2021年 7月 現在
FUJITSU Software
Big Data Integration Server V1a (V1.3.0)
本商品は、リアルタイムなデータ活用を実現するための収集・データ管理・検索機能を提供し、大量データ/ストリームデータのリアルタイムな活用を支援する商品です。
自社の独自技術により、情報系システムにおける容易な業務拡張および高速な加工・検索を実現します。
本商品を利用することで、「スキーマレス/マートレス」と高速な加工により、大量データを検索する準備がすぐにできます。また、準備した大量データを高速に検索・分析できます。
本商品は、サブスクリプションライセンスを提供しています。
適応機種 概要
- スキーマレス加工サーバ/インメモリ検索サーバ/インメモリ検索拡張サーバ/ディスク検索サーバ/インメモリ検索クライアント
PRIMEQUEST 3000/2000シリーズ / PRIMEQUEST 1000シリーズ / PRIMERGY / マルチベンダーサーバ・クライアント / FUJITSU Hybrid IT Service FJcloud-O IaaS / FUJITSU Cloud Service S5 / FUJITSU Hybrid IT Service for Microsoft Azure 仮想マシン / パブリッククラウド
- 収集エージェント/収集サーバ/マスタサーバ/スレーブサーバ/開発実行環境サーバ
PRIMEQUEST 3000/2000シリーズ / PRIMEQUEST 1000シリーズ / PRIMERGY / マルチベンダーサーバ・クライアント / FUJITSU Hybrid IT Service FJcloud-O IaaS / FUJITSU Cloud Service S5 / FUJITSU Hybrid IT Service for Microsoft Azure 仮想マシン / パブリッククラウド
適応OS 概要
- スキーマレス加工サーバ/インメモリ検索サーバ/インメモリ検索拡張サーバ/ディスク検索サーバ/インメモリ検索クライアント
Red Hat Enterprise Linux 8 (for Intel64) / Red Hat Enterprise Linux 7 (for Intel64)
- 収集エージェント/収集サーバ/マスタサーバ/スレーブサーバ/開発実行環境サーバ
Red Hat Enterprise Linux 8 (for Intel64) / Red Hat Enterprise Linux 7 (for Intel64)
機能説明
1. スキーマレス加工
自社の独自技術により、データの構造(スキーマ)を意識せず、そのままの形式で収集したデータを、使いたい項目だけを抽出・加工することで、検索用のデータの準備が容易にできます。
スキーマレス加工では、抽出、連結、集計、ソートの機能があります。
これらは組合せが自由で、データ処理に必要な条件を指定して実行するだけです。
2. インメモリ検索
インメモリ検索は、スキーマレス加工によって準備されたデータのうち、サマリデータや直近データなどの重要なデータをインメモリに格納し、インメモリ検索API(JavaまたはC)を使用することで、格納データの絞り込み、ソート/集計を自社の独自技術により高速にできます。
絞り込みやソート/集計の高速化によってマートを作成する必要がなくなり(マートレス)、すぐに検索業務を開始できるようになります。
3. ディスク検索
ディスク上の大量データのすべてをキーワードで検索できます。また、絞り込み、ソート/集計、項目編集、結合が可能なため、大量データを要約(サマリ)して抽出もできます。
ディスク検索のコマンドまたはC APIを使用して検索実行アプリケーションを作成することで、自社の独自技術により、大量データから高速にデータを抽出できます。
4. ログ収集
ログ収集は、様々なデバイス、アプリケーション、ミドルウエアから出力されるログを効率的に収集します。
収集エージェントが集めたデータを収集サーバへ転送します。収集サーバはスキーマレス加工や並列分散処理が入力データとして扱えるように、受信したデータをメッセージングに格納します。
本機能では、散在するログを収集・加工・集約するオープンソース・ソフトウェア「Fluentd」の機能を提供しています。
5. メッセージング
ログ収集等で外部から集めてきたデータを一時的にメモリに保持(キューイング)し、スキーマレス加工等を使用したデータ処理が入力データとして利用できるようにします。
