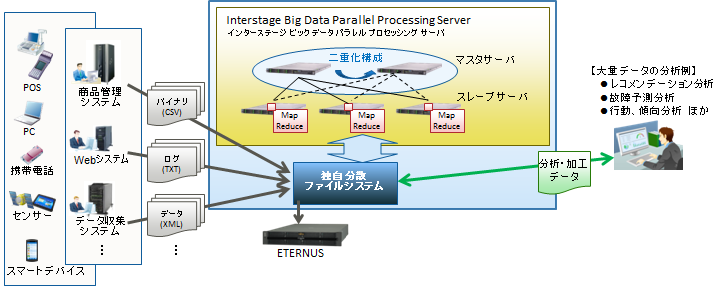
Interstage Big Data Parallel Processing Server は、ビッグデータ処理の業界標準である「Apache Hadoop」に、当社独自の技術を搭載したソフトウェアです。
近年、スマートフォン、タブレット端末などのスマートデバイスや各種センサーから収集されるデータは、大量であるとともに、形式や構造がバラバラであり、しかも刻々と増え続けています。これらの「ビッグデータ」と呼ばれるデータは、先進企業を中心に活用が進み、これまで得られなかったビジネスメリットを続々と創出していることから、大きな注目を集めています。
本製品は、信頼性と処理性能の大幅な向上と、システム導入時間の短縮、および運用管理にかかる負荷軽減を実現し、企業システムでのビッグデータ活用を支援します。
ビッグデータには次の特徴があります。
大量のデータ
TB(テラバイト)~PB(ペタバイト)に及ぶ大容量で多数のデータ
多様なデータ
様々な形式のデータ(構造化データ(データベースのデータ)・非構造化データ(センサー情報、アクセスログ情報などのテキストデータ) ・半構造化データ(構造化データ、非構造化データの両方の性質を持つデータ))
高頻度で発生するデータ
センサーなどから刻々と新しく発生するデータ
リアルタイムに使いたいデータ
短時間で分析処理を行い、リアルタイムに利活用
上記ビッグデータ処理のうち、(1)大量データ処理、(2)多様なデータ解析が可能なアプリケーションとして、「Apache Hadoop(*1)」が業界標準として、広く利用されてきています。
*1 Apache Hadoop: Apache Software Foundation(ASF) が開発したビッグデータの効率的な分散・並列処理を行うオープンソースソフトウェア
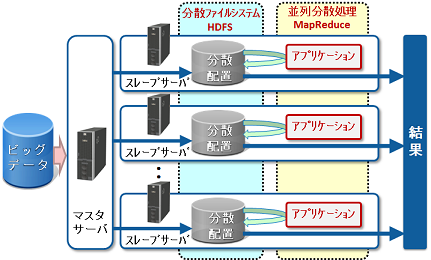
大量データを分割かつ、数十~数千台のサーバに分散配置して並列処理することによって、大量のデータに対するバッチ処理を短時間で処理する技術であり、次の特長があります。
低コスト
比較的安価なサーバを多数使用して並列処理することで、経済的なシステムを構成できます。
高可用性
分割されたデータは3か所以上に分散配置されることによって、並列処理を実行するサーバ(スレーブサーバ)は同時に2台停止しても、処理を続行することができます。
スケールアウト
スレーブサーバの追加により、容易にスケールアウトできます。
多様なデータ処理
文字列検索などの単純な分析から、画像解析などの高度な分析ロジックに対応する並列分析処理アプリケーション(MapReduce アプリケーション)を開発することができ、多様な形式のデータを処理することができます。