本製品とSparkの連携方法について説明します。
システム構成例
本製品とSparkを連携させる場合のシステム構成例を以下に示します。以降は、本構成例にしたがって説明します。
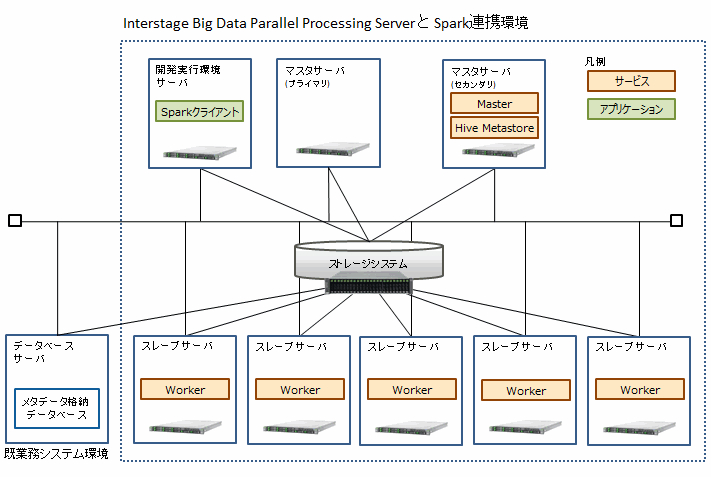
Sparkの構成
Sparkのバージョン | 1.4.1 (Hadoop1用) |
マスタサーバ(セカンダリ)のホスト名 | master2 |
マスタサーバ(セカンダリ)の業務LANのIP | 10.10.10.12 |
スレーブサーバのホスト名(5台) | slave6、slave7、slave8、slave9、slave10 |
開発実行環境サーバのホスト名 | develop |
Spark実行ユーザー名 | spark |
Spark利用ユーザー名 | sparkuser1 |
Spark実行ユーザーグループ名 | bdppgroup(*1) |
Spark利用ユーザーのグループ名 | |
Sparkインストールディレクトリ | /usr/local/spark-1.4.1-bin-hadoop1 |
Hiveの構成
Hiveのバージョン | 0.13.1 |
Hiveインストールディレクトリ | /usr/local/apache-hive-0.13.1-bin |
データベースの構成
RDBソフトウェア | MySQL(バージョン5.6.28) |
データベース名 | metastore_spark |
DBユーザー名 | hive |
DBユーザーのパスワード | hive_password |
*1:Spark実行ユーザーが属するグループID、グループ名には、Hadoop利用ユーザーのグループID、グループ名を設定します。
ポイント
本製品の基本機能のインストール・セットアップが完了したサーバであれば、マスタサーバやスレーブサーバなどの種別に関係なく、どのサーバでもSparkに必要なサービス(Master、Worker、Hive Metastore)を実行できます。
注意
データベースサーバには本製品とSparkをインストールする必要はありませんが、Hive MetastoreからJDBCで接続可能なデータベースを作成しておく必要があります。メタデータを格納するデータベースとして、HiveがサポートしているRDBソフトウェアを使用できます。