

| Interstage Shunsaku Data Manager Operator's Guide - Microsoft(R) Windows(R) 2000/ Microsoft(R) Windows Server(TM) 2003 - - UNIX - |
|
Contents
Index
|
| Chapter 8 HA Functions | > 8.1 Overview of Shunsaku's HA Functions |
A failover function for director servers can be used with cluster systems, in preparation for unexpected circumstances such as hardware faults or software error with director servers.
This section explains:
 What is the Failover Function for Director Servers?
What is the Failover Function for Director Servers?The failover function for director servers works by using cluster systems where, in addition to the server that is operating (hereafter referred to as the 'active server'), another server (hereafter referred to as the 'standby server') is prepared in case something goes wrong with the active server.
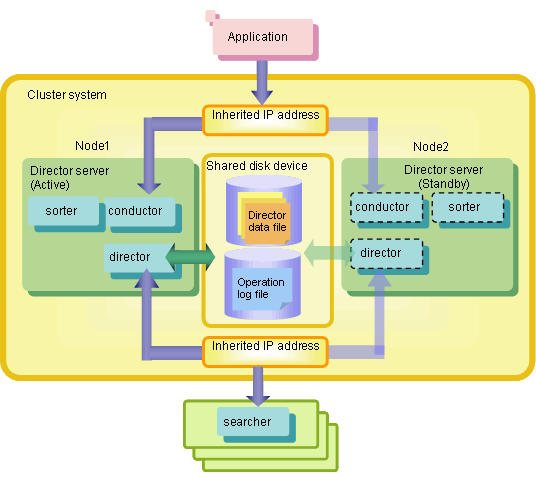
Using the failover function for director servers allows users to perform searches and updates to Shunsaku without being aware of which server is the active server and which is the standby server.
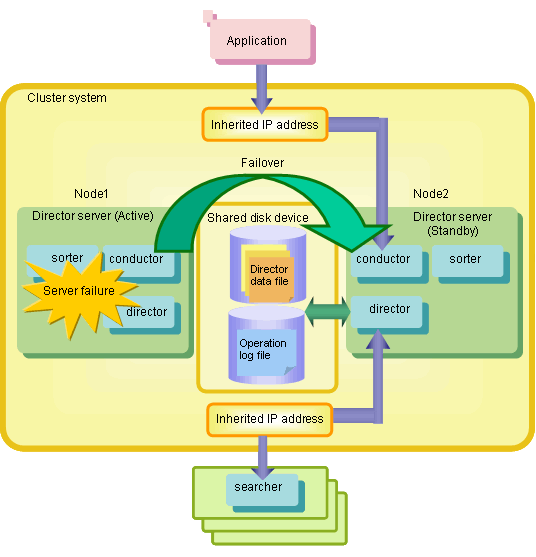
If something unexpected happens to the active server (such as a hardware fault or software error), the cluster system detects the error and performs a failover operation.
The failover operation minimizes system downtime by starting Shunsaku on the standby server and handing over control of jobs to the standby server. After jobs have been taken over, users can continue to perform searches and updates using Shunsaku in exactly the same way as before the server error occurred.
Additionally, because the server operating normally takes over the jobs from the failed server, the failure can be rectified without interrupting these jobs.
Cluster SystemThe failover function for director servers runs on the following cluster systems.



Using the HA functions requires knowledge of these cluster systems. Refer to the manuals for each cluster system for more information.
Failover Operation ConfigurationThe failover function for director servers can be used with the following operation configurations of cluster systems.
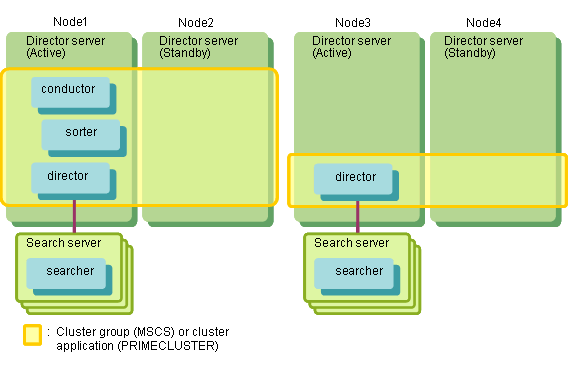
1:1 Active/Standby ConfigurationIn this operation configuration, there is one standby server for each active director server.
If an abnormality occurs with the active server, the cluster system fails over to the standby server, so jobs do not need to be interrupted.
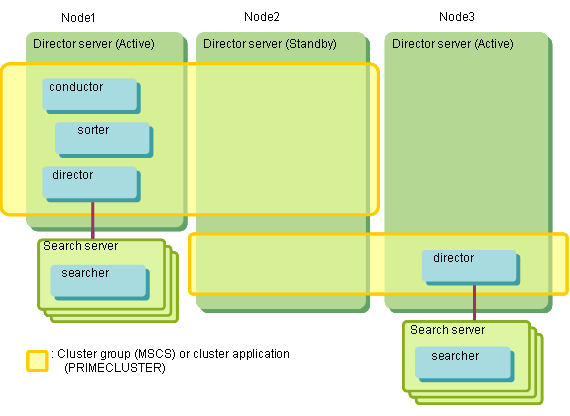
N:1 Active/Standby ConfigurationIn this operation configuration, there are multiple active servers for each standby server.
This operation configuration reduces the cost of standby servers because, unlike the 1:1 active/standby configuration, there is no need to prepare a standby server for each active server.
|
Contents
Index
|