メッセージングを使用して収集・加工等の異なるデータ処理間のデータ受渡しを仲介することで、全体のレスポンス・スループット性能を最適化できる等の利点があります。
システム間のデータの受け渡しを仲介し、データを一時的に保持(キューイング)するミドルウェアです。
本機能では、リアルタイムなデータ連携パイプラインを実現するオープンソース・ソフトウェア「Apache Kafka」の機能を提供しています。
6. 並列分散処理
処理を数十〜数千台のサーバで分散処理することによって、長時間かかっても処理できなかった大量のデータや繰り返しの多い複雑な処理を、短時間で処理することができます。(サーバを1台から16台に増やすことで、処理時間が242分から17分に短縮した事例があります)
本機能では、大量データの効率的な分散・並列処理を行うオープンソース・ソフトウェア「Apache Hadoop」、およびメモリ上で複雑な処理を高速化できる「Apache Spark」の機能を提供しています。
7. 高信頼・高可用性
(1)インメモリ検索拡張サーバの縮退機能
運用中にインメモリ検索拡張サーバ上の検索エンジンであるsearcherに異常が発生した場合、データを残りの正常なsearcherに自動的に配布するので、そのまま運用を継続できます。これを縮退機能といいます。
インメモリ検索拡張サーバの縮退機能により、業務を継続することが可能です。
(2)インメモリ検索拡張サーバのフェイルオーバ機能
異常が発生したインメモリ検索拡張サーバの処理を代替させるサーバを用意し、代替searcherを事前に起動しておくことで、異常発生前と同等の性能で運用が再開できます。これをインメモリ検索拡張サーバのフェイルオーバ機能といいます。
(3)インメモリ検索サーバのフェイルオーバ
インメモリ検索サーバのフェイルオーバ機能は、運用中のサーバ(運用サーバ)とは別に、万一の場合に備えて待機しているサーバ(待機サーバ)を用意し、クラスタシステムを使用することで実現します。
インメモリ検索サーバのフェイルオーバにより、運用サーバに異常が発生した場合、即座に待機サーバに業務を引き継ぐことにより、システムのダウンタイムが短縮できます。
(4)マスタサーバのフェイルオーバ
並列分散処理機能では、マスタサーバを二重化構成(1:1運用待機型の HA クラスタ構成)にして運用できます。
マスタサーバのフェイルオーバにより、運用サーバに異常が発生した場合、即座に待機サーバに業務を引き継ぐことにより、システムのダウンタイムが短縮できます。
(5)スレーブサーバの縮退機能
並列分散処理機能では、複数台のスレーブサーバで構成して運用します。スレーブサーバで異常が発生した場合、残りの正常なスレーブサーバで処理を引き継ぐ、縮退機能があります。
スレーブサーバの縮退機能により、業務を継続することが可能です。
8. データの最適化
検索および更新処理によっては、データ量が偏ったり、無駄な領域が増えたりする場合があり、それが性能劣化の原因になることがあります。
そのような場合に対して、インメモリ検索にはデータを最適化するための機能を備えています。
(1) インメモリ検索用データの再配置
データの削除やインメモリ検索拡張サーバの増設または縮退などにより、インメモリ検索拡張サーバごとのデータ量やインメモリ検索用データファイルのデータ量に偏りが大きくなった場合は、インメモリ検索用データの再配置が必要になります。
インメモリ検索用データを再配置することにより、インメモリ検索拡張サーバごとのデータ量の偏りを解消することができます。
(2) インメモリ検索用データのファイルの最適化
インメモリ検索用データの削除や更新処理が大量に発生した場合に、インメモリ検索用データのファイルの中に無駄な領域が増え、検索性能の劣化につながることがあります。
その場合、インメモリ検索用データのファイルの最適化を行います。
9. インメモリ検索のモニタリング
インメモリ検索では、インメモリ検索の運用・設定情報や各プロセスの状態をモニタリングできます。
モニタリングできる情報は、運用情報、コネクション情報および設定情報(動作環境)です。
これらの情報はCSV形式で出力もできます。
10. データガバナンス
(1)メタデータ管理
データ管理者がスキーマ情報や業務上の意味、作成者等のデータを説明する情報(メタデータ)を付与することで、データ利用者が必要なデータを検索することができます。
また、収集データがどのように加工・変換されてデータが作成されたのかの来歴情報(リネージ)を記録することで、データ作成者以外でもデータの信頼性を確認することができ、高品質なデータを利用することができます。
