表の全件検索が行われている場合
アクセスプランに表示される以下を参考にして、インデックスを使用した検索処理に変更します。
CONVERT SQL Statement
Advice to an SQL statement
インデックスのチューニング
PRIMEFLEX for HA Databaseは、検索に利用できるインデックスが複数存在する場合に、検索範囲の最も小さいインデックスを採用します。検索範囲の大きさは、WHERE探索条件に指定した条件と、インデックスに設定している最適化情報の異なるキー値数から計算しています。
すでに、インデックス検索を実施しているが、使用するインデックスを変更したい場合のチューニング方法を説明します。
インデックスの検索範囲は、インデックスのデータ部の“1/異なるキー値数”の範囲を検索すると計算します。したがって、異なるキー値数の大きいインデックスの方が検索範囲が狭いと考え、優先的に選択されます。
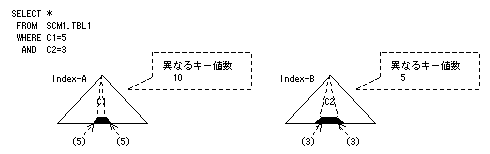
インデックスAの検索範囲の大きさは1/10で全体の10%となります。一方、インデックスBの検索範囲の大きさは1/5で全体の20%となるので、インデックスAが選択されます。もし、インデックスBを優先的に選択させたい場合は、インデックスBの異なるキー値数を10より大きくすることで、インデックスAよりも優先して使用されるようになります。
マルチカラムインデックスの場合
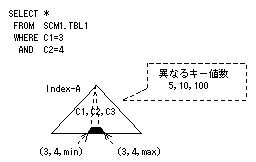
マルチカラムインデックスの場合は、比較述語の比較演算子“=”条件が続く部分までの1/異なるキー値数が検索範囲の大きさとなります。上記例では、インデックスAの検索範囲の大きさは1/10で10%となります。なお、インデックスの途中の列に条件を指定しない場合は、それ以降の列に条件を指定しても検索範囲の大きさは変わりません。

IN述語を指定している場合の検索範囲は、(1/異なるキー値数)×IN値リスト数となります。同じ列に対して、比較述語“=”をORで複数指定した場合も同じです。
BETWEEN述語や比較述語“>(=)”や“<(=)”、LIKE述語を指定している場合は、それぞれの述語に応じた固定的な検索範囲の割合(選択率といいます)で検索範囲の大きさを決定します。各述語ごとの選択率は、デフォルトで次のようになっています。
述語の種類 | 選択率 |
|---|---|
BETWEEN | 0.2 (20%) |
>(=)と<(=)の両方をANDで指定 | 0.25 (25%) |
LIKE述語を指定 | 0.4 (40%) |
>(=)または<(=)のみを指定 | 0.5 (50%) |
これらの値は、最適化パラメタ“SS_RATE”で変更することができます。
参照
“SS_RATE”の詳細については、“Symfoware Server SQLTOOLユーザーズガイド”の“CHANGE ENV文”を参照してください。
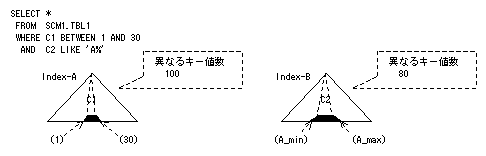
インデックスAの検索範囲の大きさは全体の20%となります。一方、インデックスBの検索範囲の大きさは全体の40%となるので、インデックスAが選択されます。実際には、LIKE述語の方が絞り込める確率が高い場合は、最適化パラメタ“SS_RATE”でLIKE述語の選択率を20%より小さくすると、インデックスBが優先して使用されるようになります。
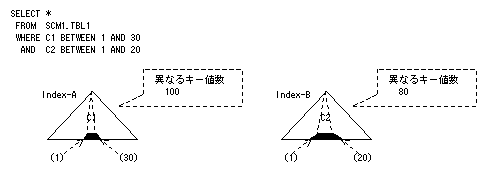
同じ述語を指定した場合は、異なるキー値数の大きいインデックスが優先されます。この場合は、インデックスAが選択されます。インデックスBを選択したい場合は、インデックスBの異なるキー値数を100より大きい値に変更するか、または、次のようにSQL文を書き換えてください。
SELECT * FROM SCM1.TBL1 WHERE C1 >=1 AND C1 <=30 AND C2 BETWEEN 1 AND 20
上記のようにSQL文を変更すると、インデックスAの検索範囲は25%となり、インデックスBが優先して選択されます。
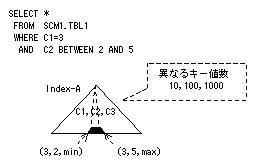
マルチカラムインデックスの場合は、比較述語の比較演算子“=”条件が続く部分までの1/異なるキー値数に、比較述語“=”以外を指定した述語の選択率を掛けたものが検索範囲の大きさとなります。この場合は、1/10×0.2で2%の大きさとなります。
最適化情報や最適化パラメタを変更すると、他のアプリケーションやSQL文に悪影響がでる場合があります。このような場合、ASSIST指定の“USE_INDEX”を利用すると、最適化情報や最適化パラメタを変更することなく、検索で使用するインデックスを固定化することができます。
最適化パラメタについては、“5.5 性能チューニングのためのパラメタ一覧”を参照してください。
