Hadoop の処理サーバへのデータ転送時間を削減
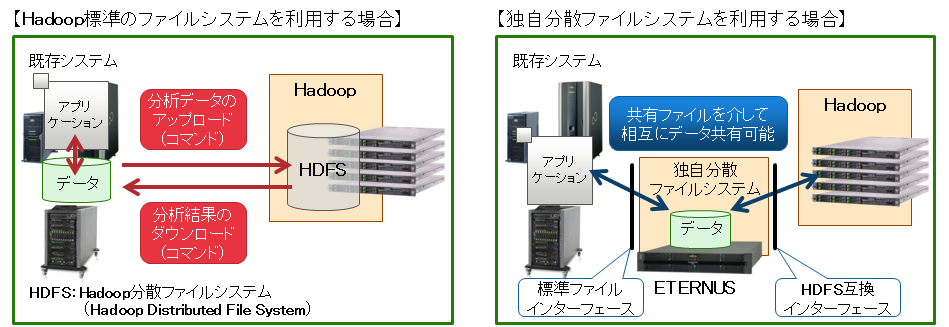
「Apache Hadoop」の分散ファイルシステム(HDFS)に加え、独自の分散ファイルシステム(DFS)によりストレージシステムに格納したデータに直接アクセスして処理することができます。
業務アプリケーションのデータを一旦「HDFS」に転送してから処理する Hadoop に対し、独自の分散ファイルシステムを利用した場合は、データ転送が不要になるため、処理時間を大幅に短縮することができます。
既存ツールをそのまま活用
データを格納するストレージシステムとのインターフェースは、Linux 標準のため、バックアップや印刷などの既存ツールをそのまま活用することができます。