本機能では、入力ファイルと出力ファイルを指定して実行できる外部プログラムを使用します。本機能から呼び出される際のコマンドラインのイメージは以下のようになります。
$ Mapタスクとして実行する外部プログラム [プログラム固有のオプション] 入力ファイル名 出力ファイル名
$ Reduceタスクとして実行する外部プログラム [プログラム固有のオプション] 入力ファイル名 出力ファイル名
Hadoopジョブの実行時には、各スレーブサーバの各タスクごとにディレクトリが割り当てられます。外部ブログラムは、そのディレクトリをカレントディレクトリとして起動されます。
カレントディレクトリは他のタスクとは重複しないため、外部プログラムが独自に出力したデバッグ情報用のファイルや、外部プログラムの標準出力・標準エラー出力の内容等の配置先として利用します。また、後述する11.7.4 主キー一覧ファイルなど、Hadoopの機能により配布され各タスクから参照することができるサイドデータも配置されます。
ポイント
Hadoopを使用せずに単独で実行する場合、以下のように実行することでHadoopで並列処理を行った場合と同じ結果を得ることができます。
処理対象のデータを、『Mapタスクとして実行する外部プログラム』の入力ファイルに指定して実行
1.の出力ファイルを、『Reduceタスクとして実行する外部プログラム』の入力ファイルに指定して実行
また、本機能では以下のような入出力ファイルを使用します。
Hadoop入力データファイル
Map入力データファイル
Map出力データファイル
Reduce入力データファイル
Reduce出力データファイル
Hadoop出力データファイル
このうち、外部プログラムが本機能から呼び出される際に指定される入出力ファイルは、Map入力/出力データファイル、またはReduce入力/出力データファイルです。各ファイルについての詳細は後述します。
本機能を使用する際は、呼び出す外部プログラムや、処理対象となるHadoop入力/出力データファイルなどをあらかじめ設定ファイルに記述しておきます。この設定ファイルを「MapReduce設定ファイル」と呼びます。
MapタスクおよびReduceタスクとして実行する外部プログラムと入出力ファイル、MapReduce設定ファイルの概念を以下の図に示します。
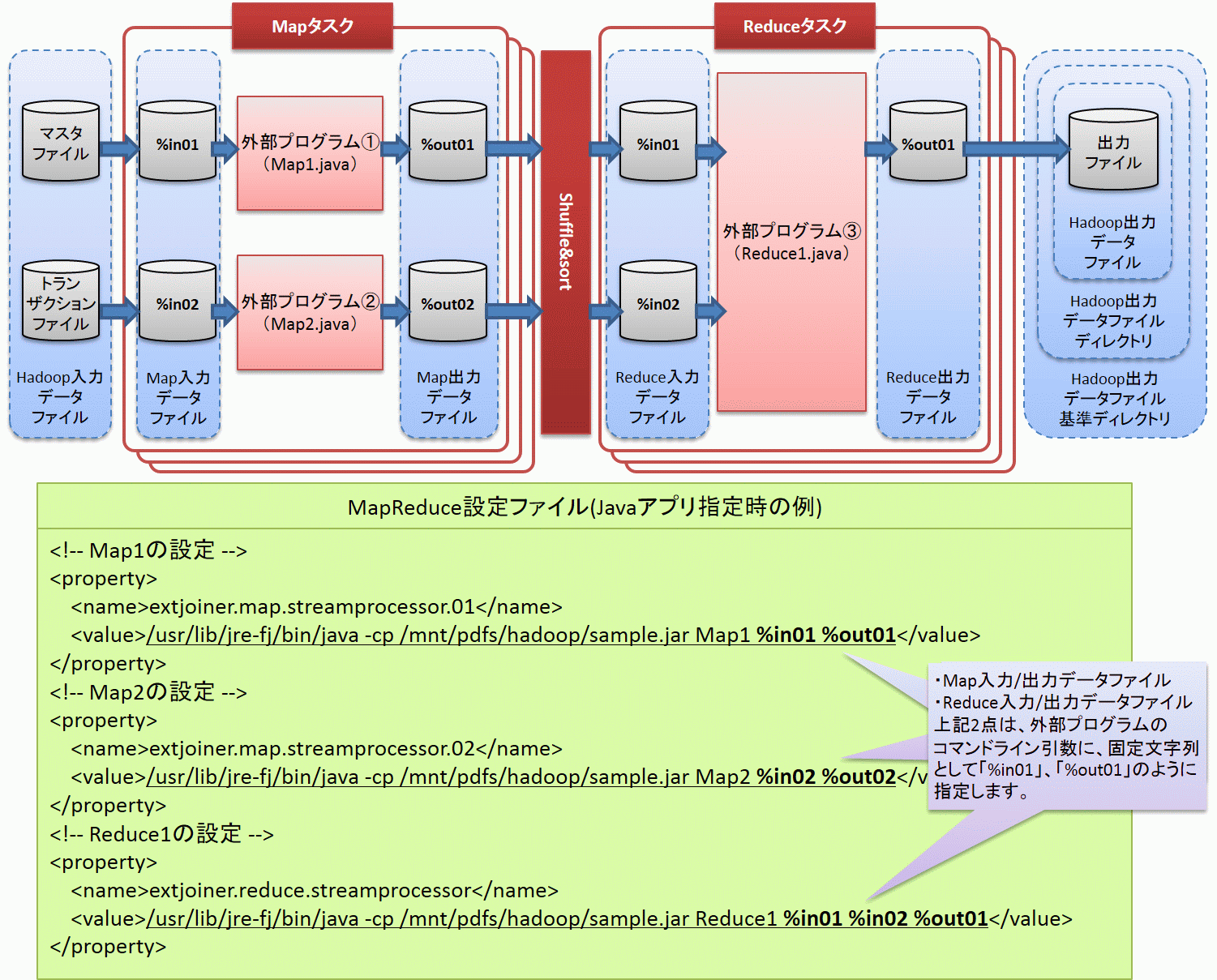
以降で、本機能における各ファイルとMapタスク、Shuffle&sortおよびReduceタスクについて説明します。
Hadoop入力データファイル
Hadoopによって分割され、各Mapタスクに渡されるファイルを「Hadoop入力データファイル」といいます。Hadoop入力データファイルは分割可能なデータファイルである必要があり、トランザクションファイルやマスタファイルなどをHadoop入力データファイルに使用します。
参考
Mapタスクに渡されるファイルは自動的に分割されますが、レコードの途中で分割されることはありません。
Mapタスク
Mapタスクには、一定サイズに単純分割されたHadoop入力データファイルが割り当てられます。この割り当てられたファイルのことを「Map入力データファイル」といいます。必要に応じて外部プログラムでデータを加工し、ファイルに出力することで後続のShuffle&sortに渡します。この出力ファイルのことを「Map出力データファイル」といいます。Map出力データファイルは、CSV形式のデータである必要があります。
