When GLS is used in a cluster configuration, if you shut down the communication target completely and reboot another cluster node, the other node determines that all networks have failed and a node failure occurs.
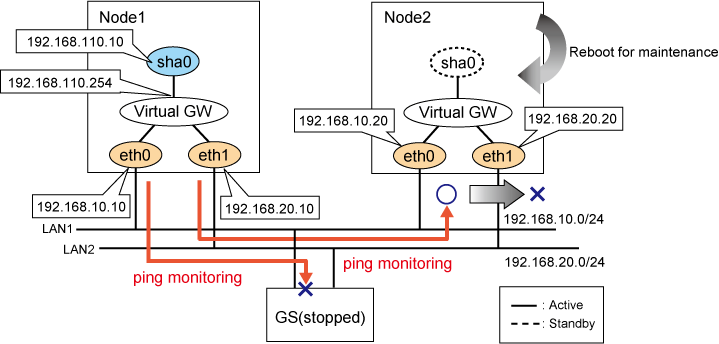
Perform maintenance procedure while the communication target is stopped (rebooting, etc.) using one of the following procedures.
Maintenance procedure1
Stop the cluster of both nodes (node1 and node2)
Perform maintenance (rebooting, etc.) on the node to be serviced.
Boot the cluster on both nodes (node1 and node2)
Maintenance procedure2
Check that all GLS resource states are Offline or Standby on the standby node to be serviced. If there is a GLS resource on the maintenance side, check that the GLS resource has failed over to the other node (node2).
Adjust the GLS settings so that any network errors will not be detected by the active node.
# /opt/FJSVhanet/usr/sbin/hanetobserv param -f no
# /opt/FJSVhanet/usr/sbin/hanetobserv print
interval(s) = 5 sec
times(c) = 5 times
idle(p) = 60 sec
repair_time(b) = 5 sec
fail over mode(f) = NO |
Stop the standby node's cluster.
Perform maintenance on the standby node.
After completing the maintenance, check that a ping can be sent to the physical IP address of the node on which you have performed maintenance. Check the settings so that a network error can be detected.
# ping 192.168.10.20
# ping 192.168.20.20
# /opt/FJSVhanet/usr/sbin/hanetobserv param -f yes
# /opt/FJSVhanet/usr/sbin/hanetobserv print
interval(s) = 5 sec
times(c) = 5 times
idle(p) = 60 sec
repair_time(b) = 5 sec
fail over mode(f) = YES |
Confirmation method
Check the maintenance procedure performed while the communication target is stopped.