データベースから検索用データを再登録する場合は、抽出データファイルの再作成が必要になります。
抽出データファイルの再作成の作業の流れを以下に示します。
図4.5 抽出データファイルの再作成手順
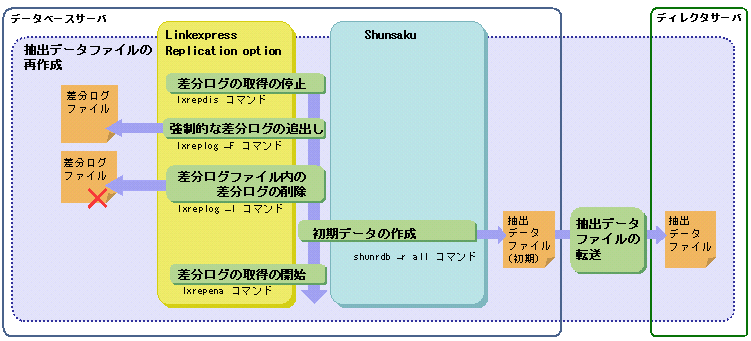
抽出データファイルの再作成は以下の手順となります。
差分ログの取得を停止します。差分ログの取得を停止するには、lxrepdisコマンドを使用します。
差分ログファイルに格納していない差分ログを差分ログファイルに追い出します。差分ログファイルの追出しは、lxreplogコマンドのFオプションを使用します。
差分ログファイルに格納されている差分ログを削除します。差分ログの削除は、lxreplogコマンドのIオプションを使用します。lxreplogコマンドのIオプションの実行により、登録した抽出定義に対応する差分ログが、すべて削除されます。
初期データ用の抽出データファイルを再作成します。shunrdbコマンドのrオプションの“all”を実行して、データベースの表に格納されているすべてのデータから初期データ用の抽出データファイルを作成します。詳細は、“4.2.1.2 初期データの抽出”を参照してください。
差分ログファイルに差分ログを蓄積します。抽出定義名を入力情報としてlxrepenaコマンドを実行します。これにより、差分ログの取得が開始され、差分ログファイルに差分ログが蓄積されます。
再作成した抽出データファイルは、ディレクタサーバに転送(ftpなど)します。
注意
ftpでファイル転送する場合、バイナリモードで転送してください。
以下に、抽出データファイルの再作成の操作例を示します。
抽出定義名は“書籍データ抽出定義”です。
作成される抽出データファイル名は“/usr/XML/list1”です。
lxrepdis -r 書籍データ抽出定義 (1) lxreplog -F (2) lxreplog -I -r 書籍データ抽出定義 (3) shunrdb -r all -l 書籍データ抽出定義 -f /usr/XML/list1 -w /var/tmp (4) lxrepena -r 書籍データ抽出定義 (5)
(1)差分ログの取得を停止します。
(2)差分ログを追い出します。
(3)差分ログを削除します。
(4)初期データ用の抽出データファイルを再作成します。
(5)差分ログの取得を開始します。
注意
抽出先ディレクトリ(上記の例では“/usr/XML”)がない場合は、shunrdbコマンド実行前に抽出先ディレクトリを作成してください。また、抽出先ディレクトリに書込み権がない場合は、書込み権を付加しておいてください。