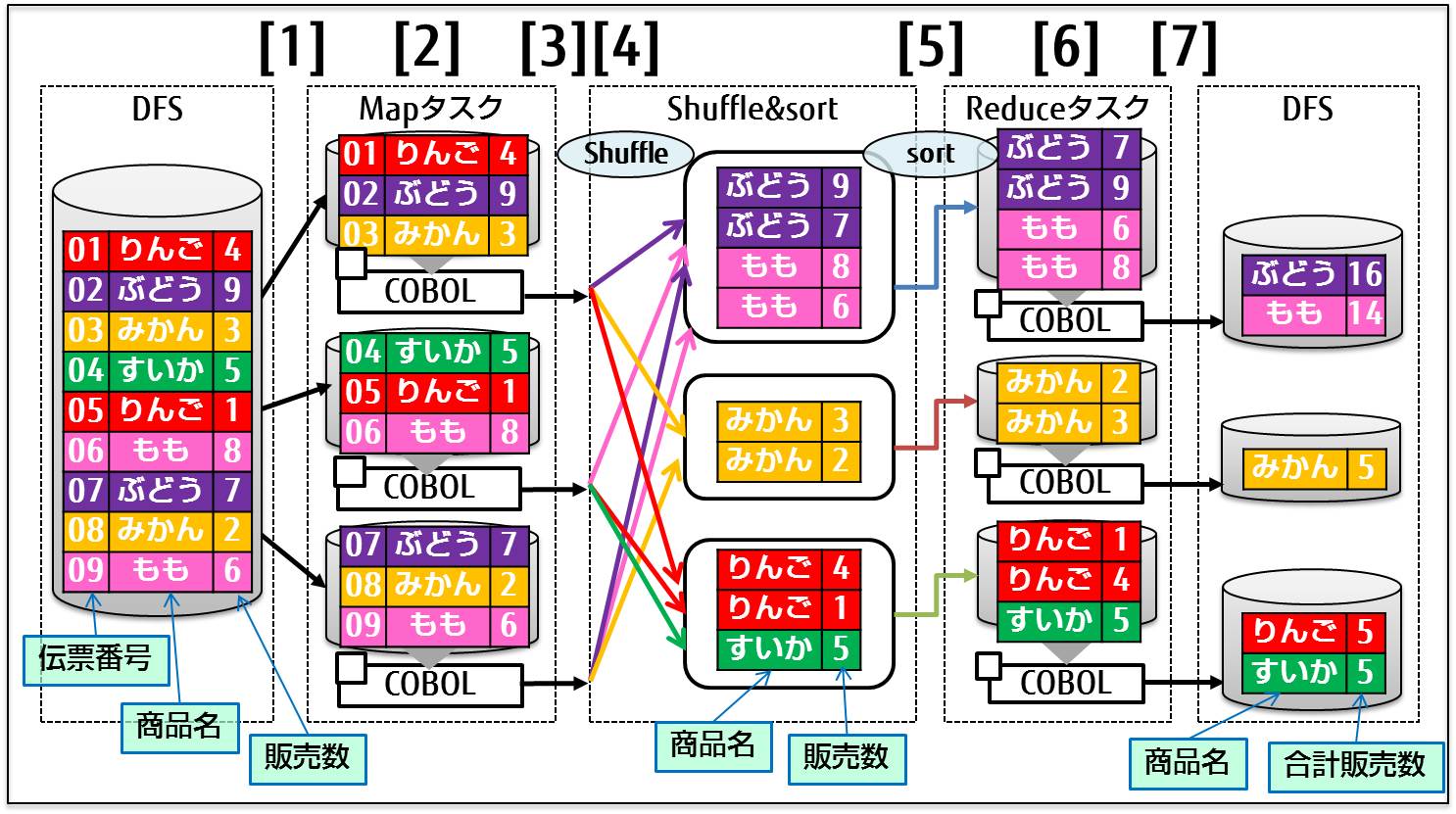
「MapReduce」は、分割された大量のデータをクラスタで分散処理するためのプログラミングモデルおよびフレームワークです。MapReduceフレームワークでは、以下の3つのステップで分散処理を実現します。
Mapタスク
Shuffle&sort
Reduceタスク
MapタスクとReduceタスクは利用者が作成した任意のアプリケーションを実行することができます。
以下に、MapReduceを用いたバッチ処理の流れを示します。
伝票番号、商品名、販売数からなるデータを入力とし、各商品の合計販売数を出力する処理を例とします。
DFS(*)上の入力データが分割され、各Mapタスクに渡されます。([1])
Mapタスクでは、入力データのフィルタリングを行います。([2])
例では各レコードから集計に必要となる商品名、販売数を抽出しています。
抽出したデータをShuffle&sortに渡します。([3])
Shuffle&sortでは、任意のデータをキーとしたレコードの集約、並べ替えが行われます。([4])
商品名をキーとしてレコードを集約したのち、
販売数をキーとしてレコードを並び換えられ、各Reduceタスクに渡されます。([5])
Reduceタスクでは、レコードの集計処理を行います。([6])
同一商品の販売数をまとめ、合計販売数を算出します。
出力データをDFSに格納します。([7])
*:DFSは連携するソフトウェアによって以下のファイルシステムを指します。
Interstage Big Data Parallel Processing Serverと連携する場合
Interstage Big Data Parallel Processing Serverで利用可能な独自の分散ファイルシステム。
Apache hadoopと連携する場合
Hadoop分散ファイルシステム(HDFS:Hadoop Distributed File System)。
図1.1 MapReduceのデータの流れ