本機能では、データ活用に不可欠なメタデータやリネージといった情報を蓄積できるオープンソース・ソフトウェアであるApache Atlasを提供します。
Apache Atlasは、メタデータの登録/参照、データの分類、および、データリネージの記録が実施できます。
また、セキュリティ管理機能(Apache Ranger)と連携することで、データ分類に基づいた、データアクセス制御/データのマスキングができます。
(2)セキュリティ管理
組織のアクセスルールに従ってアクセス権を列や行単位でマスキングすることで、機密情報を含むデータでも安全に活用することができます。
本機能では、セキュリティ管理のオープンソース・ソフトウェアであるApache Rangerを提供します。
Apache Rangerは、データに対する柔軟なアクセス制御が実施できます。
また、利用者のデータ操作を追跡するために監査ログを記録することができます。
システム/機能構成図
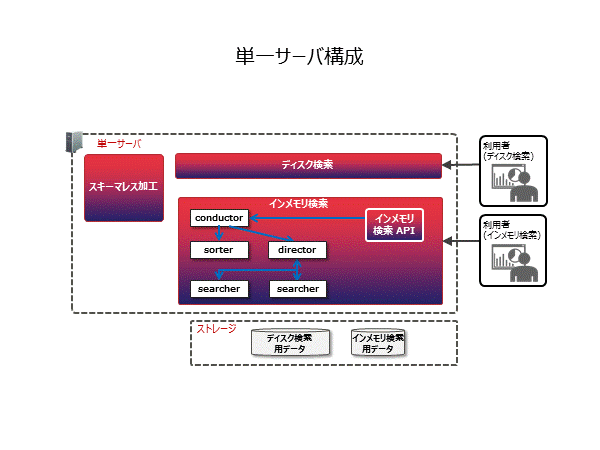
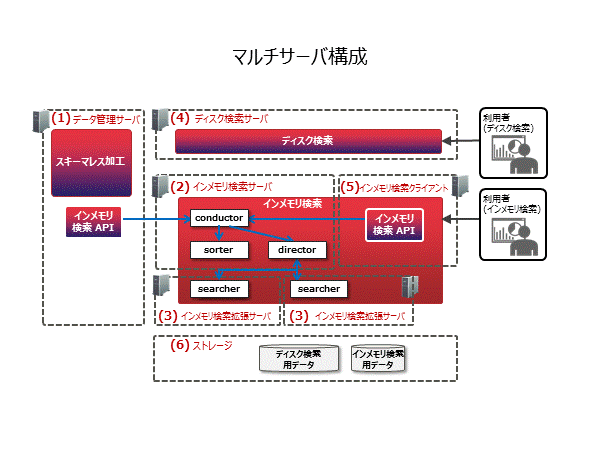
新規機能
V1.2.0からV1a (V1.3.0)の機能強化項目は、以下のとおりです。
EDI連携
EDI連携における個社形式・標準形式間のデータ変換定義作成を効率化するために、以下の機能を提供します。
(1)個社コードと標準コードの変換ルールを作成するコード変換定義作成機能
(2)データの格納・抽出用のWebアプリケーションインタフェース
標準添付品
- オンラインマニュアル
・Big Data Integration Server リリース情報
・Big Data Integration Server 利用ガイド
・Big Data Integration Server 移行ガイド
・Big Data Integration Server 収集編 ユーザーズガイド
・Big Data Integration Server 加工編 導入・運用ガイド
・Big Data Integration Server 加工編 リファレンス集
・Big Data Integration Server 加工編 メッセージ集
・Big Data Integration Server 加工編 QA集
・Big Data Integration Server 分散処理編 ユーザーズガイド
・Big Data Integration Server 検索編 導入・運用ガイド
・Big Data Integration Server 検索編 アプリケーション開発ガイド
・Big Data Integration Server 検索編 コマンドリファレンス
・Big Data Integration Server 検索編 Java API リファレンス
・Big Data Integration Server 検索編 C API リファレンス
・Big Data Integration Server 検索編 メッセージ集
・Big Data Integration Server 検索編 トラブルシューティング集
・Big Data Integration Server 検索編 用語集
・Big Data Integration Server EDI連携編 ユーザーズガイド
・FJQSS(資料採取ツール) ユーザーズガイド
商品体系
【メディア】
・Big Data Integration Server メディアパック(64bit) V1a (V1.3.0)
【サブスクリプションライセンス/サポート】
・Big Data Integration Server 標準プラン 基本 サブスクリプションライセンス/サポート (1テラバイト)V1a
・Big Data Integration Server 標準プラン 追加 サブスクリプションライセンス/サポート (1テラバイト)V1a
・Big Data Integration Server 大容量プラン 基本 サブスクリプションライセンス/サポート (10テラバイト)V1a
・Big Data Integration Server 大容量プラン 追加 サブスクリプションライセンス/サポート (1テラバイト)V1a
購入方法
1. メディアパックについて
メディアパックは、媒体(CD/DVD等)のみの提供です。使用権は許諾されておりませんので、別途、ライセンスを購入する必要があります。また、商品の導入にあたり、最低1本のメディアパックが必要です。バージョンアップ/レベルアップを目的に本メディアパックのみを手配することはできません。
2. サブスクリプションライセンス/サポートについて
