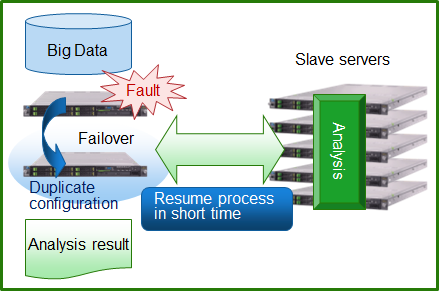
When a fault occurs in the master server that manages the entire system under "Apache Hadoop", "HDFS" cannot be used while the cause of the fault is being removed and the master server is being restored. This causes the stoppage time to extend over a long period (single point of failure). With this product, Fujitsu HA cluster technology provides duplicated master server operation, thus avoiding a single point of failure and achieving high reliability with restarts completed in a small timeframe.