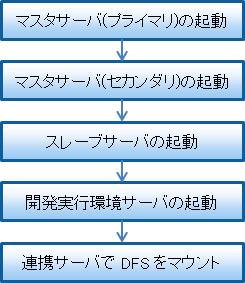
マスタサーバ(プライマリ)、マスターサーバ(セカンダリ)の順でサーバの起動を行ったあとで、スレーブサーバ、および開発実行環境サーバをそれぞれ起動します。連携サーバについては、マスタサーバの起動が完了したのちに、DFS のマウントが可能となります。
マスタサーバおよびすべてのスレーブサーバが起動した段階で、Interstage Big Data Parallel Processing Server の Hadoop の起動が可能となります。
Interstage Big Data Parallel Processing Server の Hadoop の起動は、“bdpp_start コマンド”で行います。
“bdpp_start コマンド”の詳細は、「A.1.11 bdpp_start」を参照してください。
注意
マスタサーバは HA クラスタ構成となっており、マスタサーバ上の Apache Hadoop の”JobTracker”を直接、起動または停止することはできません。
Interstage Big Data Parallel Processing Server の Hadoop の起動または停止する場合は必ず、“bdpp_start コマンド”または“bdpp_stop コマンド”を使用してください。
Apache Hadoop の利用方法については、「Hadoop プロジェクトトップページ http://hadoop.apache.org/」を参照してください。
Interstage Big Data Parallel Processing Server の起動を行うと、次に示す Hadoop のプロセスが起動されます。
マスタサーバ
JobTracker
スレーブサーバ
TaskTracker