This section describes the server configurations and server types using this product.
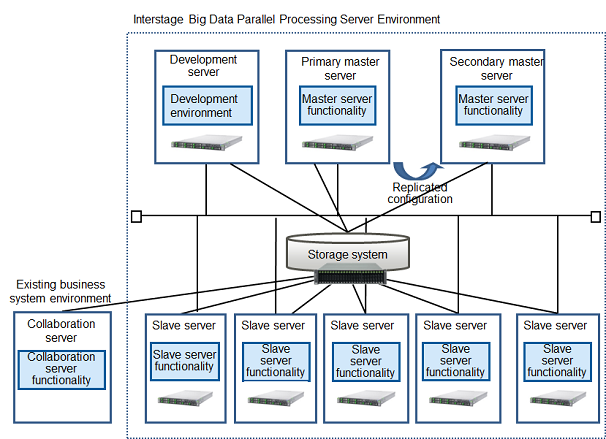
A master server splits large data files into blocks and makes files (distributed file system), and centrally manages those file names and storage locations.
A master server can also receive requests to execute analysis processing application jobs, and cause parallel distributed processing on slave servers.
Replication of the master server is possible with this product.
Install the master server feature of this product on the master server.
Analysis processing can be performed in a short amount of time because the data file, split into blocks by the master server, is processed using parallel distributed processing on multiple slave servers.
Furthermore, the data that is split into blocks is stored in a high-reliability system.
This product's slave server functionality is installed at each slave server.
The development server is a server where Pig or Hive is installed and executed. They enable easy development of applications that perform parallel distribution (MapReduce).
This product's development server functionality is installed at the development server.
With Apache Hadoop, it was necessary to register in HDFS (the distributed file system for Hadoop) in order to analyze. Analysis can be performed by directly transferring the large amount of data on the business system to the DFS (Distributed File System), which is built on the high reliability storage system that is one of the main features of this product, from the collaboration server using the Linux standard file interface.
Installation of an existing data backup system on the collaboration server enables easy use of data backups.
This product's collaboration server functionality is installed at the collaboration server.
Note
Make sure that the data stored in the DFS using data transfer is the data that is to be analyzed using Hadoop. Other data cannot be stored.