運用開始後に、さらにスレーブサーバを追加する方法について説明します。
スレーブサーバを追加する方法には、以下の2つがあります。
Hadoop を停止してスレーブサーバを追加する
Hadoop を起動したままスレーブサーバを追加する
スレーブサーバの追加の流れを以下に示します。
スレーブサーバ追加の作業は、すべて root 権限で実施します。
なお、「13.1.4 スレーブサーバの追加」の手順は、追加導入するスレーブサーバの環境に応じて実施場所が異なります。
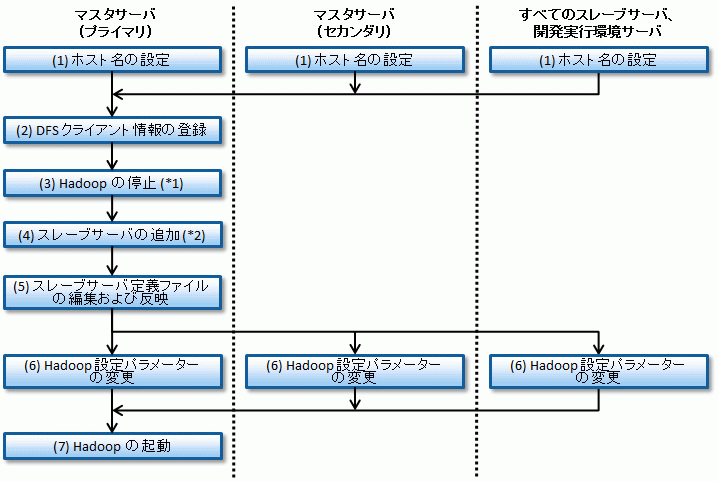
*1: Hadoop を起動したままスレーブサーバを追加する場合、本作業は不要です。
*2: Hadoop を起動したままスレーブサーバを追加する場合は、クローニング機能を利用しないでスレーブサーバを追加する必要があります。クローニング機能は、クローン元のスレーブサーバが停止してしまうため、利用できません。
ここでは、初回導入時に「6.3 2台目以降のスレーブサーバの追加」で構築済みの構成に加えて、さらに追加導入する手順を以下の環境を例に説明します。
| :/dev/disk/by-id/scsi-1FUJITSU_300000370106 |
| :1 |
| :/mnt/pdfs |
| :master1(プライマリ)、master2(セカンダリ) |
| :slave1、slave2、slave3、slave4、slave5 |
| :slave6 |
| :slave7、slave8、slave9、slave10 |
注意
Hadoop を起動したままスレーブサーバを追加する場合、実行中の Hadoop ジョブでは、追加したスレーブサーバが使用されません。
「13.1.7 Hadoop の起動」の作業が完了した後に実行した Hadoop ジョブから、追加したスレーブサーバが使用されます。