サブスクリプションライセンス/サポートはソフトウェア使用権とサポートサービス(SupportDesk Standard)が一体となった月額サービス商品です。
サービスを購入することで、1カ月間分の使用権とサポートを得ることができる商品であるため、使用の開始、継続、中止等に当たっては、以下のことにご留意ください。
・1カ月間の使用権とサポートが有効です。
・継続して使用する場合は、サービス契約は自動的に更新されます。
・使用を中止する場合は、サービス期間満了の1カ月以上前に解約が必要です。
スキーマレス加工の入力データおよびインメモリ検索用データの総容量に応じてサブスクリプションライセンス/サポートが必要となります。
データ従量課金対象のデータ
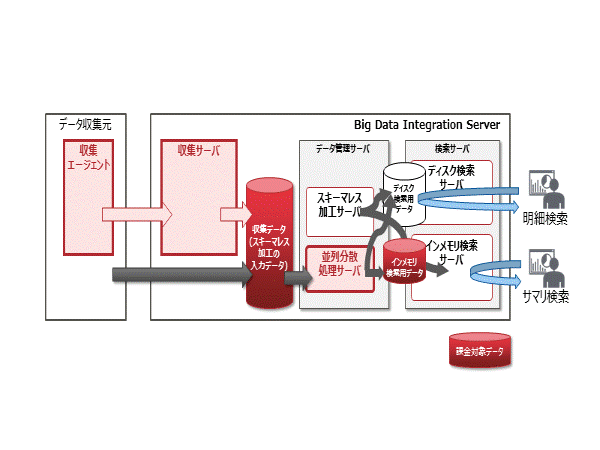
標準プランは現在および将来的に10テラバイト未満のデータを扱う中小規模システム向け、大容量プランは10テラバイト以上のデータを扱う大規模システム向けの月額サービス商品です。
詳細は富士通営業までお問い合わせください。
3. ダウングレード使用(旧バージョン または 旧レベル商品の使用)について
本商品のライセンスでは、ダウングレード使用(本商品の旧バージョン または 旧レベルを使用)する権利はありません。
対象のバージョン または レベルを使用する場合は、対象のバージョン または レベルに対応したライセンスをご購入ください。
4. V1からV1aへのアップグレードについて
V1からV1aへアップグレードする場合は、「Big Data Integration Server サブスクリプションライセンス/サポート V1a」へ契約変更が必要となります。
メディアパックの入手方法は、弊社 営業/SEにご相談ください。
5. クラスタシステムで運用する場合の購入方法
クラスタシステムで運用する場合、待機系ノードに対してライセンスの購入は不要です。
関連ソフト
1. スキーマレス加工またはディスク検索を使用するときに、アプリケーションを開発する場合
以下が必要です。
・gccおよびその他関連パッケージ(OS製品で提供されているコンパイラのみ)
2. 検索サーバ上でPostgreSQLを使用したファイル検索をする場合
ディスク検索において、PostgreSQLを導入してファイルを検索する場合は、以下が必要です。
・FUJITSU Software Enterprise Postgres Advanced Edition 12以降
・FUJITSU Software Enterprise Postgres Standard Edition 12以降
・FUJITSU Software Enterprise Postgres Community Edition 12以降
3. PostgreSQLを使用したファイル検索において、統合コマンドを使用して文字コード変換する場合
以下の製品が必要です。
・Interstage Charset Manager Standard Edition Agent V9(64bit)
4. インメモリ検索のJava APIを使用したアプリケーションを使用する場合
以下のいずれかが必要です。
・Java Runtime Environment 6
(Java Runtime Environment 6 Update 21 で動作確認済)
・Java Runtime Environment 7
(Java Runtime Environment 7 Update 14 で動作確認済)
・Java Runtime Environment 8
(Java Runtime Environment 8 Update 222 で動作確認済)
(注意)
- 基本ソフトウェアが動作保証するJava Runtime Environmentのバージョンを使用してください。
- Interstage Application Serverに同梱されているJava Runtime Environment、またはOracle製のJava Runtime Environmentのみ動作可能です。
Interstage Application Serverを使用する場合は、以下の製品を使用してください。
・Interstage Application Server Enterprise Edition V11以降
・Interstage Application Server Standard-J Edition V11以降
5. インメモリ検索のC APIを使用したアプリケーションを開発する場合
以下が必要です。
・gccおよびその他関連パッケージ(OS製品で提供されているコンパイラのみ)