参照
ASSIST指定の使用方法については、“Symfoware Server アプリケーション開発ガイド(共通編)”を参照してください。
IN述語についてインデックス検索を行う場合、限定値リストの数がインデックスの検索範囲の数になります。限定値リストを大量に指定すると、SQL文の処理手順も大きくなり、SQL文の処理手順を格納するバッファの使用量が増加します。この増加をおさえるため、最適化パラメタ“MAX_SCAN_RANGE”で検索範囲の最大数を制限します。制限値を超えると、そのIN述語のインデックス検索は行いません。他にインデックスの検索範囲にできる探索条件がなければ、表の全件検索になります。一般には、インデックス検索の性能は良いので、十分なバッファがある場合は“MAX_SCAN_RANGE”の値を大きくすることで、限定値リストを大量に指定したIN述語のインデックス検索を行うようになります。
SQL文の処理手順を格納するバッファを大きくする場合は、動作環境ファイルのパラメタ“OPL_BUFFER_SIZE”に指定する値を大きくしてください。その際、IN述語の限定値リストの数を述語の数として見積もってください。
インデックスと同様に、クラスタキーや分割キーを使った検索にもMAX_SCAN_RANGEは有効です。また、IN述語と同様に、OR論理演算子を大量に指定した探索条件や、行値構成子を大量に指定した探索条件にもMAX_SCAN_RANGEは有効です。
インデックスの検索範囲の数は以下のように決まります。
1つの列から構成されるインデックスを検索する場合
SELECT * FROM S1.T1 WHERE C1 IN(1,2,3,…,3000) …限定値リストに指定した値指定が3000個
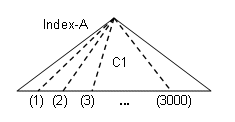
インデックスの検索範囲はC1=1、C1=2、C1=3、 … 、C1=3000の3000個となります。インデックス検索したい場合は、“MAX_SCAN_RANGE”に3000以上を指定してください。
ただし、限定値リストを大量に指定したIN述語を2個以上使ってマルチカラムインデックスの検索を行う場合は、実行時間が表の全件検索より長くなる場合がありますので、チューニング後は、性能測定を行って妥当性を確認してください。
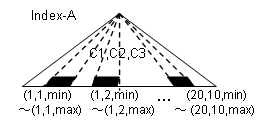
複数の列から構成されるインデックスを検索する場合
SELECT * FROM S1.T1 WHERE C1 IN(1,2,3,…,20) … 限定値リストに指定した値指定が20個 AND C2 IN(1,2,3,…,10) … 限定値リストに指定した値指定が10個 AND C3 IN(1,2,3,…,30) … 限定値リストに指定した値指定が30個
インデックスの検索範囲は最適化パラメタ“MAX_SCAN_RANGE”の値を超えない範囲で、インデックス構成列の先頭の列から順番にIN述語の限定値リストを組み合わせて作成します。インデックスの検索範囲は、限定値リストの数の積になります。このような場合、マルチカラムインデックス検索が表の全件検索よりも遅くなる可能性がありますが、下表のようにMAX_SCAN_RANGEを指定することで、インデックスの検索範囲の最大数を制限することができます。
MAX_SCAN_RANGEの値 | 検索範囲の数 | 使用するインデックス構成列 | アクセスプラン |
|---|---|---|---|
1 ~ 19 | 0個 | - | 表の全件検索、または |
20 ~ 199 | 20個 | C1 | インデックス範囲検索 |
200 ~ 5999 | 200個 | C1,C2 | インデックス範囲検索 |
6000以上 | 6000個 | C1,C2,C3 | インデックス範囲検索 |
このインデックスの検索範囲を使用したインデックス検索は行いません。
C1に対するIN述語から20個の検索範囲を作りインデックスを検索します。

C1とC2に対するIN述語から以下のように20×10=200(個) の検索範囲を作りインデックスを検索します。
(C1,C2)=(1,1)、(1,2)、…、(20,10)
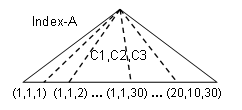
C1、C2、C3に対するIN述語から以下のように20×10×30=6000(個) の検索範囲を作りインデックスを検索します。
(C1,C2,C3)=(1,1,1)、(1,1,2)、…、(1,1,30)、…、(20,10,30)
ポイント
検索に使用できるインデックスが複数ある場合は、次の優先順位で使用するインデックスを決定しています。
検索範囲が最も小さいインデックスを優先する
(a)で同じものが複数あれば、インデックスで判定できる条件の多いものを優先する。
(b)で同じものが複数あれば、検索範囲に使用した構成列までの異なるキー値数の大きいものを優先する。