Mapタスクでは、MapReduceフレームワークによって単純に分割されたファイルが入力になります。このため、Mapタスクではすべてのレコードを一律に加工する処理など、入力データを分割して処理しても問題ないものを実装します。
Map入力データファイルとMap出力データファイルのパスは、それぞれ外部プログラム実行時のコマンドライン引数として渡されます。外部プログラムでは引数で渡されたファイルパスに対して、ファイル読み込み・ファイル書き込みの処理を実装してください。
参考
Mapタスクは省略することもできます。省略した場合、Hadoop入力データファイルがそのままMap出力データファイルとしてShuffle&sortに受け渡されます。
Shuffle&sort
Shuffle&sortはMapタスクから渡されたデータをレコード単位に分割し、指定されたキーの単位でグループ化・ソートして後続のReduceタスクへ振り分けます。本機能では、HadoopのPartitioner機能でグループ化・ソートするためのキーを「主キー」といいます。また、ソートするためのキーとして「主キー」に加えて、別のキーを指定することも可能です。このソートだけに使用するキーを「副キー」といいます。
また、本機能ではShuffle&sortからReduceタスクへのレコード振り分けの際に、以下の3つの振り分け条件を選択することが可能です。
ハッシュ値により振り分ける
キー分布を考慮し自動的に最適な条件に振り分ける
キーごとに異なるタスクに振り分ける
主キー、副キーおよび振り分け条件は、MapReduce設定ファイルで指定します。
参考
キー情報には、キーごとに異なる種別、順序(昇順・降順)を指定することができます。
Reduceタスク
Reduceタスクには、キー単位にグループ化されたファイルが割り当てられます。この割り当てられたファイルのことを「Reduce入力データファイル」といいます。必要に応じて外部プログラムでデータを加工し、ファイルに出力します。この出力ファイルのことを「Reduce出力データファイル」といいます。
Reduceタスクには、Shuffle&sortによって主キー単位にグループ化されたレコードが渡されます。また、レコードは主キーおよび副キーでソート済になっています。このため、Reduceタスクではデータを集計したり、突き合わせたりする処理などを実装します。
Reduce入力データファイルとReduce出力データファイルのパスは、それぞれ外部プログラム実行時のコマンドライン引数として渡されます。外部プログラムでは引数で渡されたファイルパスに対して、ファイル読み込み・ファイル書き込みの処理を実装してください。
参考
Reduceタスクは省略することもできます。省略した場合、Reduce入力データファイルがそのままReduce出力データファイルとしてファイルに出力されます。
Reduceタスクを省略する場合、Hadoopのプロパティ「mapred.reduce.tasks」に「0」を指定してください。
Hadoop出力データファイル
各Reduceタスクから出力されるファイルを「Hadoop出力データファイル」といいます。Hadoop出力データファイルは実行されたReduceタスクごとに出力されます。