

| Interstage Shunsaku Data Manager Operator's Guide - Microsoft(R) Windows(R) 2000/ Microsoft(R) Windows Server(TM) 2003 - - UNIX - |
|
Contents
Index
|
| Chapter 1 Overview |
Corporations, autonomous bodies, and public organizations currently use information systems consisting of multiple business servers which accumulate more and more information each day.
It is not easy to integrate the information of an entire corporation, and it is a recognized problem that corporations cannot make effective use of all the information they continue to accumulate.
For example, the various business sections of a single corporate group normalize the data they use and store it in databases. However, attempts to enable the group as a whole to use of all this data are hindered by the adoption of different database products and schema structures. To make use of all of the data, it must first be normalized and systems restructured. Otherwise, only some data can be used. The result is that the group as a whole cannot effectively use of all the various business data and customer information.
In addition, the handling of data in a variety of document formats, not just in simple numeric value and character string formats is becoming increasingly important in the Internet business environment. In particular, data in XML format is now used by many businesses. However, these data formats are not easy to normalize, and are problematic to make use of effectively in business.
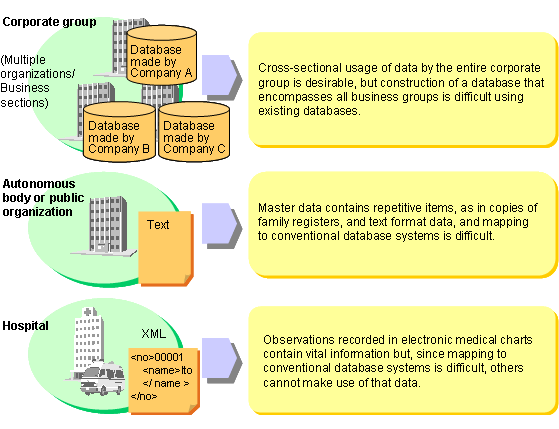
Various commercial RDBMS (Relational Database Management System) vendors now provide extended functions that handle data in XML format. However, it is difficult to design database structures for dealing with variable-length data or variable occurrence items and indexes.
Accordingly, a mechanism is required for making use of information that cannot be managed by a RDBMS or that cannot be normalized at the company-wide level. Shunsaku is the revolutionary technology that solves these problems.
 What is Shunsaku?
What is Shunsaku?Shunsaku is an XML format database engine that can utilize different format of data in business activity in a real time, which is different from the systems so far. This is because Shunsaku system is easily and simply to design and operate.
Shunsaku provides a mechanism that required information can be utilized appropriately and immediately at the time it is needed because Shunsaku can 'store data as it is and performs customize searches'.
Shunsaku searches data that is in XML format, and manages the variable-length and variable occurrence items that are problematic for the system structures of conventional RDBMS.
Shunsaku uses revolutionary technology that searches data, not indexes, directly, at high speeds.
Shunsaku can search data regardless of whether it is XML, text file data, or data stored in a RDBMS. The Shunsaku high-level search functions search text data, ranging from small-scale text data to the text data held in large-scale database systems, as well as data that is difficult to search using conventional RDBMS.
Shunsaku also provides superior support for future business expansion, since it can flexibly manage the addition of new businesses and new business applications.
Installation of Shunsaku enables users to manage and utilize the data held in multiple business systems from one base, thus making business faster and system management more efficient. Shunsaku makes possible business systems that use data more flexibly and quickly than ever before. Shunsaku also shortens development time, reduces investment costs, and provides performance guarantees, simple operations, and scope for business expansion.
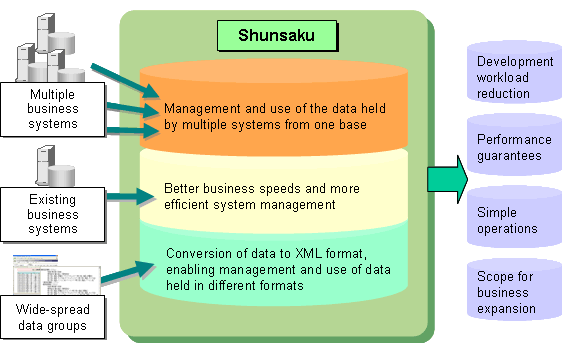
Shunsaku TechnologyShunsaku uses the following technology to enable high-speed searches of data in XML format:
High-speed search algorithm technology executes searches at a fixed speed even if there are multiple search conditions. Searches take about the same amount of time logically regardless of whether there is one condition or three conditions.
High-volume traffic technology bundles together multiple search requests from applications and processes them at the same time. This technology compares multiple search conditions while it reads through the data, and prepares the answers to all the requests by the time reading is finished. For example, the search time is logically about the same for one search request containing multiple search items as it is for multiple search requests each containing one search item.
Parallel search technology runs multiple search engines to use hardware resources efficiently and run searches in parallel. The search time can be easily reduced simply by increasing the hardware resources.
|
Contents
Index
|