XML文書の中から必要なXML文書を検索する場合、はじめからXML文書の全体を取得するのではなく、XML文書を識別するのに有効な部分情報を取得します。利用者は、これらの部分情報から詳細情報を取得したいXML文書を特定します。
XML文書の全体を取り出すには、部分情報を取り出したときに一緒に返却されるレコードIDを使用します。レコードIDを利用することで目的のXML文書の全体を取り出すことができます。
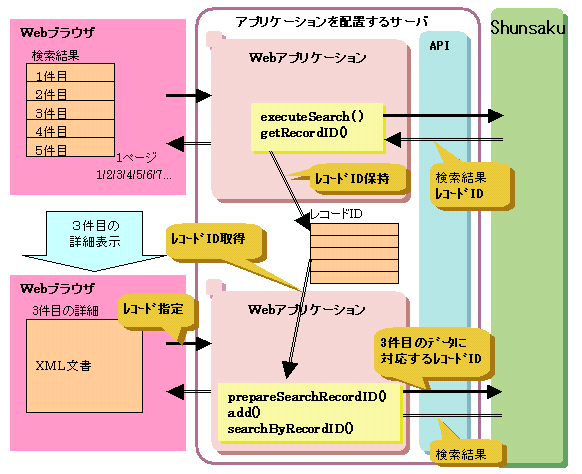
レコードIDを利用してXML文書全体を取得する場合の流れについて、以下の図に示します。
図K.8 レコードIDを利用してXML文書全体を取得する場合の流れ
記述例
レコードIDを用いてXML文書全体を取り出す方法についてビジネスクラス、Shunsakuアクセスクラスの記述例を以下に示します。
ビジネスクラス
ShunConnection con = new ShunConnection(); ShunsakuAccessController controller = new ShunsakuAccessController(con); Object[] resultData = controller.detail(recordID); controller.close(); con.close(); |
Shunsakuアクセスクラス
public Object[] detail(String recordID) throws ShunException {
Object[] resultData = null;
ShunPreparedRecordID prid = con.prepareSearchRecordID(); (1) |
ShunPreparedRecordIDオブジェクトの作成は、prepareSearchRecordIDメソッドを使用します。
レコードIDの設定は、addメソッドを使用します。レコードIDはgetRecordIDメソッドで取得します。
addメソッドで複数のレコードIDを設定できます。すでに同一のレコードIDが設定されている場合は上書きします。
ポイント
addメソッドで複数のレコードIDを指定することで、一度に複数のXML文書を取得することができます。
検索の実行はsearchByRecordIDメソッドを使用します。検索した結果としてShunResultSetオブジェクトが作成されます。
parseResultSetメソッドのパラメタにShunResultSetオブジェクトを指定して、検索した結果を取り出します。
ShunResultSetオブジェクトとShunPreparedRecordIDオブジェクトは、使用後にそれぞれのcloseメソッドで必ず解放します。