The system configuration design items shown below are required when building this product.
Design the server configuration
System redundancy configuration design
DFS file system design
Design the server configuration
This product scales out slave servers, and through the addition of slave servers, scalability is improved. It is recommended to make an estimate of how many servers are required by performing prototype tests before using the system in business, as the time required for processing depends on such factors as the number of slave servers used, the Hadoop applications, and the volume and characteristics of data to be processed. On top of this, determine the maximum number of slave servers, including any future expansion.
System redundancy configuration design
A system having higher reliability can be built by installing related products in addition to this product.
The systems that can be built using this product and related products are as follows.
Supported configuration | Supported server type | Means of support |
|---|---|---|
Server repliation | Master server | Supported with just this product HA cluster configuration 1:1 active standby |
Cluster interface repliation / non-repliation | Master server | Supported with just this product |
Public LAN repliation / non-repliation | Master server Slave server | Supported with just this product Master server: NIC switching method (logical IP address inheritance) Slave server: NIC switching method (physical IP address inheritance) |
Storage system connection repliation / non-repliation | Master server Slave server Development server Collaboration server | Supported if a related product, the " ETERNUS Multipath Driver ", is installed |
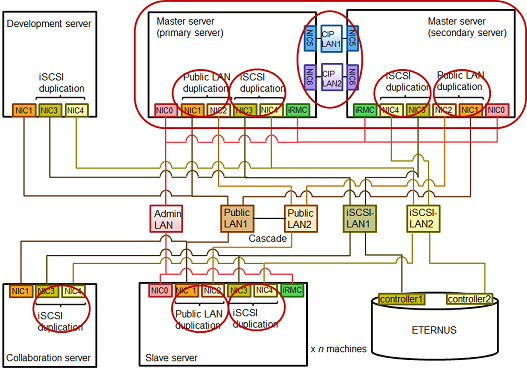
Design the system configuration by selecting from the "Redundancy configuration targets" (parts outlined in red) the configurations that suit the customer requirements.
Figure 2.1 Redundancy configuration targets
DFS file system design
A file system design, which should be investigated in advance, is required for using a DFS file system.
Refer to "D.1 File System Design" in "Appendix D DFS Environment Construction" for information on file system design.
This manual uses the following configuration as an example to explain file system configurations:
| /dev/disk/by-id/scsi-1FUJITSU_300000370105 |
| /dev/disk/by-id/scsi-1FUJITSU_300000370106 |
| /dev/disk/by-id/scsi-1FUJITSU_300000370107 |
| master1 |
| master2 |
Point
A by-id name generated by the udev function is used for shared disk device names. The by-id name is a device name generated from the unique identification information set in the hard disk.
Use of the by-id names enables each server to always use the same device name to access a specific disk.
Check whether each server can recognize the disk partitions having by-id names.
Red Hat Enterprise Linux 5
# udevinfo -q symlink -n /dev/sdb <Enter> disk/by-id/scsi-1FUJITSU_300000370105 # udevinfo -q symlink -n /dev/sdc <Enter> disk/by-id/scsi-1FUJITSU_300000370106 # udevinfo -q symlink -n /dev/sdd <Enter> disk/by-id/scsi-1FUJITSU_300000370107 # udevinfo -q symlink -n /dev/sde <Enter> disk/by-id/scsi-1FUJITSU_300000370108
Red Hat Enterprise Linux 6
# udevadm info -q symlink -n /dev/sdb <Enter> block/8:48 disk/by-id/ scsi-1FUJITSU_300000370105 # udevadm info -q symlink -n /dev/sdc <Enter> block/8:48 disk /by-id/ scsi-1FUJITSU_300000370106 # udevadm info -q symlink -n /dev/sdd <Enter> block/8:48 disk /by-id/ scsi-1FUJITSU_300000370107 # udevadm info -q symlink -n /dev/sde <Enter> block/8:48 disk /by-id/ scsi-1FUJITSU_300000370108