その他の機能として、以下があります。
データ登録
辞書の複写
問い合わせごとのチューニング
HTTPトンネリング
Visualminer
データ登録
Navigatorデータ登録ツールを利用して、表計算ソフトなどで作成したCSV形式のデータを、サーバ上のデータベースに格納することができます。
辞書の複写
辞書の退避、削除、および復元コマンドを使用することにより、サーバ上で辞書の複写を行うことができます。これにより、同一サーバや別サーバの複数の辞書を定期的に置き換えることもできます。
問い合わせごとのチューニング
問い合わせ実行時の性能オプションなどを使用することで、問い合わせごとに性能をチューニングすることができます。
このようにして適切にチューニングをした問い合わせファイルを作成しておくことにより、次回からより高度にチューニングされた問い合わせファイルを実行することができます。
マスタ型・全値型・カテゴリ型管理ポイントに対して、管理ポイントごとにIN構文の生成/非生成を指定できます。
数値項目での、範囲型の管理ポイントに対して、管理ポイントごとにCASE式の使用/非使用を指定できます。なお、使用しているのDBMSがCASE式をサポートしている必要があります。
大規模なマスタテーブルを使用する問い合わせなど、サーバ上でメモリが不足して、エラーが発生したり、処理に時間がかかる場合に、テーブルの結合の処理方法や階層関係にある管理ポイントの処理方法を変更することで、問い合わせが可能になったり、処理時間が改善されることがあります。
OracleのSQLのチューニングパラメタに対するヒントを指定できます。
HTTPトンネリング
HTTPトンネリングを利用することにより、イントラネット内でファイアウォールを介したNavigatorの運用ができます。
Visualminer
Visualminerは、問い合わせ結果を以下のように平行座標上にビジュアルに表示します。
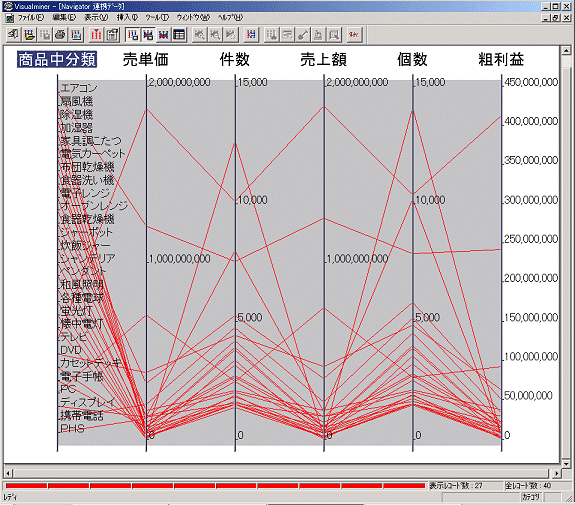
この平行座標上で、各軸に対応した項目の選択範囲を、マウスによる簡単な操作で絞り込んでいくことにより、特定の切り口で情報の傾向や特徴を浮き彫りにしていくことができます。
また、軸ごとの範囲絞り込み、軸の削除、カテゴリごとの色分け、ラベルの表示順序変更など、分析者が理解し、新しい発想をしやすくするための編集をワンタッチで行うことができます。
大量の項目で構成されるデータから、目的とするデータを検索する場合、そのデータの内容を十分に理解していることが必要です。例えば、どんな項目があるか、各項目の値はどのような値なのか、といった事前知識が必要になります。
Visualminerでは、自動的にデータ全体の概観を視覚的に表現し、各データ項目の分布状況をイメージできるようにしています。したがって、項目ごとの詳細な事前知識は必要ありません。
さらに、通常の検索では条件を具体化する必要があります。多くの場合、検索の目的は、非常にあいまいな条件から進めます。
例えば、「駅に近いアパート」とか「若い女性」といった条件です。検索を行う場合、これらのあいまいな条件を「駅から10分以内のアパート」とか、「22才以下の女性」といった具体的な条件に変えなければなりません。
Visualminerでは、このようなあいまいな条件を「フィルタリング」というマウス操作で簡単に指定することができます。これにより、発想を阻害することなく、探索的なデータの検索ができます。