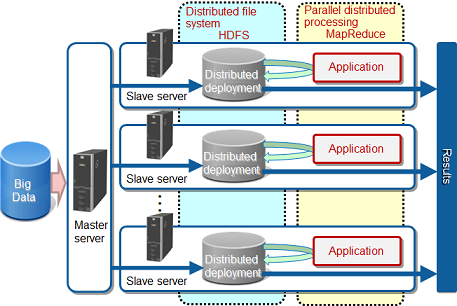
Apache Hadoop technology splits Big Data, distributes it to tens or tens of thousands of servers, and performs parallel processing, thereby performing batch processing of Big Data in a small amount of time. This technology has the following features:
Low cost
Economical systems can be built by using large numbers of comparatively cheap servers that perform parallel processing.
High availability
Processing can continue even if two machines stop simultaneously because the split data is distributed to three or more of the servers (slave servers) that execute parallel processing
Scalability
Systems can be scaled-out easily by adding slave servers.
Parallel analysis processing applications (MapReduce applications) can be developed for a range of uses, from simple analysis such as character string searches through to high-level analysis logic for image analysis or similar, and can process data in a variety of formats.