FUJITSU Enterprise Postgresでは、処理件数の多い検索処理を、CPU負荷に応じて複数のCPUコアに分散させて並列に処理することで、検索処理の性能向上を実現します。
注意
本機能は、Advanced Editionのみで使用できます。
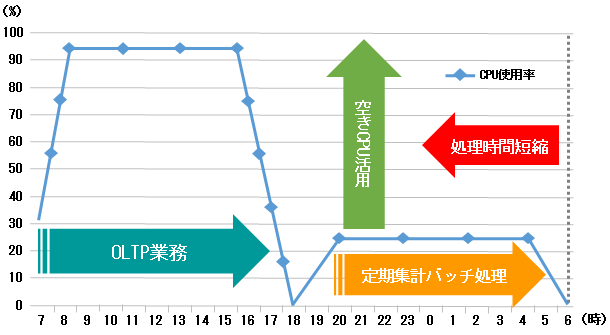
夜間などの定期的な集計処理への適用
以下の図のように、オンライン処理とは隔離された定期集計バッチ処理において、従来のSQLアプリケーションをそのまま実行するだけで、空きのサーバリソースを最大限に活用することが可能となり、大幅な処理時間の短縮が期待できます。
Enterprise Postgresの並列検索では、以下の演算をサポートしています。
シーケンシャルスキャン
集計処理(集約関数、GROUP BY)
本機能は、以下の図のように、処理をデータベースの読み込み範囲ごとに細分化して、CPU負荷に応じて並列化したバックグラウンドプロセス(並列処理プロセスと呼びます)に割り当てます。並列処理プロセスごとに検索結果を用いて集計処理を行い、最後にすべての結果を集計処理して、アプリケーションに結果を返却します。
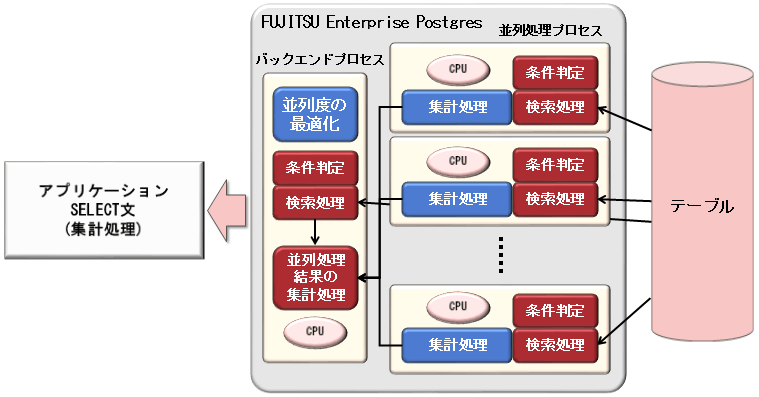
また、CPU負荷が低い場合には、より多くのプロセスで並列に処理しますが、CPU負荷が高い場合には、冗長な並列化を行いません。このような自動的な判断によって、CPUの効率的な使用と検索処理の性能向上が可能となります。
参照
並列検索については、“アプリケーション開発ガイド”の“並列検索”を参照してください。