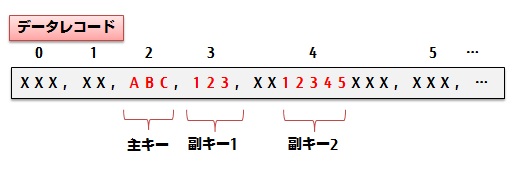
Shuffle&sortで使用するキー情報には、データのグループ化に使用される「主キー」と、並び替えに使用される「副キー」があります。主キーおよび副キーは複数指定可能です。キーごとに属性や並び順(昇順・降順)を指定することができます。
キー情報は、Hadoop入力データファイルごとに指定する必要があります。
設定内容 | 設定名(*) | 設定値 | 備考 |
|---|---|---|---|
主キー | extjoiner.sortkey.nn.main | カンマ区切りで キー属性,カラム目,並び順 または キー属性,カラム目:開始オフセット-長さ,並び順 を指定します キー属性 CSVまたはCSVN CSV:キーを文字として評価します CSVN:キーを数値として評価します カラム目:開始オフセット-長さ キーが存在するカラム目と、カラム内にあるキーの先頭オフセットおよび長さをバイト長で指定します 開始オフセットのみを指定した場合(-長さが指定されていない場合)は、カラムの末尾までを長さと見なします 並び順 A(昇順)またはD(降順)を指定します 省略した場合、昇順と見なします | Shuffle&sortを使用する場合、指定必須 主キーを指定します 複数指定する場合は/(スラッシュ)で区切って指定します このキーでグループ化されたデータが各Reduceタスクに渡されます |
副キー | extjoiner.sortkey.nn.sub | 省略可 副キーを指定します。 複数指定する場合は/(スラッシュ)で区切って指定します カラムは0番目から始まります データ自体にセパレータ文字を含めたい場合は、カラムをダブルクォーテーションで囲む必要があります ただし、浮動フィールド指定にtrueが指定されている場合、フィールドを囲むダブルクォーテーションを考慮しません | |
指定例 |
<name> extjoiner.sortkey.01.main</name> <value>CSV,2,A</value> <name> extjoiner.sortkey.01.sub</name> <value>CSVN,3,D/CSVN,4:2-5,D </value>
| ||