6. クラスタ運用を行う場合
インメモリ検索サーバのフェイルオーバを利用する場合は、以下のどちらかのクラスタシステム用のソフトウェアが必要です。
・PRIMECLUSTER Enterprise Edition 4.3A40D以降
・PRIMECLUSTER HA Server 4.3A40D以降
7. 並列分散処理またはメッセージングのAPIを使用したアプリケーションを開発する場合
以下が必要です。
・Java Runtime Environment 8
(Java Runtime Environment 8 Update 222 で動作確認済)
(注意)
- 基本ソフトウェアが動作保証するJava Runtime Environmentのバージョンを使用してください。
Interstage Application Serverに同梱されているJavaを使用する場合は、以下の製品を使用してください。
・Interstage Application Server Enterprise Edition V12以降
・Interstage Application Server Standard-J Edition V12以降
8. メタデータ管理(Apache Hive)を使用する場合
Apache Hiveはメタストアデータベースとして使用可能なDerbyを同梱しています。
ただしDerbyをメタストアデータベースとして使用すると、複数クライアントがHiveに同時接続できなくなる等の制限が発生するため、Apache Hiveがメタストアデータベースとしてサポートしている以下のRDBMSを別途導入することを推奨します。
・FUJITSU Software Enterprise Postgres Advanced Edition 12
・FUJITSU Software Enterprise Postgres Standard Edition 12
・FUJITSU Software Enterprise Postgres Community Edition 12
9. セキュリティ管理(Ranger)を使用する場合
以下のRDBMS製品が必要です。
・FUJITSU Software Enterprise Postgres Advanced Edition 12
・FUJITSU Software Enterprise Postgres Standard Edition 12
・FUJITSU Software Enterprise Postgres Community Edition 12
10. データ分析基盤を構築する場合
以下の製品と組合せることで、データレイク(Big Data Integration Server)の様々なデータを統合して、お客様の分析業務を支援することができます。
・Data Analytics Smarter Hub V1.0.0
(注意)
Apache Hadoopの分散ファイルシステム(HDFS)を使用する場合
動作保証周辺機器
なし
留意事項
Intel64環境での動作について
本商品は、以下のディストリビューションの環境で、64 ビットモードで動作します。
- Red Hat Enterprise Linux 7 (for Intel64) ※Red Hat Enterprise Linux 7.2以降をサポート
- Red Hat Enterprise Linux 8 (for Intel64) ※Red Hat Enterprise Linux 8.1以降をサポート
関連URL
お客様向けURL
-
FUJITSU Software(Big Data Integration Server)
本商品の詳細は、以下のBig Data Integration Serverホームページを参照してください。
https://www.fujitsu.com/jp/software/bigdataintegserver/ -
FUJITSU Software(ソフトウェアの一覧表(システム構成図)と各種対応状況)
価格/型名の一覧(システム構成図)を提供しております。
https://www.fujitsu.com/jp/products/software/resources/condition/configuration/ -
FUJITSU Software(ライセンス)
富士通製ミドルウェア製品のサポート期間などの情報を提供しております。
https://www.fujitsu.com/jp/products/software/resources/condition/licensesupport/