This section explains operations when an error occurs on a slave server.
When the events shown below occur on a slave server, other slave servers take over the job currently being executed, enabling processing to continue.
System error
Public LAN network error
iSCSI network error
Figure 15.3 Procedure to resume tasks after an error occurs on a slave server
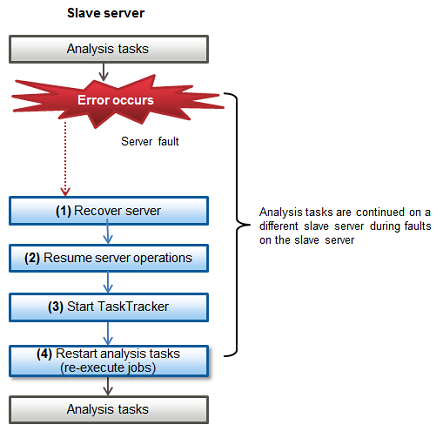
Refer to the system log of the relevant slave server. Investigate and remove the cause of the error.
If a serious fault occurs that cannot be resolved solely by referring to the system log and restarting the slave server, recover the slave server.
Refer to "14.2.1.2 Restoring a Slave Server" for information on the procedure to restore a slave server.
Point
Prior to performing a restore, a backup of the slave server must be created when it is running normally.
Refer to "14.1.2.2 Backing Up a Slave Server" for information on the procedure to back up a slave server.
After the slave server has fully recovered, restart the slave server that was recovered.
After the slave server has been recovered and operations have resumed, execute the bdpp_start command from the master server and restart Hadoop on the slave server where the error occurred.
Refer to "A.14 bdpp_start" for information on starting Hadoop.
Note
If the bdpp_start command is executed to restart Hadoop on some slave servers, the message "bdpp:WARN:001" will be output, but note that this does not indicate a problem with restarting Hadoop on the slave servers.
After the slave server has fully recovered, execute jobs as required and resume tasks.