Begin starting the servers with the master server (primary) and then the master server (secondary), then start the slave servers and the development server. With the collaboration server, the DFS can be mounted after the master server has completed startup.
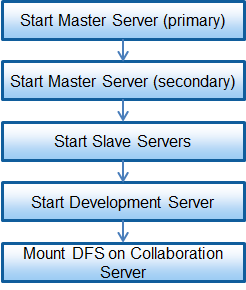
The Hadoop of the Interstage Big Data Parallel Processing Server can be started once the master server and all of the slave servers have been started.
Use the bdpp_start command to start the Hadoop of the Interstage Big Data Parallel Processing Server.
Refer to "A.1.11 bdpp_start" for details of the bdpp_start command.
Note
The master server uses an HA cluster configuration, so the Apache Hadoop "JobTracker" on the master server cannot be started or stopped directly.
To start or stop the Hadoop of the Interstage Big Data Parallel Processing Server, the bdpp_start or bdpp_stop commands must be used.
Refer to the Hadoop Project Top Page (http://hadoop.apache.org/) for details on how to use Apache Hadoop.
When Interstage Big Data Parallel Processing Server is started, the following Hadoop processes start:
Master server
JobTracker
Slave server
TaskTracker