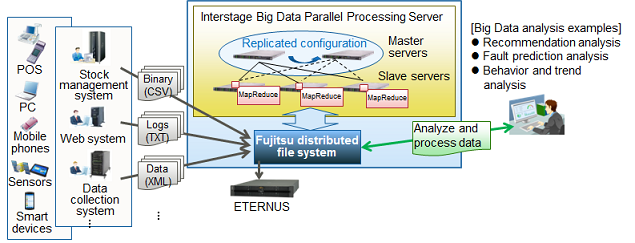
The Interstage Big Data Parallel Processing Server uses the industry standard for Big Data processing, "Apache Hadoop", with Fujitsu proprietary technology incorporated.
In recent years, not only are massive amounts of data collected from sensors and smart devices, such as smart phones and tablets, but also the formats and structures are many and varied, and these are continuously increasing. This is known as Big Data, and it is increasingly being adopted, particularly by leading corporations, and is gathering a lot of attention, because it is providing unprecedented business advantages.
This product vastly improves reliability and processing performance, decreases system installation time, reduces the burden in operation management, and supports Big Data in enterprise systems.
Big Data has the following features:
Massive size of data
Enormous amounts of data, with data sizes reaching the terabyte to petabyte range
Variety of data
Data in a variety of formats: structured data (database data), non-structured data (sensor information, text data such as access log information), semi-structured data (data having the qualities of both structured data and non-structured data)
Data frequently generated
Continuous generation of new data from sensors and similar
Need to use data in real-time
Performing analysis in a short amount of time and using the data in real-time
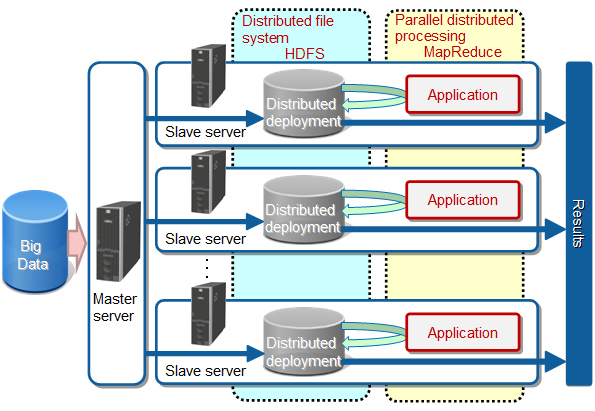
Apache Hadoop (*1) is widely used and is the world standard for applications that can resolve the above Items 1 and 2 in Big Data processing (processing data of massive size, and variety of data).
*1 Apache Hadoop: Open source software, developed by Apache Software Foundation (ASF), that efficiently performs distribution and parallel processing of Big Data
Apache Hadoop technology splits Big Data, distributes it to tens or tens of thousands of servers, and performs parallel processing, thereby performing batch processing of Big Data in a small amount of time. This technology has the following features:
Low cost
Economical systems can be built by using large numbers of comparatively cheap servers that perform parallel processing.
High availability
Processing can continue even if two machines stop simultaneously because the split data is distributed to three or more of the servers (slave servers) that execute parallel processing.
Scalability
Systems can be scaled-out easily by adding slave servers.
Variety of data processes
Parallel analysis processing applications (MapReduce applications) can be developed for a range of uses, from simple analysis such as character string searches through to high-level analysis logic for image analysis or similar, and can process data in a variety of formats.