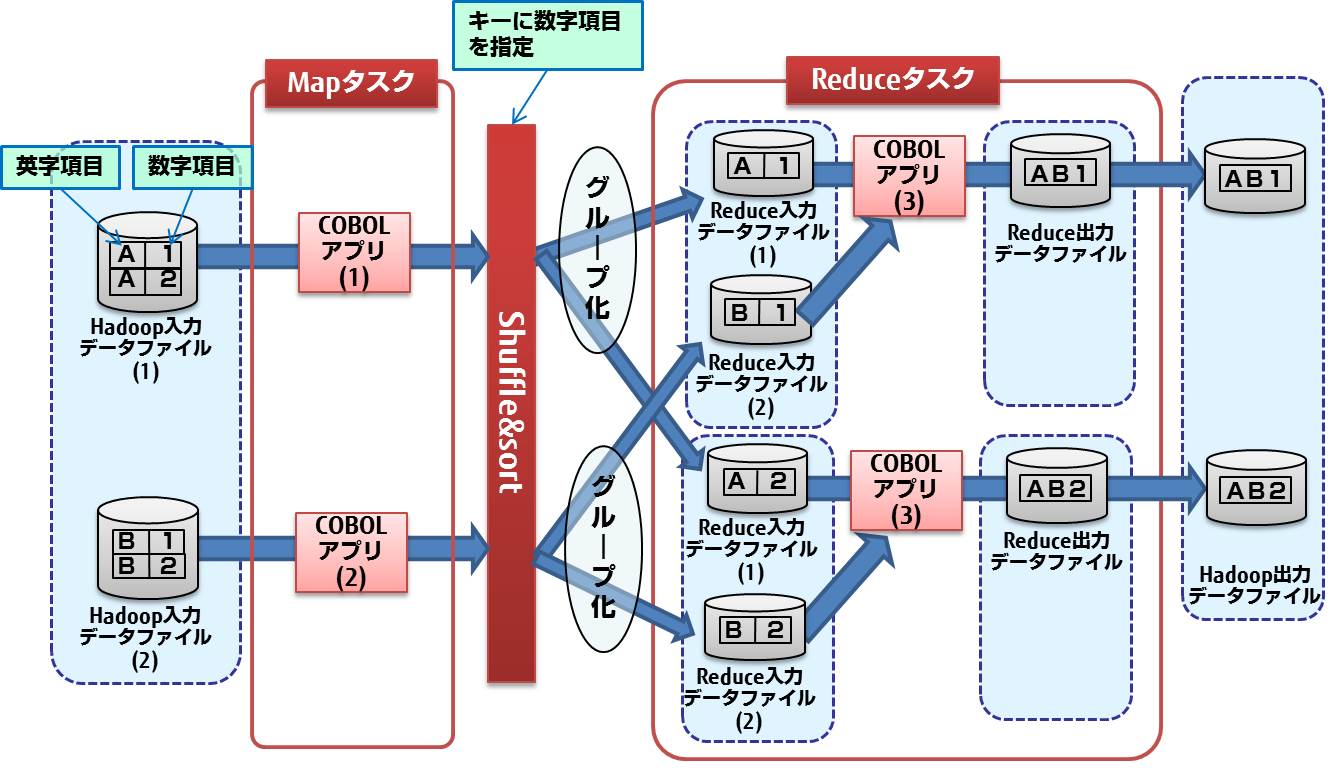
Reduceタスクで使用するReduce入力データファイルおよびReduce出力データファイルは、COBOLランタイムシステムがCOBOLアプリケーションに対して自動的に割当てを行います。このため、あらかじめファイル識別名をMapReduce設定ファイルに指定しておく必要があります。
ReduceタスクのCOBOLアプリケーションは、Hadoop入力データファイルに指定したすべてのファイルをReduce入力データファイルとしてオープンできます。また、複数のReduce出力データファイルをオープンすることができます。
以下の例では、異なる2つのHadoop入力データファイルを割り当ててReduceタスクを実行しています。
Shuffle&sortにキーとして数字項目を指定しグループ化しています。ReduceタスクのCOBOLアプリケーションでは、グループ化されたレコードを読み込んで、同じキーのレコードを結合しています。