現在、企業や自治体・公共団体などの情報システムは、多数の業務サーバから構築され、日々新しい情報が蓄積されています。
しかし、組織全体での情報の統合は容易ではなく、情報が蓄積されているにもかかわらず、すべてを有効に活用できないという問題を抱えています。
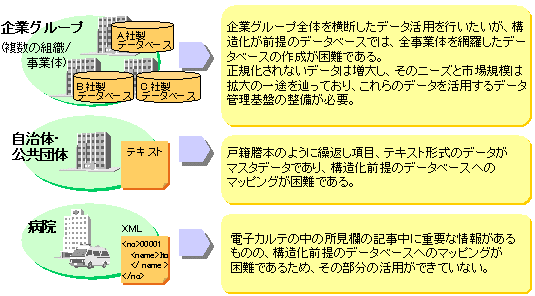
たとえば、同一企業グループの中でも、各事業体はそれぞれに適したデータの正規化を行い、データベースに格納します。そのため、グループ全体で情報を総合的に活用しようとすると、使用しているデータベース製品の種別やスキーマ構造の相違があり、活用は困難です。
一方で、正規化されないデータは増大し、そのニーズと市場規模は拡大の一途を辿っています。そのため、これらのデータを活用するデータ管理基盤の整備が必要とされてきています。
また、インターネットビジネス環境では、単なる数値や文字列といった形式のデータだけでなく、さまざまな形式の文書データの取扱いが重要になってきています。その中でも特にXML文書は、多くのビジネスシーンで利用されるようになってきました。
しかし、これらのデータは正規化が容易ではなく、業務において有効利用しきれていないという問題があります。
図1.1 現在のビジネスシーンと問題点
今、さまざまな商用RDBMS(Relational DataBase Management System)ベンダが、XML文書を扱うための機能強化を行っています。しかし、可変長のデータや可変繰返し項目への対応、およびインデックスの対応を考慮したデータベースの構造設計は困難です。
このように、RDBMSで管理しきれない情報や全社レベルで正規化できない情報を活用する仕組みが求められています。
これらの問題を解決する革新的な技術が「Shunsaku」です。
Shunsakuは、膨大なコストや時間をかけるこれまでのシステム構築とは異なり、シンプルでわかりやすい設計/運用方式と堅牢なデータ管理により、多様なデータを企業活動でリアルタイムに活用できるXML型データベースエンジンです。
データを「あるがままに格納し、思うがままに検索する」ことができることにより、「必要な情報を」、「必要なときに、迅速かつ的確に活用」できる仕組みを提供しています。
Shunsakuは、XML文書を検索対象にし、今までのRDBMSでのシステム構築が困難であった可変長、可変繰返し項目への対応を実現しています。
また、データそのものを直接、インデックスを使わずに高速に検索する革新的な技術を採用しています。
Shunsakuは、XML文書ならば、テキストファイルでもRDBMSに格納されているデータでも、検索対象のデータとして扱うことができます。小規模のテキストデータから大規模なデータベースシステム上に存在するテキストデータまで、さらに、既存のRDBMSでは取扱いが困難だったデータまでも、高い検索性能を発揮するデータ検索システムです。
また、新規業務の追加も新しい業務用アプリケーションを用意するだけで柔軟に対応でき、将来的な業務拡張性にも優れています。
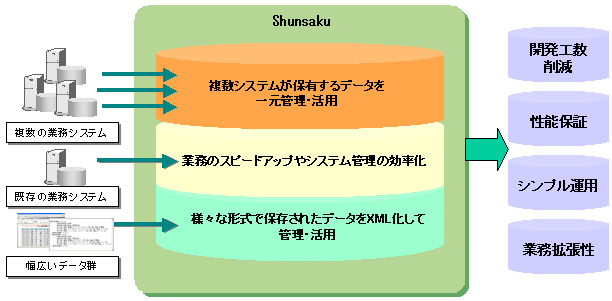
Shunsakuを導入することにより、複数の業務システムが保有するデータを一元管理・活用し、業務のスピードアップやシステム管理の効率化を図ることができます。そして、今までよりも柔軟かつ高速なデータ活用が可能となるビジネスシステムを実現するとともに、開発期間の短縮と投資コストの削減、性能保証、シンプル運用および業務拡張性を実現します。
図1.2 Shunsakuとは
Shunsakuは、以下の技術を採用することにより、XML文書を高速に検索することを実現しています。
高速検索アルゴリズム
高速検索アルゴリズムとは、検索条件が複数あっても、一定のスピードで検索を実行する技術です。
1つの条件でも3つの条件でも、理論的にほぼ同じ時間で検索することができます。
ハイトラフィック技術
アプリケーションからの複数の検索要求を一体化して、一度に処理する技術です。複数の検索条件と比較しながらデータを読み進め、読み終えたときにはすべての要求に回答が用意されています。
たとえば、1件の検索要求で複数の検索項目の場合と、複数の検索要求が各1項目の検索項目の場合でも、検索時間は理論的にほぼ同じになります。
並列検索技術
検索エンジンを複数稼働させ、ハードウェアリソースを有効活用して、並列に検索を行います。
ハードウェアリソースを増設することで、簡単に検索時間の短縮を行うことができます。